
23 апреля в рамках конференции РИФ+КИБ 2010, во второй части секции «Поиск: настоящее и перспективы», дружный коллектив авторов во главе с Александром Садовским порадовал участников конференции серией нано-рассказов о технологиях поиска Яндекса.
Роман Поборчий. Оценка поиска
Интернет, как известно, состоит не только из одних пластиковых окон, партнерских систем, кондиционеров и хомячков. Существует еще много разных вещей, которые приходится искать.
Шимпанзе - это групповые животные. Поэтому изучать поведение одного шимпанзе нет никакого смысла. Один шимпанзе – это вообще не шимпанзе. Так и один поисковый запрос – это еще не качество поиска.
Поиск – это сложная система, и поэтому, как его не настраивай, как его не улучшай, все равно найдутся такие поисковые запросы, на которые поисковая машина отвечает плохо. Поэтому говорить о поиске, основываясь на одном, двух, трех или пяти запросах – не имеет смысла. Мы строим оценку качества на выборках из нескольких тысяч запросов. С каждым из этих нескольких тысяч запросов нужно что-нибудь сделать, то есть посмотреть, а хорошо или нет поисковая машина на него отвечает.
Существует аксиома – что хороший поиск, это когда пользователь находит именно то, что искал. Ну, и чтобы при этом ему еще не было плохо, чтобы всякая реклама с девушками и конями не лезла ему в глаза, чтобы его не ругали, и чтобы при этом он не чувствовал себя идиотом.
Поиск – он многомерен, и есть много разных причин по которым пользователь может не найти то, что искал. Мы пока что не умеем измерять все эти причины интегрально, и поэтому приходится анализировать много разных срезов, и некоторые из них я сейчас вам продемонстрирую.
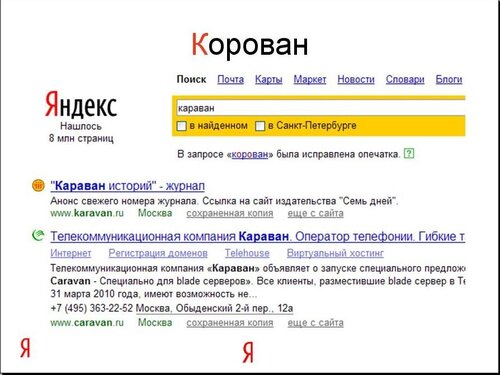
Вот например запрос «корован». Вы видите, что нами была исправлена опечатка. В результатах поиска мы видим – журнал «Караван историй», телекоммуникационная компания Караван, ниже есть еще тверской еженедельник «Караван». Вопрос: хорошо это для пользователя или нет?
На самом деле все зависит от того, существует ли действительно в природе слово «корован».
Введя его в строку запроса во множественном числе, обнаруживаем, что совершенно точно существует слово «корованы», их еще можно грабить.
И понятно, что тот, кто интересовался этим понятием, был наверняка совсем не удовлетворен нашими многочисленными «караванами», которые мы ему подсунули на странице результатов поиска. Но с другой стороны, наверняка есть люди, которые ищут обычное слово «караван», просто не знают, как оно правильно пишется. В общем, либо грамотный пользователь найдет себе что-то хорошее, либо неграмотный пользователь тоже найдет себе что-то хорошее. Вот такой вот неоднозначный запрос.
Также, если мы возьмем запрос «Наполеон», мы тоже увидим какие-то результаты. Но все эти результаты, к сожалению, касаются только Наполеона Бонапарта, Наполеона-торта категорически нет – и это, я считаю, неправильно. Как нет и Наполеона-коньяка, но я знаю, что ищут его значительно меньше, чем Наполеон-торт.
Теперь мы точно знаем, что соответствие только одного результата запросу – это полезно, это интересно, но недостаточно, поэтому выдача должна быть разнообразной.
К вопросу о разнообразии можно рассмотреть запрос «флора». Мы увидим в результатах «флора из винкс», компания Флора-сказ, группа Флора и так далее. Без «флоры из винкс» эта выдача была бы плохой, а вот с «флорой из винкс» – она хорошая.
Если кто-то в детстве играл в шахматы, то он наверняка читал книжки В.В. Смыслова. По запросу «Смыслов» есть статья, и под ней есть вот такой вот прекрасный сниппет. И все было бы нормально. На самом деле В.В. Смыслов умер 27 марта этого года. И наш сниппет очень долго был старым и не отображал этого, хотя в Википедии это было своевременно отражено. Вот этот пример говорит о том, что даже если сами результаты нормальные, и в них есть вся информация, то количество сниппетов это тоже отдельный срез, который тоже нужно как-то измерять. Это еще одна вещь, которая влияет на то, нашел пользователь то, что искал, или не нашел. Но на самом деле это еще про свежесть выдачи, о которой будут говорить дальше мои коллеги.
Поиск очень многомерен и приходится смотреть несколько тысяч запросов, и по каждому из них смотреть разные проекции. Ну а потом мы некоторое время думаем и говорим – ну да, наверное, неплохо получилось.
______________________________________________
Языковая структура. Виталий Титов
Я буду говорить сегодня о морфологии. Она находится в документах, содержащих слова из вашего запроса. Иногда они могут содержать не те слова, не совсем те слова или совсем не те слова, но оказывается, что документ вполне может быть по теме вашего запроса.
Морфология должна найти те слова, которые можно искать вместо заданных, и понять насколько они хороши для того, чтобы ранжировать заданное.
Иногда морфология совсем не нужна. Вот, например, искали вы «детскую поддержку», и без всякой морфологии нашли подробную инструкцию, куда прикладывать руки, и все – все довольны.
Иногда без морфологии можно обойтись. Но обычно приходится искать не по исходной форме слова, но и по всем другим формам этого слова, не только в русском языке, но и в украинском, беларусском, казахском. Обязательно нужно убирать неоднозначность и разбираться в том, что же интересует пользователя.
Иногда даже приходится смотреть не на сами запросы, а смотреть на тексты, чтобы разобраться в том, что же там на самом деле имелось в виду. Вот запрос, который для нас представлял в свое время большую сложность – это «ваза».
По этому запросу находили большое количество документов, содержащих – «тюниг ваза», «сервис ваза», «все для ваза». И, только благодаря этому мы поняли, что речь может идти не только о сосудах. Именно поэтому мы смогли сегодня сделать такую емкую выдачу.
Но искать просто все формы слова бывает недостаточно. Иногда приходится использовать и другие слова. Чаще всего это самые близкие слова – однокоренные. Но следует помнить о том, что нужные слова можно записывать кириллицей, можно латиницей, можно сокращать, можно шифровать, цифры можно записывать буквами, можно цифрами. Без расшифровок все равно никак.
______________________________________________
Качество поиска. Денис Расковалов

Мне хотелось бы рассказать о том, что нам представляется самым важным за предыдущие год-два, и о том, что мы будем делать в будущем.
Сегодня уже прозвучал один доклад, посвященный «серебряной пуле» в поиске. Что такое «серебряная пуля» в поиске? Это когда мы придумываем и делаем что-то, откуда-то извлекаем какие-то данные – и бинго! мы имеем супер-поиск. Нет, серебряной пули нет, но есть такая мета-серебряная пуля.
Кажется, что улучшить качество ранжирования можно за счет вовлечения в него всей той информации, до которой мы только можем добраться. Приведу простой пример, еще сравнительно недавно, лет десять назад, те поисковики которые существовали, использовали только текст документа. Представим себе, что первым, кто использовал не только текст документа, был Google. Подтянув к своей выдаче дополнительную информацию, поставив линки, он качественно улучшил результаты своего поиска.
Есть и другой пример. На самом деле знание о том, что МГУ – это Московский Госуниверситет нужно тоже уметь использовать неочевидным образом. В любом случае, поиск, который знает, что МГУ и Московский Государственный Университет – одно и то же, однозначно лучше того, который этого не знает.
Если бы я не был скован временными ограничениями, я бы мог часами рассказывать о том, какую информацию еще можно подтянуть к ранжированию, и сделать ее лучше. Но сейчас я этого делать не буду.
Итак, какой подход мы попробовали и реализовали для того, чтобы решить «проблему мета-серебряной пули», или интеграции всех источников информации? Мы используем для этого машинное обучение. Мы формируем некоторые правила – какая страница релевантна, какая нерелевантна, что хорошо, а что плохо. После этого всю информацию, до которой только можем дотянуться, предлагаем машине, и уже она, пользуясь этой информацией, пытается угадать – релевантна страница или нет, хорошая она или плохая.
Прелесть всей конструкции в том, что нам уже не нужно искать для каждого нового типа информации способ ее использовать, не нужно в каждом случае придумывать сумасшедшие правила – типа, если вопрос коммерческий, то тогда необходимо отранжировать сайты по цене товарного предложения, если текстовый - то по-другому. Теперь такого рода правила придумывает за нас машина.
Что вообще нужно для того, чтобы сделать «мета-серебряную пулю»? Как я уже говорил, совершенно необходимо машинное обучение. Качественное, хорошее обучение, которое часто угадывает оценку и которое предъявляет минимум требований к факторам ранжирования и что важно - к самим оценкам. Потому что оценки всегда будут грязными. Процессоры всегда ошибаются, и предвидеть эти ошибки невозможно, и факторы ранжирования тоже всегда будут грязными. Всегда будет спам в пейджрамке, всегда будут искусственные ссылки, это все грязь, с которой просто нужно уметь жить.
Еще что нужно? Нужен очень быстрый способ оценить, на сколько хороша та или иная информация. Вот, например, появилась та или иная гипотеза, ее нужно оценить за час-два и либо принять, либо отбросить. И таких гипотез можно сформировать тысячи, внедрить сотни, а при помощи этих сотен маленьких вещей значительно улучшить качество поиска.
Что такое МатриксНет? Это вершина того, над чем мы работаем и того, что мы создали. Это система, которая позволяет нам быстро и эффективно работать и строить хорошее ранжирование. Что я имею в виду? Не буду говорить, что МатриксНет самый лучший для машинного обучения, но есть независимые соревнования, в которых он занимает первые 5 строк.
Какие у него есть хорошие свойства? Во-первых, он устойчив к грязи, и в данных и в оценках, во-вторых, требует минимум действий. То есть большую часть работы по обработке данных он берет на себя. Например, уже не нужно искать способ, как число ссылок превратить в релевантность, он догадывается до этого сам. Еще он очень быстр. В общем, хорошая штука.
Выдачу поисковика по запросам можно охарактеризовать каким-то числом. 1- это когда пользователь полностью удовлетворен результатами поиска, а 0 – это когда вообще ни один пункт на странице не отвечает запросу пользователя. Как мы вообще оцениваем, какой поиск лучше, какой хуже. Невозможно совершить однозначное улучшение качества поиска по всем запросам сразу. Неизбежно какая-то часть улучшится, какая-то ухудшится. И нужно стараться только, чтобы та часть, в которой произошло улучшение, была больше.
Мы берем большое количество запросов – несколько тысяч. Мы тщательно проверяем их, и смотрим, чему равна разница в качестве поиска по каждому запросу, сортируем их. Правая часть запросов, которая окрашена красным цветом – ухудшилась, с изменением качества поиска, а зеленая – улучшилась. Мы видим, что две трети запросов улучшилось, а одна только треть ухудшилась, и это круто.
Что видят пользователи? Мы измеряли качество МатриксНет на бакетах, а как только поняли, что наше ранжирование лучшее, сразу же его выкатили. Сначала мы его выкатили в России, потом в Казахстане и Белоруссии. Улучшение качества поиска доказывает и стремительный рост трафика генерации Яндекса в Белоруссии. Внедрили мы матрикснетские формулы в Белоруссии примерно в середине декабря, и сразу после этого доля трафика генерации Яндекса стала расти, то есть мы стали лучше нашего конкурента по качеству поиска.
На самом деле ни один человек в мире не может сказать, что на трафик генерации Яндекса в Белоруссии повлияло внедрение матрикснетовских формул. Можно задать такое задание для менеджера, найти десять правдоподобных причин, объясняющих, почему трафик генерации может вести себя именно так. Факт остается фактом – именно с улучшением качества поиска и связана положительная динамика трафика генерации Яндекса в Белоруссии.
Что же дальше? До этого мы говорили о ранжировании, о запросах, о каком-то интегральном качестве по запросу, что делать дальше? Во-первых, нужно вносить в поиск какие-то фишки. Что значит «фишки»? Ну, например, все мы знаем, что в одну из суббот упал лайнер с польским президентом. Понятно, что хороший поисковик это тот, который способен предоставить информацию об этом за минуты. Это на самом деле не укладывается в качество поиска, а этим нужно заниматься.
Что нужно привносить в поиск. Например, нужно делать так, чтобы результаты, которые находит пользователь, например, магазины – находились рядом с ним, ну если ему это требуется.
Нужно не создавать морфологических глупостей.
Иными словами, в поиске есть много аспектов, которые не укладываются в обычную модель. И по всем по ним нужно добиваться значительного улучшения.
Одним из очевидных путей улучшения качества поиска в целом является умение выделять и понимать, что и в какой пропорции нужно пользователям: – хотят ли они скачать видео, найти новости, найти товары; и добиваться того, чтобы поисковик идеально предоставлял всю информацию по конкретным классам запросов.
Совершенно очевидно, что по запросам видео на SERPe должна быть возможность посмотреть нужный видеоролик, а в случае товарного запроса, можно было совершить покупку требуемого товара за один клик. Очевидно, что поиск должен быть разным для разных запросов.
Этим мы занимаемся, и будем заниматься.
______________________________________________
Региональность. Иван Наймушин

Достаточно долгое время мы смотрели на запросы пользователей из разных регионов, на то, как они себя ведут на выдаче, и давно уже у нас чесались руки сделать так, чтобы выдача различалась для разных регионов. Результаты поиска, саджест и др. элементы выдачи – должны учитывать регион пользователя, причем для разных городов внутри России для части запросов (15-30%). Ну и для других стран конечно тоже, почти для всего потока.
Но надо отметить, что даже для каждой страны поведение различается очень сильно в зависимости от менталитета. Вот, например, если на Украине интернет довольно таки развит, и там даже можно с украинских хостингов что-то покачать, то в Беларуссии интернет развит слабо, и белорусы вполне довольны российскими хостингами.
Для того, чтобы проиллюстрировать ситуацию, и доказать, что запросы пользователей различаются в зависимости от региона, давайте посмотрим из какого региона и какие именно запросы пользователи задавали о том, где они хотели бы отдыхать.
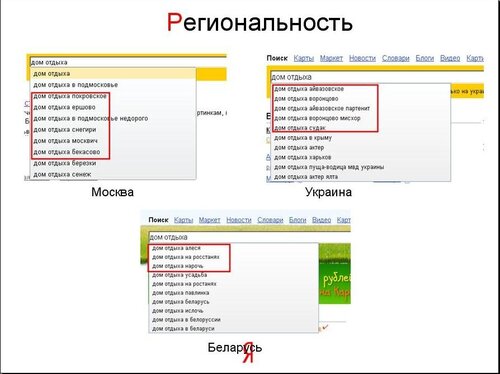
Кажется, предельно ясно, что левый верхний угол - это Москва. А правый верхний угол – это Украина. А внизу – это Беларусь. То есть, это видно по запросам, людей интересуют местные дома отдыха, именно свое родное больше всего.
В процессе работы над этой проблемой, а проблема довольно-таки сложная была, у нас родилось два подхода к ее решению.
Подход номер один: собрать необходимый объем региональных оценок, сделать региональные факторы, то есть такие факторы, которые зависят от региона документа и от региона пользователя. Обучиться на всем потоке запросов. И, с учетом этих факторов, получить некоторое ранжирование. Вот, в результате этих действий, у нас получился релиз Арзамас, и таким же способом мы сделали ранжирование для всех существующих стран – Украины, Белоруссии, Казахстана.
Подход номер два. Опять же, необходимо взять необходимый объем региональных оценок и региональных факторов, выделить отдельно те запросы, на которых действительно нужна региональность, и обучиться отдельно на том потоке, на котором региональность нужна, и на том потоке, на котором региональность не нужна. В результате у нас получилось несколько последующих релизов, но ранжирование уже поменялось.
В зависимости от того, является ли запрос геозависимым, мы предлагаем пользователю либо единую выдачу внутри страны, либо разную.
В общем-то, как я уже сказал, подход первый хорошо подходит для стран, особенно когда у вас есть много оценок, у вас есть достаточно большая выборка для обучения. А подход номер два, он даже может быть является немного вынужденной мерой, и подходит для региональности внутри страны, потому что мы не можем собрать полноценный оцененый поток от какого-то одного конкретного города. Интернет в каждом небольшом городке развит слабо, в отличие от московского он так хорошо не пролинкован, то есть там оптимизации нету вообще в принципе, и ссылки ставят мало. Поэтому там подход номер два работает гораздо лучше.
В тоже время, если пытаться распространить его на страны, то для каждой страны нужен свой классификатор локализуемости. Так, например запрос «мега», он в России, в частности в Москве, означает Мегафон, а на Украине – это не локализуемый запрос, хотят покачать.
Ну вот, в результате наших действий, если год назад выдача была для всех достаточно однообразной, то сейчас она отличается, и для каждого региона - своя.
_______________________________________________
Свежесть поиска. Федор Романенко
Вебмастера очень внимательно следят за так называемым апдейтом поисковых систем, когда в поиске появляются новые документы, или очень сильно меняется ранжирование, все переставляется местами. Ну и те, кто знает про технологию процесса, знают, что многие вещи, такие как глобальные пйджрамки или статистики можно посчитать только на всем интернете, и те машины, которые обрабатывают десятки миллионов данных, должны пользоваться какими-то сортировками, и обрабатывают документы пачками.
Именно поэтому все поисковые машины начинают с того, что они выкладывают индекс с некоторой регулярностью. Но в последние годы стало как бы правилом хорошего тона доносить до поиска документ очень быстро, то есть за минуты, а иногда даже за секунды. И, видимо, в ближайшие годы это будет абсолютной нормой.
Сейчас в интернет приходит все больше людей, и они в интернет ходят не как в библиотеку, а они практически в нем живут, и, как мы наблюдали, пользователи вообще не понимают разницы между интернетом и индексом поисковой машины. Они считают, что если URL какой-то есть, и на нем что-то написано, то он должен тут же находиться в поиске. Мы хотим постараться не разуверить пользователя в этом заблуждении, хоть для того, чтобы дотащить до поиска за минуты документ, нужно сделать кучу вещей.
Нужно, во-первых, обнаружить факт его существования, нужно понять, что он вообще заслуживает какого-то внимания, потому что документов в интернете бесконечное множество. Затем нужно его скачать, проиндексировать, просчитать все поисковые фичи и доставить на поиск. На самом деле на это уходит какое-то время, но в принципе, возможно это делать за минуты или даже за секунды.
На самом деле доставить документ за минуту на поиск это еще даже меньше чем полдела, нужно еще понять, как его отранжировать, и вообще в каких случаях пользователю нужны свежие документы.
Пользователь, когда приходит на поиск, он на самом деле что-то пишет, обычно очень мало, и при этом что-то имеет ввиду, и мы не всегда это знаем. Если мы говорим про свежесть, то пользователи в одно-двух-трех процентах случаев могут хотеть найти что-то про свежие события, и мы обязаны догадаться. Почему?
Потому что представьте себе - есть огромный индекс интернета, и есть одна маленькая тысячная его часть, которая появилась за сегодняшний день. Значит, если пользователь хотел узнать про свежее, ему ни один результат из этой огромной базы не будет релевантен. И, соответственно, если мы не правильно поймем, что пользователь хотел искать свежее, и начнем выдавать ему только свежие документы, то вероятность, что мы найдем там самое релевантное, ничтожно мала. В связи с этим практически все поисковики, и это единственная возможность, пытаются определить свежесть запроса. И для этого все средства хороши, можно смотреть на новости, можно смотреть на тренды в твиттере, частоты запросов и так далее. Там очень большое количество разных возможностей.
Сейчас есть такая новая традиция, которую все поддерживают, показывать такой риал-тайм SERP, когда вы смотрите, и на ваших глазах приезжают новые документы и у вас создается такое удивительное ощущение, так называемый эффект присутствия, как будто вещи происходят прямо при вас, и вы становитесь свидетелем. Но потом, когда эта эйфория проходит, приходится задумываться, насколько это полезно.
Безусловно, это бывает полезно. Например, если событие произошло только что и какие-то очевидцы через твиттер, прямо с поля действия сообщают вам то, что происходит. Но по подавляющему числу запросов на самом деле, это скорее просто игрушка.
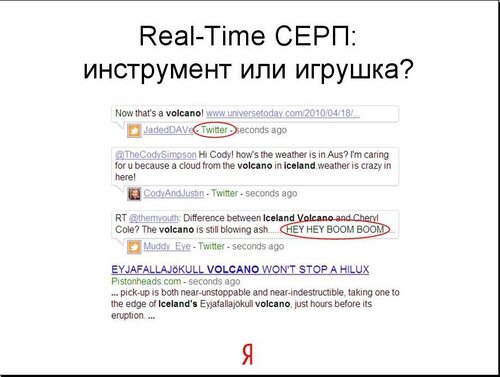
Вот мы здесь видим, кто-то шутит про вулкан, например, ну что, забавно, но не приносит нам много информации. И соответственно, мы все больше начинаем понимать, что наш любимый и популярный Твиттер это, в первую очередь, не то чтобы риалтаймовая система, это очень хороший выбор контента, и результат действия отдельных людей, которые потратили время на то, чтобы выделить интересную информацию. То есть Твиттер – это в первую очередь, конечно, ссылки. Иногда это риалтаймовая выдача.
_______________________________________________
Представление сайта в поиске. Ольга Остренкова
Поисковая выдача среднестатистического поисковика выглядит достаточно однообразной. Понятно, что на самом деле там осмысленный читаемый текст, который человеку обычно понятен, и даже в случае, когда этот текст хороший, читаемый и удобный, вот такая вот выдача, она достаточно безликая, не за что зацепиться глазу. У пользователя нет возможности быстро и легко выбрать результат из тех, что ему представлены. И у владельца сайта нет никакой возможности выделится, кроме как написать очень большими буквами, что у него дешевле всех можно купить какой-то товар. Я хочу немножко рассказать о том, какие шаги мы делаем в направлении разноображивания представления сайтов. Мы все это вместе объединяем под заголовком «структурированные данные в результатах поиска», хотя здесь, в общем-то, не совсем все про тот самый структурированный веб, и про семантический веб, но тем не менее.
Пример первый, и всем тем, кто пользуется Яндексом, давно известный. Это вавиконки, которые мы показываем рядом с результатами поиска. Мы знаем, что есть сайты, которые сами по себе брэнды, люди узнают их вавиконки, и кликают на результаты с этими фавиконками, еще не прочитав заголовка. Таким примером является Википедия. Если вы видите букву W в выдаче, вы иногда можете не читать заголовок, вы знаете, что там, за кликом, вы найдете ответ на ваш вопрос и описание того термина, который вы искали. Фавиконки берутся из стандартного файла, и это в общем-то уже стандарт по всему Рунету, размещать их похожим образом. Поэтому мы используем именно те картинки, которые сами вебмастера считают правильными для описания своего сайта.
Пример второй. На основании анализа структуры сайта и структуры переходов по нему, мы можем выделять, во-первых, разделы сайта - понимать из чего состоит меню верхнего уровня, во-вторых, понимать, какие из этих разделов нужнее, полезней, интересней пользователю. Представление этого в результатах, это не только способ показать пользователю, что будет на этом сайте, из чего он состоит, потому что очень часто навигация очень хорошо описывает из чего сайт состоит; но и в некоторых случаях сокращение клика. Мы формируем быстрые ссылки на основании работы наших алгоритмов, но, тем не менее, мы позволяем вебмастерам редактировать их. В нашем сервисе Яндекс.Вебмастер можно отказаться от их показа, если вебмастеру почему-то это не нужно.
Это еще один пример того, что делается на основании анализа структуры сайта. Это запущенный буквально сегодня функционал - навигационная цепочка вместо ссылки. Разделы, которые вы видите, написаны русским языком, это реальные разделы сайта, которые ведут к той странице, которую мы нашли, сами буковки кликабельны и ведут на тот раздел, которому соответствуют.
Это были примеры того, что мы можем выделять сами на основании анализа сайта. Теперь пример того, что мы понимать пока сами, к сожалению, не можем. Это то, каково название домена сайта и из чего оно состоит. Поэтому мы предлагаем вебмастерам самим указывать, каким образом показывать название их сайта в результатах поиска. Ну, в данном случае так настроено, что две буквы в названии домена пишутся заглавными, так для примера, сравните читаемость названия домена. А редактирование этого возможно в сервисе Яндекс.Вебмастер, там указываете, что вам нужно, есть некоторые запреты, например, на размещение всех заглавных букв, но тем не менее свободно, как вы считаете нужным.
Про региональность здесь немножко уже говорилось, мы показываем регион найденного результата, рядом с этим результатом, там, где считаем это уместным. Регионы сайтов также определяются автоматически, но если наши классификаторы ошибаются, вы можете это исправить, опять же, с помощью сервиса Яндекс.Вебмастер.
Чуть более тонкая региональность, а конкретно адреса конктретных организаций. Когда мы знаем что сайт, это сайт организации, у которой есть офф-лайн воплощение в реальном мире, а значит, есть какой-то офис, куда можно реально прийти или позвонить, мы показываем рядом с результатом поиска соответствующий адрес. И этот адрес иногда даже умеет красиво разворачиваться в карту.
Базу данных таких адресов мы пополняем из разных источников, в том числе передать свой адрес нам может сам владелец сайта. Недавно мы запустили анализ микроформата пейджкарт, который позволяет размещать адресные данные, тоже из него извлекаем адреса.
Есть у нас такие вот выделенные типы организаций, которым мы сделали специальные, особенно красивые сниппеты, это гостиницы. Структурированная информация о гостиницах также нами собирается, хранится отдельно и привязывается к сайту там, где это уместно. Точно также владелец гостиницы сам может настроить себе эти данные, или отказаться от такого сниппета, если ему почему-то это не нужно.
И еще несколько примеров красивых сниппетов, структурированных – это сниппеты для видеохостингов, наверное все знают, что мы показываем в результатах поиска видео, и проигрываем ролики прямо на выдаче, пользователю от этого большая польза, возможность отличить тот ли ролик нашелся и отличить результаты с реальным роликом, от каких-то списочных страниц, ну и вебмастеру возможность выделиться.
Так же мы делаем красивые структурированные сниппеты для блогов. Все нужные данные заполняются самим пользователем, владельцем блога, в соответствующей карточке на блогохостинге, блогохостинги проддерживают формат разметки, который мы понимаем и читаем.
Ну и еще полезное нововведение для сайтов с рецептами. Мы понимаем, что страница содержит рецепт, делим его на составные части, ингредиенты, продукты и способ приготовления, и формируем сниппет по некой схеме, а не как обычно, выбирая просто кусок текста.
Кроме того, знание про страницы, атрибутирование страниц, то то, что именно представлено на них, мы, конечно, накапливаем в наших сервисах. И во всех этих сервисах мы приглашаем вебмастеров делиться с нами всеми своими структурированными данными и соответственно получать дополнительное представление в нашей выдаче.
Вот несколько полезных ссылок.

Практически все, о чем я сейчас рассказываю, настраивается вручную в Яндекс.Вебмастере. И мы рассчитываем, что это одно из перспективных направлений работы, понимание не текста страницы, как такового, а выделение каких-то смысловых значимых блоков, и, соответственно, использование этого знания в представлении результатов пользователю.
Если у вас есть какие-то пожелания или предложения, то можно написать на адрес рассылки, который указан в последней строчке.
_____________________________________________
Борьба с вредоносным кодом. Сергей Певцов
Я расскажу о том, что мы делаем для того, чтобы все, о чем рассказывали мои коллеги, было доступно пользователю. Вот, например, пользователь нашел какой-нибудь региональный супер-релевантный результат, перешел на него, а тут начинается такая вот штука на компьютере - все сервисы Яндекса, например, становятся недоступны, начиная от почты, и заканчивая поиском. И не только Яндекса.
Понятно, что это проявления вредоносного кода, это какой-то вирус, который был на сайте, а пользователь зашел на эту страницу, и у него начались вот такие проблемы. Не все пользователи на самом деле способны установить антивирус, не все способны его приобрести, поэтому мы подумали о том, как защитить всех пользователей, от таких вот нежелательных проявлений.
(А. Садовский в зал: - А поднимите-ка руки те, кто не способен настроить антивирус?
Ух ты, оказывается, есть такие люди!)
Поэтому чуть менее года назад, мы стали предупреждать о том, что страницы содержат вредоносный код.
Понятно, что на некоторых сайтах этот код может появиться помимо желания его владельца. Если вы, например, сохранили какой-нибудь пароль у себя в каком-нибудь клиенте, а потом зашли на какую-нибудь такую опасную страничку, то этот пароль могли у вас украсть и потом, если у вас есть собственный сайт, разместить на нем уже какой-нибудь вредоносный код, для того, чтобы заразить как можно больше пользователей. И мы не хотели бы, чтобы на хороших сайтах, таким образом информация становилась недоступной для пользователей. Поэтому мы придумали специальную безопасную сохраненную копию, которая позволяет увидеть информацию, которая на сайте содержится, но которая точно не содержит никаких элементов, в которых может содержаться ссылка на вредоносный код.
Ну и конечно, мы предупреждаем веб-мастеров о том, что какие-то такие проблемы у них случились. В сервисе Яндекс.Вебмастер вы можете увидеть ссылки на конкретные страницы, на которых мы что-то обнаружили, вы можете почитать о том, как удалить вредоносный код, и вы можете запустить перепроверку, если вы такой код нашли. Если у вас возникают все же какие-то проблемы, то вы можете сообщить в нашу службу поддержки и они с удовольствием вам помогут устранить проблему.
Ну а теперь я скажу пару слов о том, что стоит на самом деле за этими предупреждениями и сервисом Яндекс.Вебмастер.
Существует два подхода в обнаружении вредоносного кода – это сигнатурный анализ и поведенческий. Начинали мы с сигнатурного анализа: у нас есть какая-то база вредоносных объектов, и мы сравниваем элементы страницы с элементами из этой базы, и если у нас есть стопроцентное совпадение, то мы считаем что да, вот на этой странице нашелся такой-то вредоносный код. И в мае прошлого года мы при помощи антивирусного движка от компании Sofus, начали предупреждать об этом пользователей.
Если же у нас какой-то есть новый вирус, которого еще нет в антивирусной базе, то этот подход бесполезен, потому что этого кода в базе попросту нет. Здесь помогает поведенческий анализ, когда мы имитируем поведение обычного пользователя, заходим на сайт и слушаем, что происходит. Если вдруг начинают запускаться какие-то программы, или какие-то файлы начинают сохраняться нам на диск, то значит, эти продукты не натуральные. Это не натуральный сайт, не натуральная страница, а значит, скорее всего, они содержат что-то опасное. И это позволяет нам обнаруживать новые угрозы, и защищать пользователей от того, чтобы сервисы поисковых систем становились им недоступны.
_______________________________________________
Мобильный поиск. Александр Мартынов
Все вы знаете, что у Яндекса, кроме большого поиска, есть еще и мобильный.
Для начала позвольте предложить вам вопрос:
- Как вы думаете, в чем отличие большого поиска от мобильного?
Мы тоже долго спорили над тем, чем же, все таки он отличается, и, в конце концов пришли к такому выводу, что пожалуй, коренным отличием мобильного поиска является то, что это поиск на ходу. Когда потребность в какой-либо информации у вас возникает внезапно, и получить эту информацию нужно тут же, буквально не сходя с места.
Кроме этого, мы еще проанализировали запросы наших мобильных пользователей и увидели, что на самом деле подавляющее большинство этих запросов можно разделить на такие 3 большие категории: первая категория – это геозапросы, типа где я нахожусь и что вокруг меня, вторая категория – справочная информация, и третья категория – это запросы типа чем себя занять и как убить время.
Сейчас я продемонстрирую, как мы эти три вида потребностей удовлетворяем.
Первый тип запросов (где я и что вокруг меня). Можно задать с любого телефона запрос, например «кафе на арбате», и в основной выдаче вы увидите информационный блок, где действительно есть кафе на Арбате.
Если вы пользуетесь нашим приложением Мобильный Яндекс, который еще умеет распознавать ваше местонахождение, то поиск становится еще более простым. Можно набрать просто слово «нотариус» или то же самое «кафе», и поиск покажет тот набор организаций, который находится в непосредственной близости от вас, и даже выведет цифру, насколько близко нотариус или кафе от вас находится.
Следующий тип запросов, тоже достаточно распространенный, это заказ такси. Казалось бы – что такого сложного в том, чтобы заказать такси, но тут есть один момент, что вот эти организации, которые мы выводим в результатах поиска, начинаться будут именно теми службами такси, которые находятся в том городе, откуда был сделан запрос.
Второй тип запросов - справочная информация. Пожалуй, самый популярный запрос не только в мобильном, но и в большом вебе – это погода. У нас узнать погоду проще всего, - выводится просто погода для вашего города. Сегодня это было особенно актуально, я набрал утром в своем мобильном «погода», мне показали, что будет дождик, и я взял зонтик, а кто не пользуется мобильным яндексом, тот сегодня промок.
Следующий очень полезный запрос, это для людей, которые часто ездят на электричках. Выводим электрички и станции назначения. Вы имеете список электричек и время, которое осталось до ближайшего отправления. Так же, полезным бывает такой запрос, если вы зашли в магазин, хотите приобрести какой-то товар, например, телефон, если этот товар есть в нашем маркете, можно вбить номера этого товара, и мы вам покажем информационный блок, в котором будут представлены ссылки, где можно у нас купить этот товар, и будет представлена информация о разбросе цен на эту модель. Это позволит вам прикинуть, насколько адекватная цена и стоит ли покупать именно там.
Ну и категория запросов «чем себя занять?». Наверное, самый полезный из всех информационных блоков, это новостной информационный блок. Я не буду в подробностях объяснять, как он срабатывает, там достаточно нетривиальный алгоритм. Но могу только сказать, что если вы введете какие-то ключевые слова свежей новости, то с большой долей вероятности вы увидите этот блок, и тут по ссылкам сможете пройти и прочитать подробности. Причем, ссылки мы конечно же подбираем такие, чтобы навести на источники, которые было бы удобно читать с маленьких экранов.
И даже если вам ничего не надо узнавать, вы просто хотите отдохнуть, все равно есть что поискать в нашем Мобильном Яндексе. Можно вводить просто абстрактные запросы, типа «море», «небо», «анжелика варум», «анджелина джоли», и после этого вы сможете расслабиться и получать удовольствие от просмотра красивых картинок. Для пущего удобства у нас есть сервис, называется Ресайзер, мы картинки выводим на весь экран, то есть, если у вас хороший большой смартфон, то смотреть будет очень удобно.
Это были самые интересные информационные блоки, мы их называем колдунчики, потому что там вот магия всегда какая-то присутствует, когда они показываются. На самом деле их гораздо больше. И мы продолжаем их активно разрабатывать и внедрять, и стараемся охватить как можно большее количество таких специфических мобильных запросов пользователей, вот такими релевантными ответами.
_______________________________________________
Мультимедиа-поиск. Дмитрий Беляев
Ни для кого не секрет, что веб – это не только тексты, это еще большое количество мультимедийной информации, это видео, это музыка, и веб поиск в общем-то уже давно перестал быть только поиском по текстам, а стал своего рода проводником в мультимедийный космос веба.
Я расскажу вам о том, как мы это делаем, немножко приоткрою завесу тайны.
Так как мы, в общем-то, знаем, что по многим запросам (их в потоке больше 15%) иногда не только полезно, но и просто необходимо, не только прочитать, но и увидеть, послушать, посмотреть видео, - эти запросы мы очень хорошо умеем выделять.
Например, многие запросы задаются в поиске по изображению чаще, чем в поиске по вебу, очень часто по таким запросам пользователи, после того, как они ввели свой запрос на поиске, переходят на поиск картинок, поиск видео. Иногда пользователи могут просто явно указывать, что им нужно именно то или иное изображение. Но рассказ будет не об этом.
Традиционные поисковые системы, практически все, которые индексируют изображения в интернете, делают это по текстовому описанию. То есть это тексты alt, тексты ссылок на картинки, слова, взятые из урлов, текст, который окружает картинки, вставленные в текстовые документы, то есть прикартиночный текст. Но очень часто, чтобы улучшить качество поиска, чтобы найти именно то, что нужно пользователю, естественно необходимо понимать, что именно изображено на картинке.
Вот, например, запрос: «сборная россии по футболу». Допустим, пользователя интересует не вся сборная, а какие-то конкретные игроки. Он хочет посмотреть именно портретные изображения. Пользователь переходит в картиночный поиск и хочет найти портреты футболистов. Для этого мы сделали так называемый портретный фильтр, который оставляет в поиске только портретные изображения.
Как это сделано. Работа фильтра складывается из двух этапов. На первом этапе мы оставляем только картинки, которые содержат лица, но это еще не портрет. На втором этапе мы хотим оставить именно портретные изображения, для этого картинки с лицами размечаются на портретные и непортретные, мы просим асессоров оставить только портретные изображения, и по величине лиц, по количеству лиц, по их положениию, настраиваем классификатор так, чтобы классификатор оставлял в выдаче только те изображения, которые с точки зрения пользователей являются портретными.
Не всегда это одиночные портреты, бывают и групповые портреты, и если пользователь включит по запросу «сборная россии по футболу» портретный фильтр, то действительно в выдаче останутся только портреты футболистов.
Самое интересное – портретный фильтр можно использовать нетрадиционным способом. Вот допустим пользователь ввел запрос «айсберг» и хочет понять, допустим, с каким человеком этот запрос ассоциируется. Как вы думаете? Если мы включим портретный фильтр, кто останется? Правильно – Пугачева, которая когда-то пела одноименный хит.
Допустим, вы хотите отправить новогоднюю открытку своему другу и оформить ее в виде картинки. Введя запрос, вы увидите много красивых картинок, но для того, чтобы их отправить письмом в виде открытки, они непригодны. Ясно, что для таких вот дизайнерских решений удобно использовать клипарт. Соответствующий фильтр есть в нашем волшебном поиске, вы включаете этот фильтр, и в выдаче остаются только изображения, в данном случае картинки на белом фоне, отфильтровываются они также, то есть выдаются картинки, соответствующие определенным требованиям. Ну, в данном случае требованием является белый фон, и еще есть ряд требований которые отличают клипарт от неклипарта.
Допустим, вам нужны не такие картинки, а елочки, или что-то зеленое, то есть вы хотите сделать какую-то открытку в зеленых тонах. Вы включаете фильтр цвета, это очень простая, но в то же время очень популярная фича в поиске, очень популярный фильтр, и на самом деле в реализации он не такой уж простой, как кажется.

Вот, например, две картинки – доля желтого и доля зеленого цвета в них примерно одинаковая, но левая картинка визуально кажется более желтой. Почему? Потому что желтые объекты на ней находятся в фокусе внимания, ближе к центру. На правой картинке объекты распределены по фотографии, поэтому она кажется более зеленой. Таким образом, размечая картинки и обучая классификатор, мы, в общем-то, можем пометить на какой картинке преобладает желтый цвет, а на какой зеленый.
А если переключить этот фильтр на красный, то в выдаче будут перобладать санта клаусы, деды морозы и шарики, или например даже можно найти новогодние картинки с Гарри Поттером, которые тоже в интернете присутствуют в изобилии.
Анализ содержимого изображений пригоден не только для создания каких-либо фильтров. Яндекс знает про 2 миллиарда картинок в Рунете и за его пределами, и мы еще знаем, что примерно у половины картинок есть дубликаты. То есть очень часто вебмастера или просто пользователи заимствуют, назовем это так, картинки на разных сайтах, размещают их у себя в блогах, на своих сайтах, и поэтому, примерно миллиард картинок имеет в среднем еще по 3 дубликата. Мы умеем склеивать дубликаты. Даже если пользователи обрезали картинку, если даже они провели какую-то цветокоррекцию, пережали ее, уменьшили, увеличили и так далее.
Если пользователь ввел запрос «самолет», мы в первом результате тут же показываем, что есть несколько изображений разного размера. Перейдя по картинке на страницу просмотра, на второй странице выдачи, мы даем возможность увидеть, на каких сайтах она размещена, и получить доступ к картинкам разных размеров.
Это и есть настоящее поисковых систем по изображениям. Что будет в будущем?
В будущем мультимедийная поисковая система научится более точно понимать контент изображения, то есть различать, что именно там изображено. И научится использовать изображение в качестве запроса. Я немножко приоткрою завесу тайны, но в будущем Яндекс даст возможность в красках нарисовать изображение, и обязательно найдет похожее на то, что вы изобразили. Это будет еще одна из возможностей поиска по контенту.