
Автор: Билл Славски – известный западный SEO-консультант, эксперт по патентам Google, редактор SEO by the Sea.
Различия между традиционным и семантическим SEO
Поисковая оптимизация всегда была маркетинговой деятельностью в интернете. SEO представляет владельцев сайтов потребителям и делает возможной коммуникацию между ними. В результате они могут взаимодействовать по поводу товаров и сервисов, которые могут приобрести потребители, чтобы стать клиентами.
Согласно традиционной SEO-оптимизации, страницы обычно ранжируются в результатах поиска на основе комбинации оценок, присвоенных в ходе информационного поиска (Information Retrieval), и основанных на сигналах релевантности и авторитетности с использованием таких факторов, как ссылки с других сайтов.
Семантическое SEO отличается от традиционного. Оно фокусируется на объектах реального мира, или сущностях, таких как люди, места и вещи (идеи и понятия).
В рамках этой концепции веб-страница как страница о сущностях содержит информацию о различных элементах этих объектов, таких как факты об атрибутах, используемых для их описания, и идентификаторы, которые помогают узнать больше о сущности, чтобы лучше ее понять.
В семантическом SEO мы говорим о таких вещах, как:
- Панели знаний;
- Поисковые карусели, заполненные сущностями;
- Выделенные описания (Featured Snippets), которые могут отвечать на вопросы о сущностях, появляющихся в запросах;
- Блоки с похожими запросами, которые могут напоминать ответы в избранных сниппетах;
- Релевантные сущности;
- Сущности и семантический поиск.
Например, сайт об американском городе Балтимор может содержать информацию о тех людях, которые там жили, и исторических памятниках. Он может рассказывать пользователям об известных церквях и школах, а также зданиях, местах и компаниях.
Если бы вы собирались написать о Балтиморе, в идеале вам нужно было бы углубиться в историю города, при этом обращая внимание на то, о ком посетителям может быть интересно узнать больше. И упомянуть историю, которая принесла Америке свой государственный гимн.
В середине 2000-х в Google были инженеры, которые работали над проектом под названием «Annotation Framework». Этим проектом руководил Эндрю Хог, который также отвечал за покупку MetaWeb и базы знаний Freebase. Подробнее об этих инициативах можно узнать из резюме Хога. Он также участвовал в создании видео из серии Google Tech Talk, в котором рассказывается, чем занималась компания в то время.
Cемантическое SEO стало активнее использоваться в SERP Google
Еще один аспект семантического SEO – это переход от 10 «синих ссылок» в поисковых системах к выдаче, наполненной расширенными результатами. Изначально эти изменения были описаны в посте Раманатана Гухи (Ramanathan Guha) в блоге Google, а затем в посте о запуске расширенных результатов под авторством Кави Гоэла (Kavi Goel), Раманатана Гухи (Ramanathan Guha) и Отара Ханссона (Othar Hansson).
В 2012 году Google расширил информацию, доступную в Freebase, и предоставил нам результаты поиска с дополнительной информацией о сущностях, которые появляются в запросах, или, по крайней мере, тех сущностях, о которых Google знает, и которые, возможно, были включены в Сеть знаний (см. «Как работает Сеть знаний Google»).
Мы можем видеть больше информации о сущностях на панелях знаний. При этом Google использует разные шаблоны в зависимости от типа сущности. Так, на панелях для локальных компаний мы видим отзывы, выражающие общие настроения в отношении этих бизнесов.
Google также может показывать похожие запросы, относящиеся к отображаемым на панелях сущностям. Кроме того, блоки знаний часто сообщают нам о других сущностях, которые также ищут пользователи (блоки «People also search»).
Предоставление дополнительной информации о сущностях через разметку Schema.org
В 2011 году Google объединился с другими поисковыми системами, чтобы предоставить владельцам сайтов способ передачи машиночитаемой информации о сущностях, которые появляются на их страницах. Эта инициатива получила название Schema.org. Такой подход к обмену данными между поисковыми системами перекликается с тем, что мы наблюдали при разработке XML-карт сайта.
Schema – одна из самых быстрорастущих областей SEO, и сейчас прилагается все больше усилий для оперативного обновления словаря и выхода новых версий.
В наши дни оптимизаторы часто изучают Schema.org как часть семантического SEO и следят за добавлением поддержки новых схем. Рейтинги в виде звезд для товаров помогают получить больше кликов в поисковой выдаче, и о них точно стоит узнать.
Мы, например, внимательно следим за изменениями в схемах по мере выхода новых версий словаря.
Объем знаний в интернете растет
Изобретение семантического поиска было запатентовано Google в 1999 году. Этот алгоритм был назван DIPRE (Dual Iterative Pattern Relation Expansion).
Патент описывает способ поиска сайтов, которые содержат информацию о конкретных книгах и атрибутах этих книг – когда они были опубликованы, кто их издатели, сколько страниц у каждой из них, и многое другое. Если на сайте были все книги, алгоритм велел собрать информацию о других книгах, которые он содержал.
В начале 2020 года компания подала заявку на дополнительный патент, в котором говорится о сборе информации о книгах для отображения в результатах поиска. Этот патент касался всех видов сущностей, а не только книг.
Патенты Google также содержат много деталей о том, как поисковик может собирать информацию о сущностях прямо с веб-страниц. Одно из наиболее подробных описаний связано с использованием обработки естественного языка для сбора части речевой информации и распознавания сущностей для построения троек (подлежащее/ сказуемое/ дополнение) для этих сущностей. Подробнее о том, как Google может это делать, см. в статье «Entity Extractions for Knowledge Graphs at Google».
Расширение значения запроса через переписывание
SEO-специалисты занимаются семантическим SEO почти столько же, сколько и традиционным. Мы не просто оптимизируем страницы для ключевых слов. Мы оптимизируем их для значений, обозначенных в запросах.
Еще в 2003 году Google начал переписывать запросы, которые пользователи вводили, используя синонимы.
Мы видели, как Google разработал более продвинутые способы замены синонимов с использованием Hummingbird. При этом патент, в котором описывался этот подход, был выдан за несколько недель до того, как Google официально объявил о запуске этого алгоритма в день своего 15-летия.
В последние годы Google рассказывал нам об использовании AI-подхода с применением векторов слов для переписывания неоднозначных запросов и их расширения с помощью потенциально пропущенных слов в запросах.
Эти запросы могут улавливать недостающие значения и ответы на запросы, с которыми раньше у Google были трудности. Мы сослались на цитаты, лежащие в основе подхода Word Vectors, в статье «Citations behind the Google Brain Word Vectors Approach».
Ниже – пример результатов поиска, где Hummingbird заменяет слово «place» (место) на «restaurant» (ресторан):
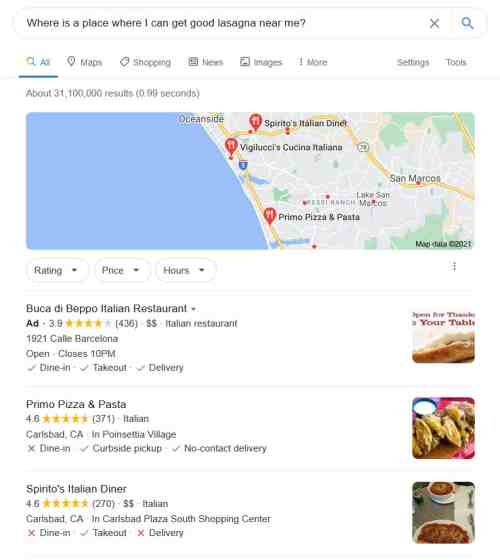
Это пример о сущностях из реального мира и понимании смысла слов в запросе. Он о том, как SEO становится семантическим SEO.
Дополнение поисковой выдачи результатами из Сети знаний
Несколько лет назад на конференции SMX West сотрудник Google Поль Хаар (Paul Haahr) презентовал свой доклад на тему «How Google Works: A Google Ranking Engineer’s Story» («Как работает Google: история инженера по ранжированию Google»). В нем он рассказал, как результаты из выдачи Сети знаний дополняют основные результаты в SERP.
Сущности в семантическом SEO
Патент Google, который вышел после этой презентации, рассказал нам, как поисковик будет искать в запросе сущность (как объяснял Хаар). И, если Google найдет эту сущность, то может решить дополнить результаты поиска результатами из Сети знаний. Опять же, это подход к поиску, основанный на семантическом SEO. Мы писали об этом патенте в статье «Augmented Search Queries Using Knowledge Graph Information».
Опять же, Google показывает нам, что семантическое SEO фокусируется на поиске реальных сущностей в запросах. Результаты из Сети знаний могут включать выделенные описания, отвечающие на вопросы, которые многие люди задают об этих сущностях. Эти результаты также могут включать блоки с похожими запросами. Google находит связанные запросы, анализируя журналы запросов в графе вопросов (Question Graph).
Если вы проводите исследование ключевых слов для страниц и хотели бы лучше понимать релевантные сущности и понятия, то поищите по этим запросам в Google Картинках. Это может рассказать вам о сущностях и терминах, которые могут быть связаны с людьми, местами и вещами.
Тематическое моделирование в семантическом SEO
Еще в 2006 году мы писали об индексировании на основе фраз в своей статье. Мы много раз расширяли этот подход на протяжении многих лет. За это время Google получил множество связанных патентов по различным аспектам фразового индексирования.
Позже мы также добавили к статье пост под названием «Тематическое моделирование с использованием связанных слов в документах и анкорного текста», который демонстрирует, насколько часто повторяющиеся совпадающие фразы могут выступать предикторами того, о чем идет речь на тех страницах, где они используются.
Пару лет спустя мы написали об изменении патента на индексирование на основе фраз, которое превратило его из подхода повторного ранжирования в подход прямого ранжирования: «Обновленное индексирование Google на основе фраз».
Ответы на вопросы с использованием персональных графов знаний
В статье «Ответы на вопросы с использованием графов знаний» мы писали об Association Scores, которые придают разный вес элементам сущностей, и о том, как они используют свои источники для придания им веса.
Мы также пишем о том, как Google может принимать запрос, запускать его, собирать самые популярные страницы в качестве результатов и создавать на основе этих результатов граф знаний, чтобы предоставить ответ. Документ, который рассказывает об этом, представляет собой патентную заявку «Natural Language Processing With An N-Gram Machine».
В статье мы приводим несколько примеров использования поисковых каруселей с сущностями, отвечающими на запросы. Карусель с ранжированными сущностями появляется, например, при поиске по запросу [Лучшая научно-фантастическая книга 2020 года] (прим. ред. – в англоязычной выдаче).
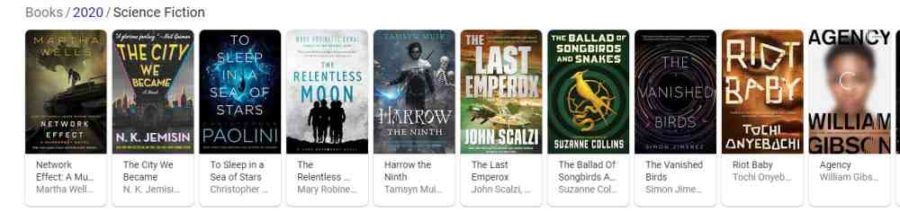
Эти книги берутся из Query Results, заполненных сущностями, которые показываются в карусели в ранжированном порядке.
Мы также писали о том, как графы знаний могут создаваться в качестве персонализированных результатов для отдельных людей и использоваться для ответов на их вопросы.
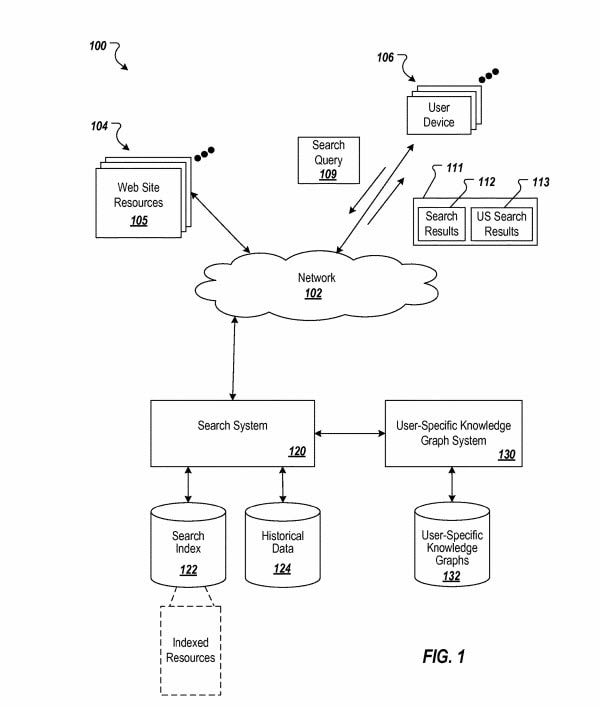
Поисковик будет собирать реальную информацию о вас и использовать ее, чтобы отвечать на вопросы, которые вас интересуют. Это та перспектива, которую обещает семантическое SEO по мере текущего перехода в мир умных устройств и интернета вещей.
Семантический интернет
Еще в 2001 году Тим Бернерс-Ли (Tim Berners-Lee), Джеймс Хендлер (James Hendler) и Ора Лассила (Ora Lassila) написали статью о семантической Сети для научно-популярного журнала Scientific American. Обмен информацией и сбор данных, описанные в ней, говорят нам о будущем семантического SEO, над которым работают многие компании, такие как Google.
Более семантический интернет – это не тот, где страницы наполнены синонимами и семантически релевантными словами. Он такой, как писал Бернерс-Ли:
«Семантический интернет – это не отдельная сеть, а расширение существующей сети, в которой информации придается четко определенное значение, что позволяет компьютерам и людям работать совместно».
Вместо заключения
В этой статье мы хотели поделиться теми тенденциями, которые мы наблюдали в патентах и на страницах Google. Они говорят нам, что поиск становится более семантическим.
Большинство страниц, которые ранжируются в Google по таким запросам, как [семантическое SEO], неглубокие и заполнены синонимами. Они также характеризуются недостаточным пониманием того, как может работать семантический поиск, упоминанием технологий 1980-х годов и отсутствием информации о таких вещах, как графы знаний и разметка структурированных данных.
Надеемся, что данная статья даст вам более глубокое понимание данного вопроса.
Материалы по теме:





