
По мере эволюции интернета растёт спрос на сайты, имеющие всё более интерактивную функциональность. В результате многие разработчики создают сайты, используя такие фреймворки, как React и Angular. Это, в свою очередь, вызывает всё больше вопросов на тему оптимизации таких ресурсов для SEO. В основном, оптимизаторы и вебмастера ставят вопрос так: могут ли поисковые системы, такие как Google, сканировать JavaScript?
И это неправильный вопрос.
Давайте разбираться. Если вы используете JavaScript-фреймворки с рендерингом на стороне сервера, вы уже решили эту проблему ещё до того, как она возникла. В этой статье речь пойдёт о тех реализациях JS-фреймворков, в которых рендеринг осуществляется на стороне клиента. И это вызывает целый ряд проблем.
Перед тем, как объяснить, почему так, важно получить базовое понимание того, как работают поисковые системы. В своей статье «The Three Pillars of SEO», я изложил своё понимание этого вопроса. Здесь я приведу из неё три основных пункта.
Три процесса поисковых систем
В двух словах, работа большинства информационно-поисковых систем основана на трёх процессах:
- Краулер
- Индексатор
- Движок запросов
Когда дело доходит до JavaScript и SEO, то нас интересуют первые два процесса. Что касается Google, то в этой поисковой системе роль краулера выполняет Googlebot, а инфраструктура индексирования носит название Caffeine. Эти подсистемы выполняют очень разные функции, и это важно понимать, чтобы избежать путаницы.
Основная задача краулера – найти все URL и обработать их. На самом деле это довольно сложная система, в которой задействованы такие подпроцессы, как наборы источников, очерёдность и расписание сканирования, важность URL и отслеживание времени ответа сервера.
Краулер также включает модуль парсинга, который анализирует исходный HTML-код сканируемых страниц и извлекает из него ссылки. Парсер не рендерит страницы, он только анализирует исходный код и извлекает все URL, которые находит во фрагментах <a href=”…”>.
Когда краулер видит новые URL или URL, которые были изменены с момента последнего посещения, он отправляет их индексатору. Индексатор затем пытается понять эти URL, анализируя их контент и релевантность. Здесь также задействовано множество подпроцессов, анализирующих такие вещи, как шаблон страницы, каноникализация и оценка ссылочного графа для определения PageRank URL-адреса (поскольку Google всё еще использует эту метрику внутри компании для определения важности URL).
Индексатор также рендерит веб-страницы и выполняет JavaScript. Недавно Google опубликовал на сайте для разработчиков подборку документов, в которых объясняется, как работает Web Rendering Service (Web). Ознакомиться с ними можно по ссылке.
В индексаторе выполнением JavaScript занимается WRS. Инструмент Сканер Google в Search Console позволяет посмотреть, как WRS видит страницу.
Краулер и индексатор работают в тесной связи друг с другом: краулер отправляет то, что находит, индексатору, а последний «скармливает» новые URL (найденные, к примеру, при выполнении JavaScript) краулеру. Индексатор также помогает приоретизировать URL для краулера, отдавая преимущество важным URL, которые краулер должен регулярно посещать.
Googlebot или Caffeine?
Путаница начинается, когда специалисты – будь то оптимизаторы, разработчики или же сотрудники Google – говорят «Googlebot» (краулер), а на самом деле имеют в виду «Caffein» (индексатор). Почему так, вполне понятно: эта номенклатура используется взаимозаменяемо даже в документации Google:

Когда документация по WRS была опубликована, я задал вопрос на эту тему Гэри Илшу, поскольку меня сбивало с толку использование в ней слова «Googlebot». Краулер ничего не рендерит. У него есть базовый парсер для извлечения URL из исходного кода, но он не выполняет JavaScript. Это делает индексатор. Поэтому WRS – это часть инфраструктуры Caffeine. Верно?
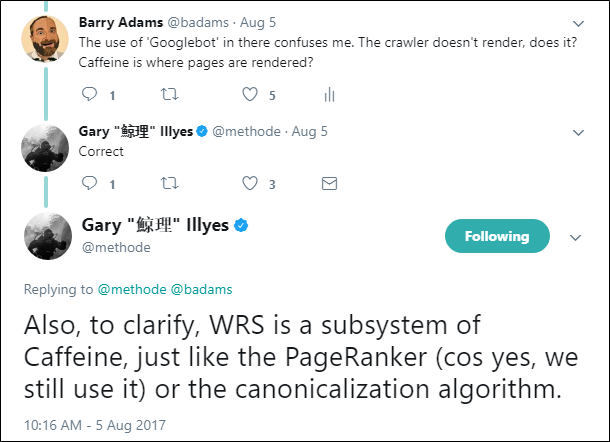
Да, верно. Однако этот противоречивый текст по-прежнему остаётся в документации по WRS. Поэтому оптимизаторам простительно путать эти два процесса, называя их «Googlebot». Это происходит всё время, даже со стороны самых опытных и квалифицированных SEO-специалистов в отрасли. И это проблема.
Сканирование, индексирование и ранжирование
Когда разработчики и оптимизаторы задают вопрос, может ли Googlebot сканировать JavaScript, мы склонны думать, что ответ «Да», поскольку Google действительно обрабатывает JavaScript, извлекает из него ссылки и ранжирует эти страницы. Так имеет ли значение, что это не краулер, а индексатор обрабатывает JavaScript? Нужно ли нам знать, что это разные процессы, выполняющие разные функции, если в конечном итоге Google ранжирует JavaScript-страницы?
Да, нужно. Мы должны об этом знать.
Несмотря на невероятную сложность Googlebot и Caffeine, JavaScript-контент делает процессы сканирования и индексирования чрезвычайно неэффективными. Встраивая контент и ссылки в JavaScript, мы спрашиваем – нет, требуем – чтобы Google приложил усилия и обработал все наши страницы. Что к его чести, он фактически и делает. Однако для этого требуется время и тесное взаимодействие между краулером и индексатором.
Но, как мы знаем, терпение Google не безгранично. Концепция «краулингового бюджета» – объединение различных концепций вокруг приоритетности обхода и важности URL – говорит нам, что Google не будет бесконечно пытаться просканировать все страницы сайта. Мы должны ему немного помочь и сделать так, чтобы все страницы, которые должны быть просканированы и проиндексированы, легко находились и были правильно каноникализированы.
Использование JavaScript-фреймворков усложняет эту задачу.
JavaScript = неэффективность
Относительно несложный процесс, в ходе которого краулер находит страницы сайта, а индексатор их оценивает, вдруг становится сложным. На JS-сайтах, где большинство или все внутренние ссылки не являются частью исходного HTML-кода, при первом посещении краулер находит только ограниченный набор URL. Потом ему нужно подождать, пока индексатор обработает эти страницы и извлечёт новые URL, которые краулер затем просканирует и отправит индексатору. И так раз за разом.
На JavaScript-сайтах процессы сканирования и индексирования становятся медленными и неэффективными.
Это также означает, что оценивание графа внутренних ссылок сайта должно осуществляться снова и снова по мере того, как всё новые URL извлекаются из JavaScript. С каждым новым набором страниц, которые индексатор извлекает из JavaScript-кода, внутренняя структура сайта должна подвергается повторной оценке, а относительная важность страниц будет меняться.
Это может привести к тому, что ключевые страницы будут расцениваться как неважные из-за недостаточного количества ссылочного веса, а относительно неважные страницы будут восприниматься как имеющие высокую ценность, поскольку на них указывают обычные HTML-ссылки, для нахождения которых не требуется рендеринг JavaScript.
Поскольку страницы сканируются и обрабатываются согласно их оценочной важности, не исключена ситуация, когда Google будет тратить много времени на сканирование и рендеринг ненужных страниц и очень мало времени на обработку тех страниц, которые должны ранжироваться.
Хорошее SEO = эффективность
С годами я узнал, что хорошее SEO, по большей части, сводится к тому, чтобы облегчить жизнь поисковых систем. Когда мы делаем наш контент легко находимым, легко потребляемым и простым для оценки, мы получаем более высокие позиции в SERP.
JavaScript усложняет жизнь поисковых систем. Мы просим Google делать больше, чтобы обнаружить, обработать и оценить наш контент. И часто это приводит к более низким позициям сайта в выдаче.
Да, JavaScript-контент индексируется и ранжируется, но эта работа выполняется с трудом. Если вы серьезно настроены в отношении достижения успеха в органическом поиске, старайтесь максимально всё упрощать. Это значит, что контент и ссылки должны предоставляться поисковым системам в виде простого HTML-кода, чтобы они могли максимально эффективно сканировать, индексировать и ранжировать ваши страницы.
Фактически, правильным ответом на вопрос, сканирует ли Google JavaScript, будет «Нет».
Ответом на вопрос, индексирует ли Google JavaScript, будет «Да», а на вопрос, надо ли использовать JavaScript – «Зависит от ситуации».
Если вас волнует SEO, то меньшее количество JavaScript означает более высокую эффективность и, следовательно, более высокие позиции в ранжировании. То, на чём вы сделаете упор, определит тот путь, который вы должны выбрать. Удачи!





