
Спикер: Дмитрий Севальнев, основатель и евангелист сервиса «Пиксель Тулс»
2020 год ознаменовался не только эпидемией коронавируса, но и запуском нового алгоритма Яндекса - YATI (Yet Another Transformer with Improvements). Это технология, основанная на нейронных сетях, целью которой является оценка смысловой близости запроса пользователя и документа (веб-страницы).
По мнению специалистов Яндекса, это наиболее значимое событие для поиска за последние 10 лет (со времен запуска Матрикснета). Чтобы оценить всю важность этого запуска, можно вспомнить хотя бы тот факт, что до 2016 года до 95% слов на странице никак не учитывались Яндексом. Они просто игнорировались его алгоритмами.
Вот пример страницы, где цветом отмечены те слова, которые распознавались и учитывались поиском:

Регулярные изменения в поиске vs «Core Updates»
В целом 2020 год для Яндекса был очень мощным, а с октября по декабрь выдача находилась в режиме перманентного шторма.
Постоянное отслеживание апдейтов при помощи инструментов «Пиксель Тулс» позволяет различать некоторые регулярные изменения в поиске (их бывает 300-500 в год) и фундаментальные, касающиеся непосредственно алгоритма ранжирования, которые называются «Core».
Core Updates затрагивают большую долю поисковых запросов и часто связаны с переобучением формулы или новым подходом.
Поисковые системы по-разному информируют оптимизаторов о Core Updates. Так например Google, в котором за истекший год было 3 обновления основного алгоритма – в январе, мае и декабре, чётко предупреждал о начале запуска каждого из них, как правило, коротко в социальных сетях. Яндекс же, по факту, не анонсирует сами запуски, однако раскрывает больше деталей в статьях, посвященных апдейтам.
Как известно, Яндекс анонсировал свой новый алгоритм в ноябре. Однако, согласно измерениям «Пиксель Тулс», в этом месяце никаких изломов в динамике средних показателей выдачи Яндекса не было. Последний излом наблюдался 28-30 сентября 2020 года, что как раз и может свидетельствовать о запуске нового алгоритма.
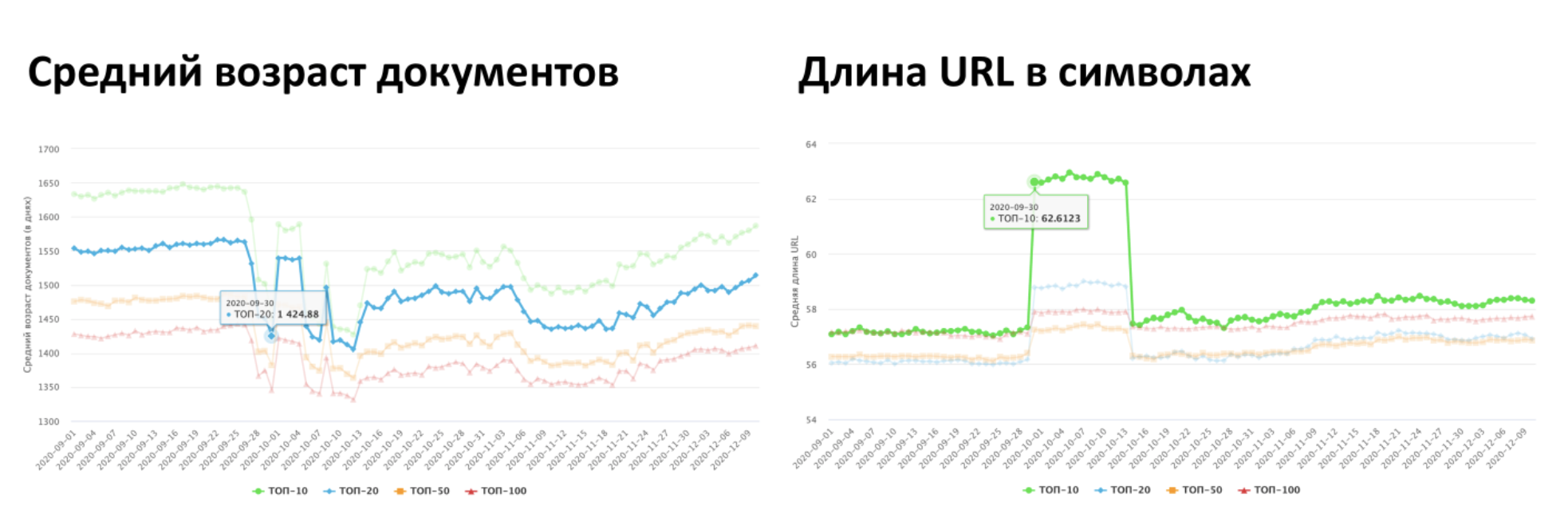
Вероятней всего, мы уже давно живем в реалиях нового алгоритма и говорить о его раскатке непосредственно в ноябре не приходится.
Использование нейронных сетей в алгоритмах ранжирования: основные вехи и примеры
Нейронные сети - это один из методов машинного обучения. А как известно, машинное обучение используется в поиске с начала 2000-х.
В 2009 году Яндекс анонсировал алгоритм Снежинск, который использовал технологию на основе машинного обучения MatrixNet.
В 2016 году Яндекс впервые публично заявил о применении нейросетей, представляя алгоритм Палех. Однако совершенно точно нейросети использовались Яндексом и ранее, в частности, в работе сервиса Яндекс.Переводчик. Тогда инженеры Яндекса честно заявили:
«Далекая, но чрезвычайно интересная цель поиска Яндекса состоит в том, чтобы получить на основе нейронных сетей модели, способные «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека».
Палех является одной из важных вех развития поиска Яндекса на пути к технологии YATI, также как и алгоритм Королёв, анонсированный в 2017 году.
Аналогичными вехами в развитии поиска Google можно обозначить разработку программного обеспечения Word2vec в 2013 году, а также запуск алгоритма BERT в 2019-м.
Нужно понимать, что нейронные сети ни в коем случае не пришли на замену всей поисковой формуле ранжирования. Факторы, вычисленные с помощью нейросетей, являются «одними из» в общей совокупности факторов, которые используются для построения итоговой формулы.
В результате на выдаче по запросу мы можем видеть как документы, релевантные по своей смысловой составляющей, так и документы, содержащие точное вхождение запроса:
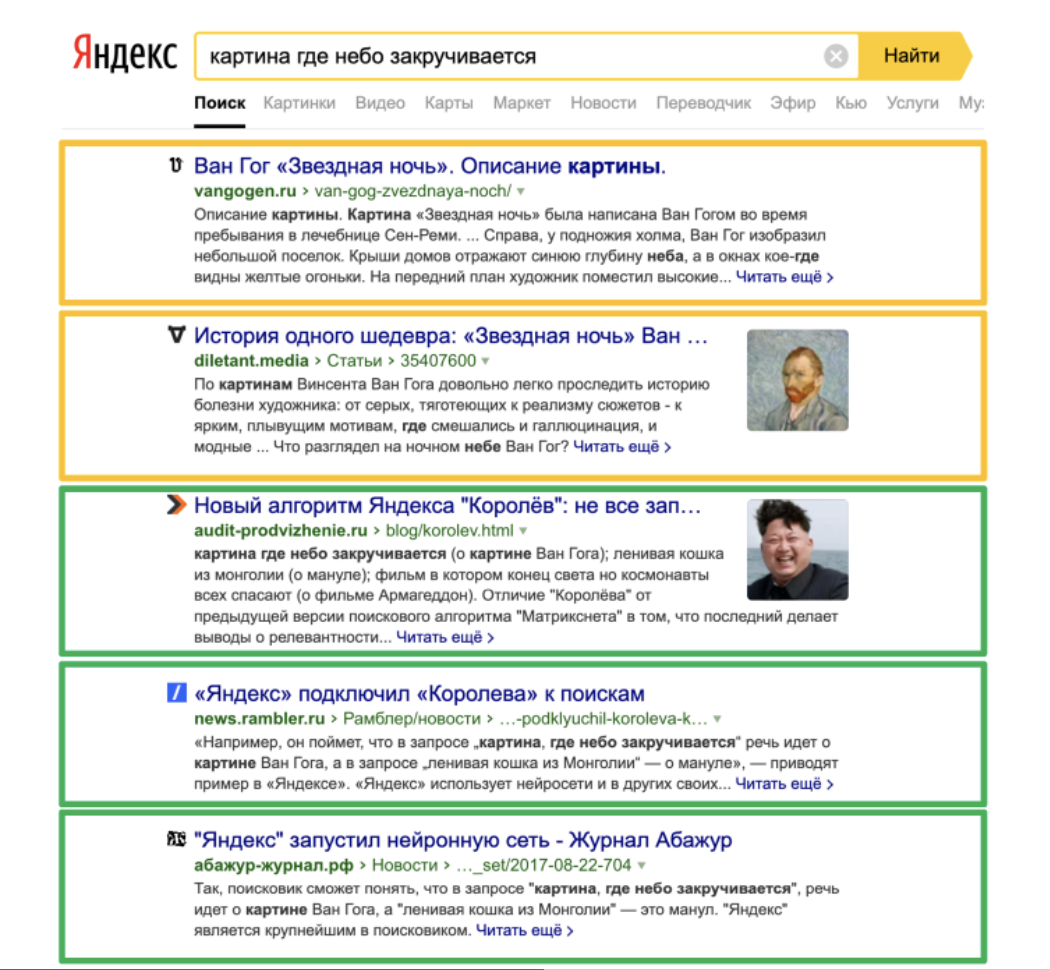
Пример «смешанной» выдачи
Условно говоря, каждый из факторов «тянет» в свою сторону, в результате происходит «борьба» факторов, отвечающих за «смысл», с теми, которые отвечают за «обычные вхождения» в текст.
В «борьбе» принимают участие и все остальные группы факторов:
- Поведенческие
- Хостовые факторы (сайт)
- Ссылочные
Это доказывает, что Яндекс не действует по принципу замены всего уже существующего новым алгоритмом, а по принципу улучшения существующей формулы новыми технологиями.
В ряде случаев, когда прямых ответов на запрос пользователя оказывается мало (24 документа по точному вхождению фразы [фильм про человека который выращивал картошку на другой планете]), факторы, отвечающие за смысл, начинают играть большую роль.
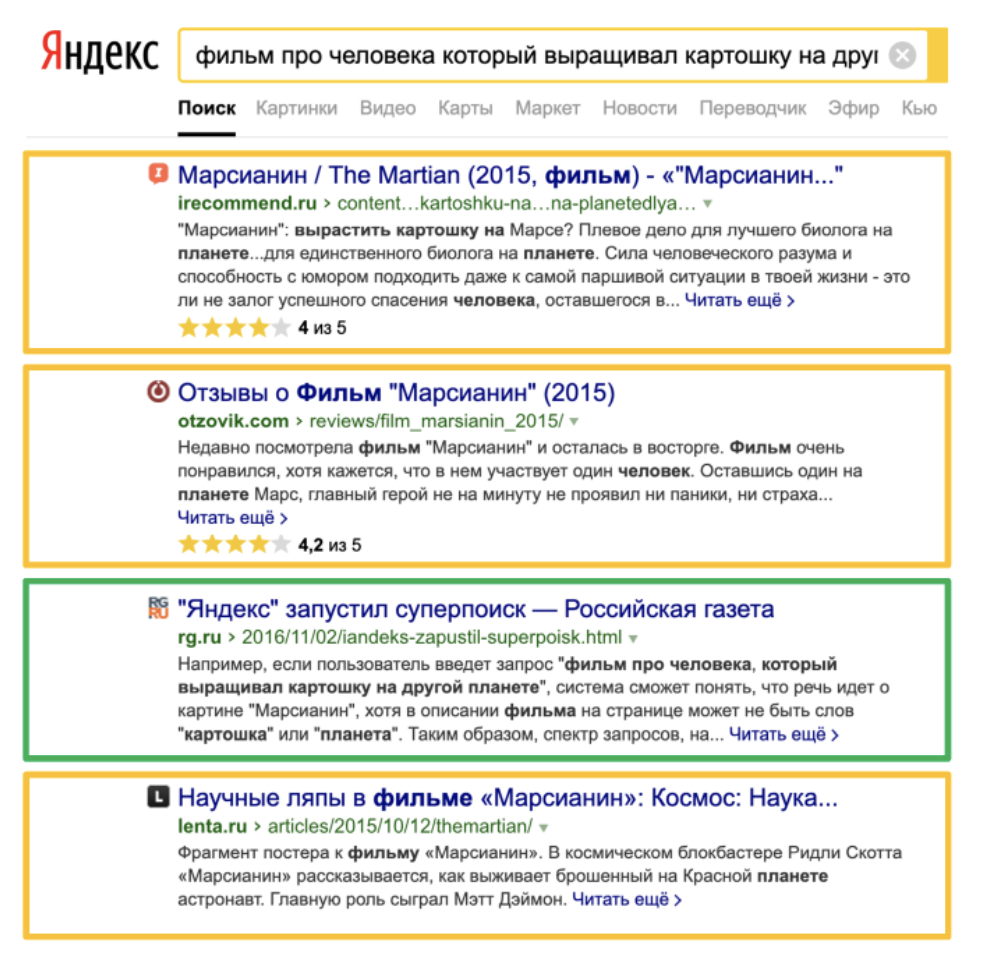
Как видим, по этому запросу в выдаче преобладают документы, найденные по «смыслу». Только один информационный сайт, содержащий точное вхождение, смог попасть в смысловой ТОП, благодаря своим прокачанным хостовым факторам.
Это позволяет сделать важный вывод:
С запуском YATI в Яндексе – факторы смысла стали впервые «бить» факторы вхождений (правда пока только по мНЧ-фразам).
BERT (Bidirectional Encoder Representations from Transformers) от Google и YATI: важные нюансы
В статье на Хабре, посвященной раскрытию технических деталей технологии YATI, алгоритм BERT обозначен как ее прямой конкурент. При этом YATI приписывается большая эффективность, чем модели BERT:
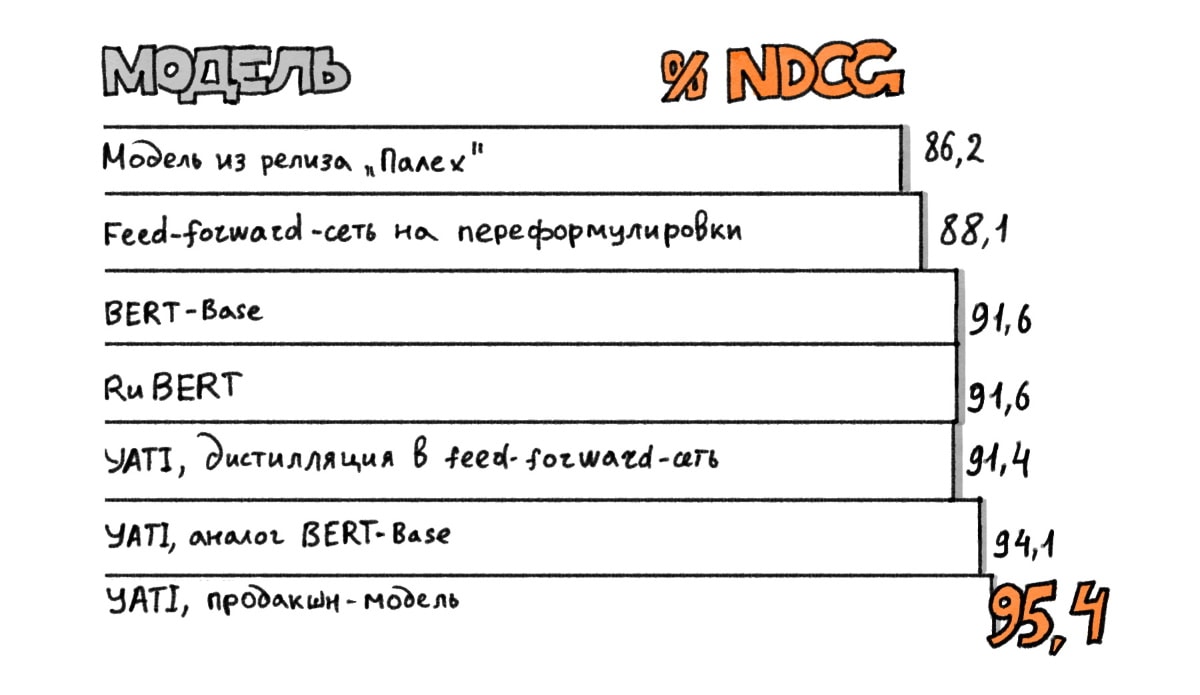
- – nDCG – широко принятая метрика оценки качества выдачи, учитывающая позицию каждого документа в выдаче и асессорскую (экспертную) оценку его релевантности (n – нормировка)
Нужно сказать, что технология BERT способна решать гораздо большее число задач, но, в том числе используется и для понимания «смысла» текста. На модели BERT базируется большое семейство языковых моделей:
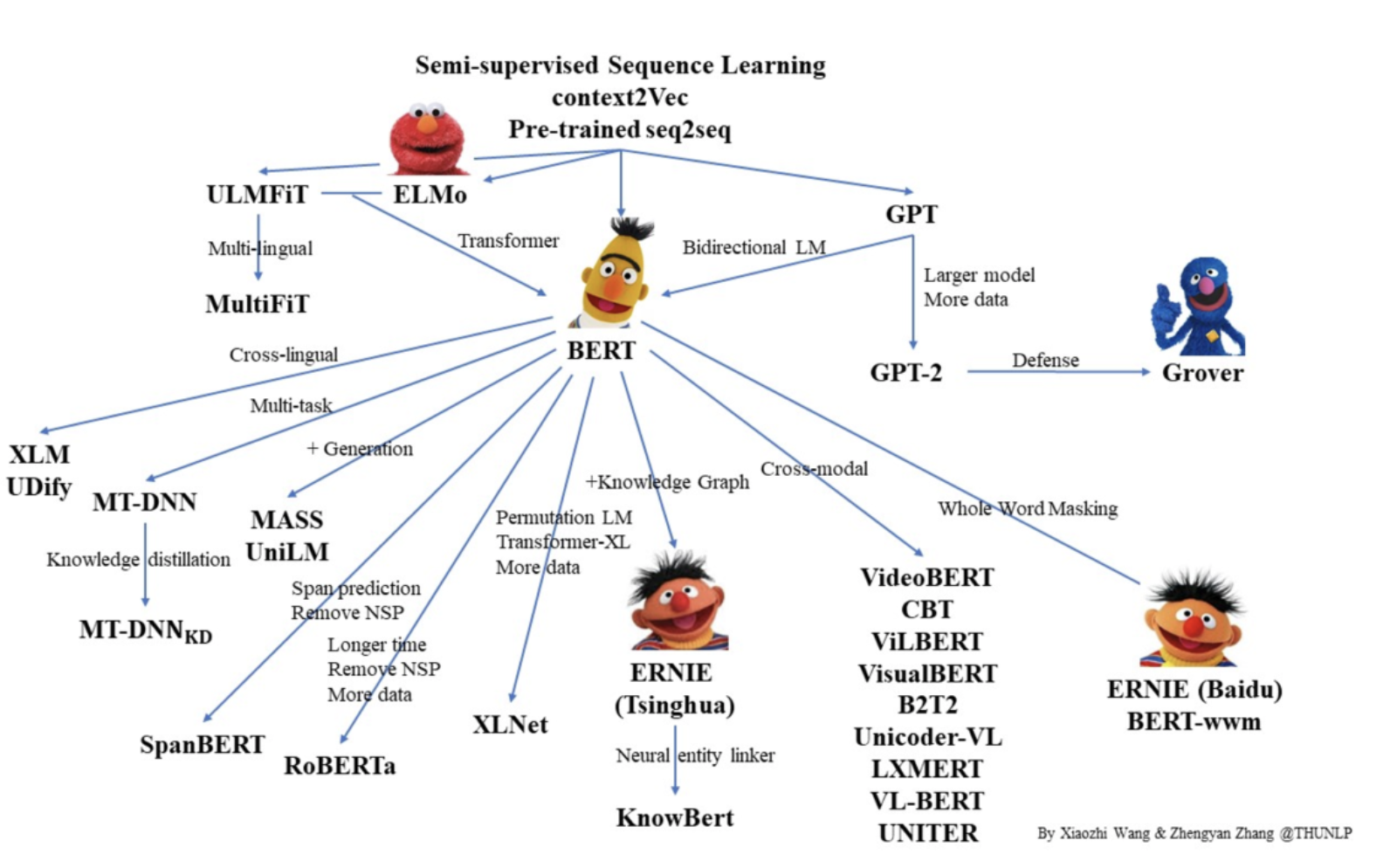
С точки зрения компьютерной лингвистики, BERT и YATI – это очень близкие алгоритмы. И Яндекс к YATI не сразу пришел.
Первым шагом, как уже упоминалось выше, был Палех, когда Яндекс впервые заявил, что научился понимать смысл текстов. Затем то же самое было озвучено при запуске Королёва. Вероятно, по этой причине технология YATI была анонсирована довольно скромно, без всякой помпы и акцентов на том, что поиск ещё лучше научился понимать смысл текстов, хотя технология действительно является прорывной.

Нюансы в YATI, которые нужно учитывать:
- Переформулировки и «пред-обучение на клик». База Яндекса из 1 млрд переформулировок: [первичная фраза] —> нет клика —> [новая фраза]. Модель учится предсказыать вероятность клика.
- Оценки толокеров. На втором этапе используются «более дешёвые и простые оценки» толокеров из Яндекс.Толоки.
- Оценки асессоров. Далее для обучения используются экспертные (асессорские) оценки релевантности.
- Данные, подаваемые на вход:
- Текст запроса
- Расширение запроса (синонимы, дополнительные слова)
- «Хорошие» фрагменты документа
- Стримы для документа: анкор-лист, запросный индекс для документа (даже не показы, а клики по запросам)
Сможет ли YATI победить накрутку ПФ в Яндексе
Ситуация с накруткой ПФ на конец 2020 года очень проблемная. Первая волна санкций за накрутку ПФ была отмечена в начале осени, и многие проекты до сих пор продолжают терять видимость практически до нуля.
Яндекс наказывает сайты, чьи поведенческие факторы кажутся ему неестественными. И некоторые проекты потеряли в видимости уже после запуска YATI, в том числе и 10 декабря.
Осталось еще много вопросов, тем не менее можно сказать, что ситуация с накруткой существенно улучшается.
Стоит привести здесь ответ одного из разработчиков нового алгоритма Яндекса:
«1 и 2 - Решающие деревья в GBDT работают немного по-другому. Глубина дерева фиксирована, мы её в наших моделях CatBoost не меняем. Если есть сильный признак, то Сплит по нему будет просто встречаться чаще (и возможно выше) в дереве той же глубины, и соответственно будет сильнее влиять на итоговое предсказание. Размер влияния можно увидеть например по метрике FSTR, которая численно оценивает вклад конкретного признака в предсказание. В случае с YATI – вклад новой модели заметно больше 50% от суммарного вклада вех признаков. В этом смысле трансформер решает «больше половины» задачи ранжирования».
Мы видим, что возможность отказаться от учета кликового фактора у Яндекса есть, и это позволит ему в дальнейшем эффективно бороться с накрутками.
От теории к практике
По поводу всего вышесказанного читатель может сказать : «Да, это все очень круто. Но как мне использовать YATI для продвижения своего сайта? И чего от него ждать?».
Исходя из утверждения, что YATI обеспечивает более 50% вклада в ранжирование, можно ожидать, что теперь «смысл» окончательно победил возможности SEO-специалистов в оптимизации текстов (и можно больше ничего не оптимизировать). Равно как и того, что все факторы вида «точное вхождение», «Title» и «добавить ключей» остались в прошлом. Хотя… Оценка же сильно зависит от того, какие запросы берутся для выборки. Как все на самом деле?
Изначально для улучшения ранжирования поисковая система Яндекс, конечно же, обучалась на редких запросах, по которым итак документов недостаточно. Поэтому в 50% вклад в ранжирование именно этих запросов вполне можно поверить. Именно на них очень хорошо видна та борьба между «смыслом» и «вхождением», в которой «смысл» начал побеждать. Но какова ситуация по ВЧ-запросам, по средне- и низкочастотным?
Лаборатория «Пиксель Тулс» провела небольшое исследование, сравнив значимость фактора «точное вхождение в тексте» по НЧ-запросам в 2019 и 2020 годах (после запуска YATI).
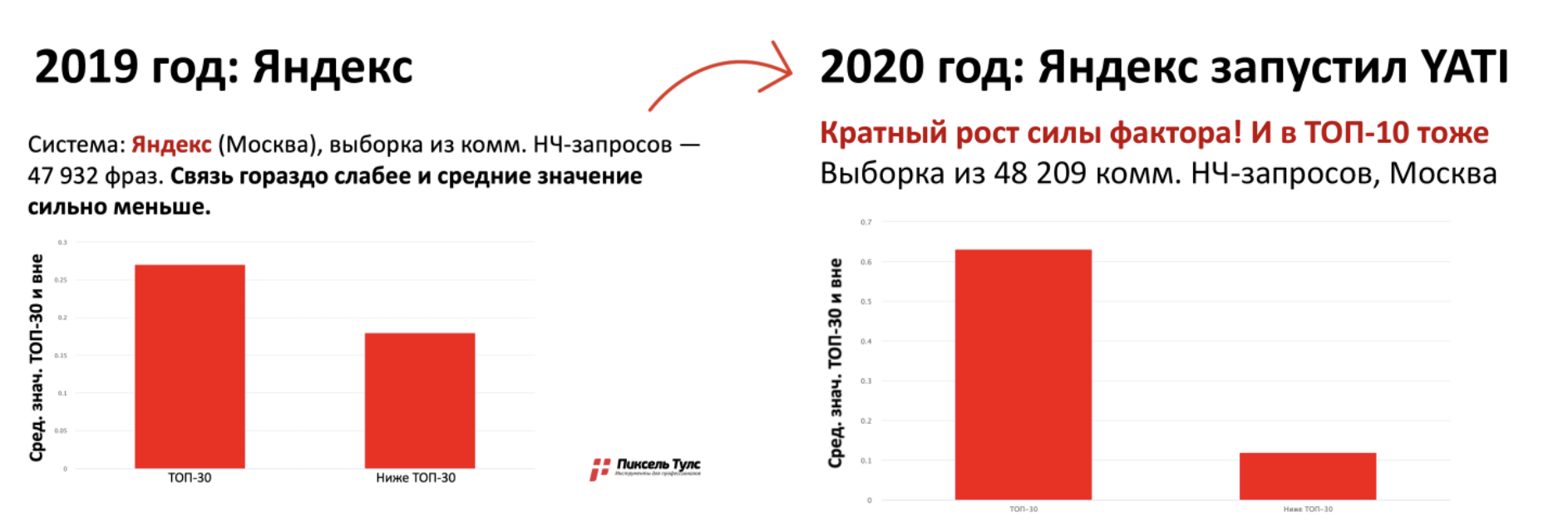
Как видим, «точное вхождение» никуда не пропало, а наоборот, увеличило свою значимость.
Что же произошло за год с СЧ и ВЧ-запросами? Вот тут ситуация с точным вхождением поменялась - явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
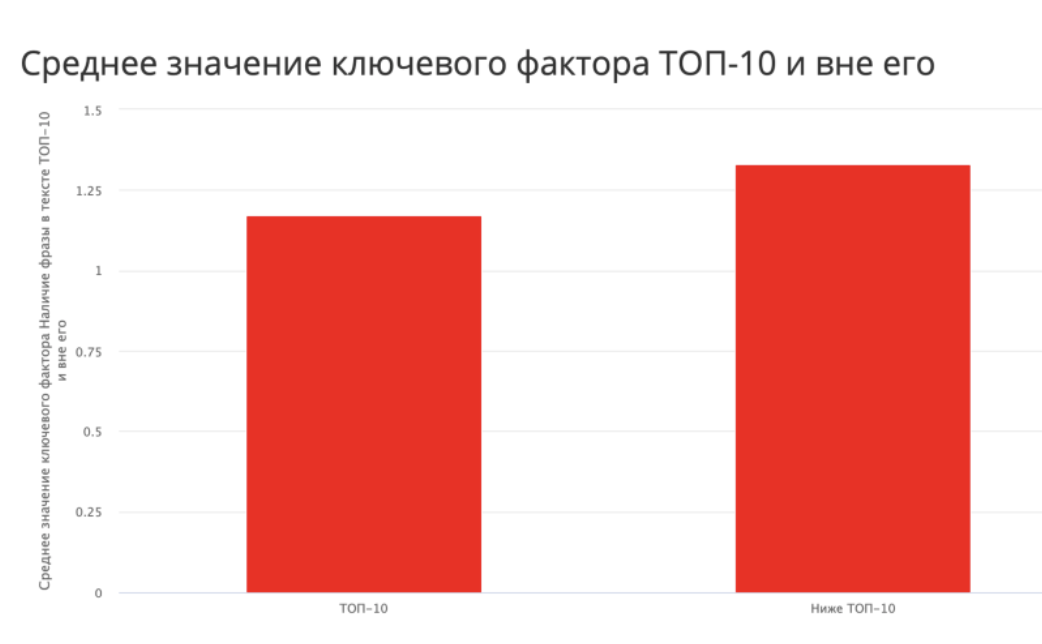
При этом среднее значение фактора – в районе единицы, что означает, что одно вхождение есть и этого более чем достаточно.
Рассмотрим также на выборке коммерческих запросов роль фактора «наличие всех слов из запроса в тексте» в Яндексе:
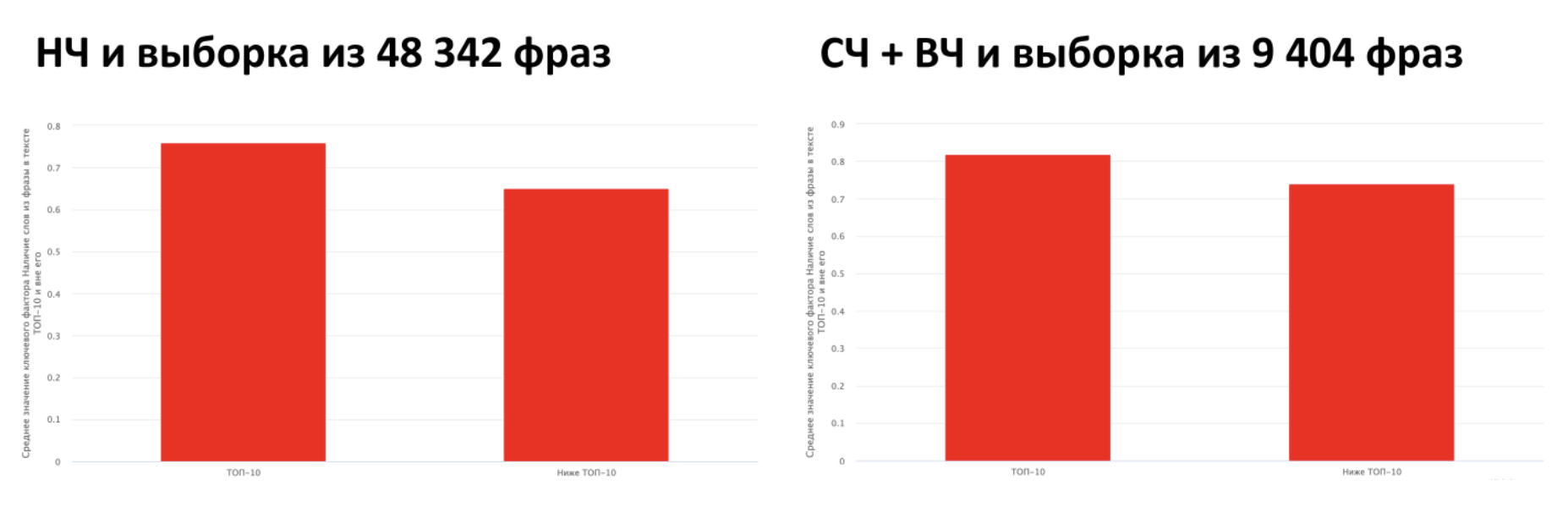
Как видим, здесь особой разницы между НЧ и СЧ+ВЧ запросами нет. Однако, прослеживается определенная корреляция между попаданием в ТОП и наличием всех слов запроса в документе. Причем значение этого фактора - 0.8, то есть, это справедливо для 80% сайтов. А значит рекомендация по добавлению всех слов из запроса в текст по-прежнему является актуальной.
Проверим таким же образом и «слова в Title» после YATI:
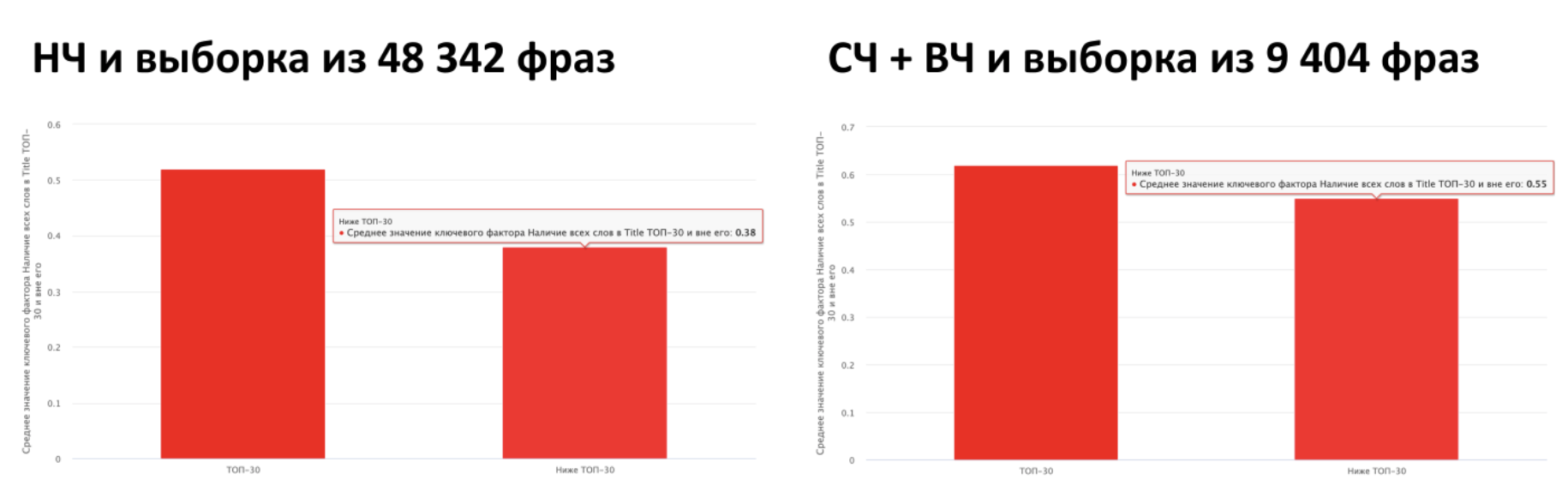
В 2020 году наблюдается рост среднего значения этого фактора относительно 2019 года, то есть значительно чаще в выдаче стали встречаться документы у которых есть все слова запроса в Title, однако есть видимое уменьшение корреляции с позицией. Можно сказать, что этот фактор необходим для попадания на выдачу, но не влияет на позицию в этой выдаче. И для НЧ-запросов он важней, чем для СЧ и ВЧ.
7 практических советов:
1. Оптимизируйте под YATI.
Нужно увеличить количество слов, которые встречаются в контексте со словами из поискового запроса. Это могут быть слова из подсветки выдачи; слова, задающие тематику; слова, которые встречаются у конкурентов, но которых нет на продвигаемой странице.
2. Форматируйте текст и расставляйте акценты
Обязательно используйте форматирование при «большом объеме контента» (более 12-14 предложений). Выносите в заголовки и выделенные фрагменты тематические и ключевые слова.
3. Анализируйте и оптимизируйте запросный индекс для документов (Яндекс.Вебмастер —> Поисковые запросы)
- Изучите поисковые запросы, по которым были зафиксированы переходы на URL, они должны быть релевантными
- Проверьте релевантность запросов, по которым были показы, но не было переходов. В случае нерелевантности фраз — примите меры.
4. Запросный индекс для хоста
Данные всего хоста (сайта), как и ранее, сказываются на факторах для заданной страницы. Поэтому проверки, описанные в пункте 3, актуальны и в разрезе всего сайта, а не только заданного URL.
5. Расширяйте семантическое ядро для продвижения в сторону НЧ-запросов
«Вложенные» и синонимичные запросы помогают в продвижении по более общим и близким по смыслу. Пример: [seo продвижение сайта цена в москве] поможет и для [продвижение сайтов] и для [smm продвижение].
6. Проводите конкурентный анализ
Анализируйте показы URL конкурентов по запросам; присматривайтесь к текстам: какие там тематические слова, фразы, структура; анализируйте структуру сайта и охват запросов из семантического ядра. (В помощь: Вебинар по анализу конкурентов в выдаче и шаблон анализа конкурентов )
7. Не забывайте про классику поисковой оптимизации: текст, точные вхождения, все слова в Title
Выводы:
Хоть YATI и выглядит прорывной технологией, надо помнить, что Яндекс строится по принципу «добавить сверху», а не «написать всё с нуля» – то есть, новые факторы добавляются к старым.
Роль смысловой близости текста и запроса растёт, если у поисковой системы нет или мало данных о поведении по данному запросу и мало документов, которые «хороши» по классическим текстовым факторам.
Максимальный прирост идёт по неоднозначным, многословным и редким запросам (длинный хвост).
На вход YATI подаются различные стримы: анкор-лист документа, запросный индекс по кликам.
А что ещё надо делать, учитывая, что в Яндексе новый алгоритм ранжирования?
Обновить распределение
Если вы давно делали группировку запросов и распределение (более 4-6 месяцев назад) – самое время её переделать. YATI, также как и в свое время Королёв, существенно изменил состав кластеров, которые формируются при анализе ТОПов. Ряд запросов могли поменять свой тип — стать целевыми или наоборот.
Вообще, раз в 3 месяца рекомендуется «освежать» семантику и учитывать актуальный состав выдачи. Всем удачи в продвижении!





