
В рамках Шестой вебмастерской Яндекса прошел мастер-класс Александра Смирнова, посвященный основным моментам и ошибкам, связанным с индексированием сайтов.
Помимо работы с новым сайтом, (о которой было рассказано в предыдущей статье) большое количество вопросов в поддержку поступает о работе с уже проиндексированным ресурсом. Вебмастерам важно следовать тенденциям рынка, смотреть, что нужно именно их пользователям.
Все пользователи поисковой системы хотят, чтобы в результатах поиска участвовала наиболее актуальная и свежая информация. Поэтому вопрос о том, как ускорить индексирование сайта, довольно остро стоит перед каждым вебмастером.
Вот несколько пунктов, при помощи которых можно повлиять на скорость индексирования сайта:
1. Не давайте роботу загружать то, что загружать не нужно
Вопрос: С чем связана большая разница показателей загруженных страниц в поиске? Например:
Загруженные страницы: 294 542
Исключенные страницы: 59 652
Страницы в поиске: 270
Список всех загруженных страниц можно скачать из Яндекс.Вебмастера. Так же, нельзя забывать о том, что Вебмастер хорошо умеет две вещи – собирать данные и показывать их. Поэтому, в разделе «Страницы в поиске», вебмастер может получить исчерпывающую информацию по каждой странице, когда она была добавлена в поиск, когда была удалена и по какой причине.
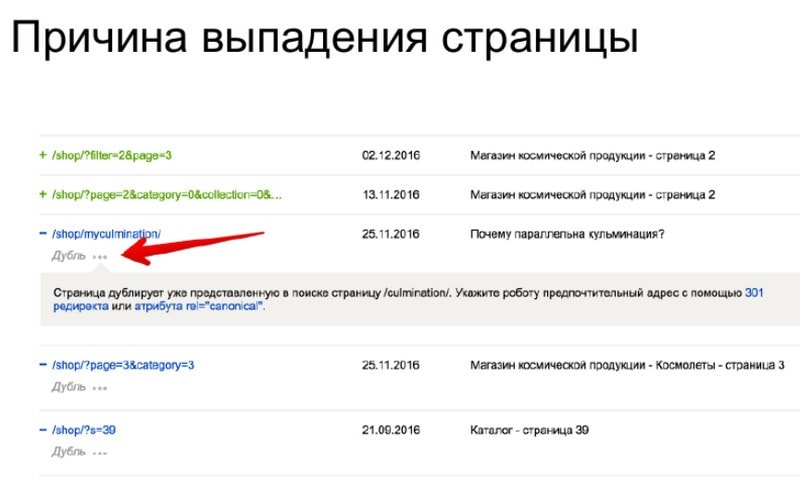
Поэтому, если вдруг вебмастер столкнулся с описанной выше проблемой, то нужно взять либо архив, либо соответствующий раздел в Вебмастере, и тщательно проанализировать адреса страниц. Зачастую там можно увидеть множество страниц с какими-то случайными параметрами, которые ничего не меняют на странице, тем не менее, такие страницы разрешены в robots.txt, отвечают кодом 200:

Также роботом загружается огромное количество страниц действий – например, страницы покупки, которые все перенаправляют на страницу корзины, и они также в 90% случаев доступны для робота.

Подобные страницы нужно запрещать в файле robots.txt, и со временем данные о них будут удалены из базы робота, они пропадут из Яндекс.Вебмастера, а количество загруженных страниц уменьшится.
Наверняка всех беспокоит также вопрос о том, почему так мало страниц в поиске? Объяснение очень простое. Если большинство страниц товара на вашем сайте выглядит вот так:
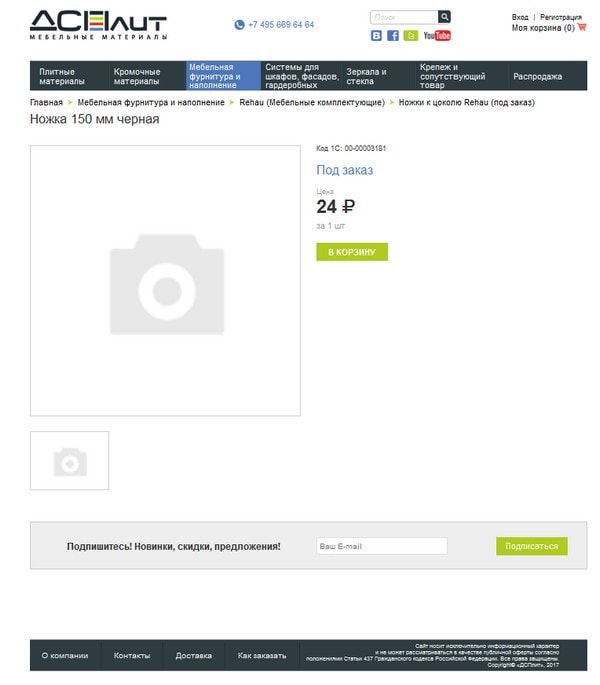
Где даже над исходным кодом никто особенно не заморачивается, прописывая стандартные метатеги для всего каталога и используя при этом минимум текста в описаниях.
Если вы хотите, чтобы страницы товаров индексировались и участвовали в поиске, нужно над ними хоть немножко поработать – уникализировать установленные на странице метатеги, добавить больше текстового описания, какие-то рекомендации, отзывы покупателей, ну и фото, чтобы пользователь был уверен в том, что не ошибся в своем выборе.
2. Смотреть логи сервера
При помощи логов сервера можно посмотреть, как каким именно страницам обращается индексирующий робот. Если присмотреться, то можно понять, к каким именно параметрам он обращается:

В данном случае видно, что четыре раза подряд робот обратился к служебным страницам, и это жирный повод запретить их в robots.txt.
Так же, при помощи логов сервера можно увидеть частоту обращений индексирующего робота и других ограничений со стороны хостера.
Как правило, к большому сайту робот совершает 1-2 обращения в секунду, в зависимости от того, сколько страниц этого сайта он знает. Если в логах вы видите, что к страницам вашего сайта робот обращается значительно реже, проверьте, если у вас установлена директива Crawl-delay, очень часто она мешает индексировать большие ресурсы.
Что же касается ограничений со стороны хостинг-провайдеров, то это происходит примерно так. Вы добавили на свой сайт новый раздел, робот узнал о его наличии из файла sitemap, начал обращаться, совершать по 3-4 запроса в секунду, хостер это видит и начинает отвечать на запросы робота медленнее, блокируя возросшую активность. Робот, видя, что сайт начинает медленнее отвечать, уменьшает количество запросов, думая, что это он влияет на работу сайта, соответственно частота и скорость обновления вашей информации в поиске падает.
Проверяйте HTTP-коды ответа. Всем известно, что доступные страницы отвечают кодом 200, но если ваш сайт начинает отвечать кодом 500, 503, 502, робот также снижает количество обращений к вашему сайту, потому что думает, что сейчас либо проводятся какие-то работы, либо сайт занят и к нему лучше обращаться пореже. Обязательно проверяйте коды ответа.
Очень важна скорость ответа сервера (возврат первого и последнего байта). Осуществляя проверку, нужно учитывать, что сервер должен быстро отвечать не только на запрос одной страницы в несколько секунд, но и нескольких страниц в секунду. То есть, готовьтесь к тому, что при добавлении нового раздела, робот может увеличить частоту обращений. Если сервер отвечает медленно, то соответственно индексирующий робот будет реже к нему обращаться.
3. Файл Sitemap
Вопрос: При добавлении нового раздела на сайте (или же при проблемах с индексированием сайта) имея целью скорейшее его индексирование, правильным ли решением будет составить sitemap.xml таким образом, чтобы в нем были только непроиндексированные страницы?
Из вариантов – указывать в sitemap.xml уже существующие страницы или только новые страницы, можно выбрать любой. Индексирующий робот, получая ваш sitemap со списком всех страниц, проверяет, какие страницы были известны ранее, а какие страницы только что появились на сайте. Соответственно, получив список новых страниц, он начнет их индексировать, независимо от того, есть ли этот отдельный файлик с новым разделом.
Новый раздел на сайте может появляться не только при постепенном добавлении информации на сайт, он часто появляется и при редизайне и при смене структуры сайта. Эти вопросы также довольно часто задают службе поддержки, поэтому предлагаю небольшой чек-лист для вебмастеров, который желательно использовать при смене дизайна, либо структуры:
• При смене адресов использовать только 301-й постоянный редирект
• XML-карта (sitemap)
• Проверять нужные страницы на доступность в robots.txt
• Следить за наличием мета-тегов, доступностью необходимых текстовых блоков, аккуратно с JavaScripts
• Проверять noindex и rel=“canonical”
• Следить за битыми ссылками





