
Автор: Ольга Зарзечна – консультант по техническому SEO, создатель компании SEOSLY. Работает в области поисковой оптимизации с 2012 года.
В своей работе в качестве консультанта по вопросам технического SEO и аудитора сайтов я сталкиваюсь с большим количеством различных проблем в этой области каждый день. Некоторые из них встречаются чаще и более серьезны, другие – реже.
Список, приведенный в статье, не является окончательным или исчерпывающим, но содержит распространенные типы проблем технического SEO и советы по их устранению.
Как проверить сайт на наличие проблем технического SEO
Для выявления такого рода проблем вам понадобятся следующие SEO-инструменты:
С более подробным списком инструментов для SEO-аудита можно ознакомиться в статье.
Ниже мы рассмотрим 15 самых частых проблем технического SEO, с которыми сталкиваются владельцы сайтов. Все они приведены в произвольном порядке. Некоторые из них имеют более высокий приоритет, чем другие, но специалистам важно знать о них всех.
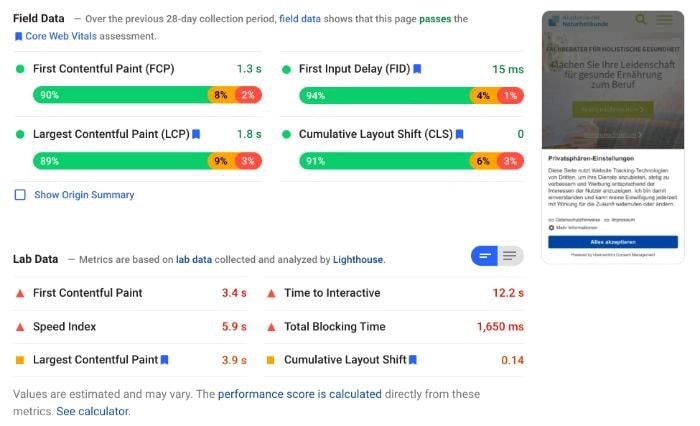
1. Сайт проходит проверку на Core Web Vitals, но только в лабораторной среде
Если сайт имеет зеленые и желтые поля по Core Web Vitals в лабораторной среде (Lighthouse), но при этом оранжевые или красные для полевых данных (Chrome User Experience Report), то у него проблемы с этими показателями.
Нередко можно увидеть, что сайт проходит проверку в лабораторных условиях, но не проходит в полевых. При этом хорошие показатели в Lighthouse у менее опытных SEO-специалистов создают ошибочное впечатление, что у сайта все в порядке, хотя это не так.
Также возможна и обратная ситуация: когда в лабораторных условиях оценки плохие, а в полевых – хорошие:
Что нужно знать о Core Web Vitals:
- Core Web Vitals, или основные интернет-показатели, – это один з четырех сигналов удобства страницы (Google Page Experience). Помимо CWV, они включают HTTPS, оптимизацию для мобильных устройств и отсутствие назойливых межстраничных элементов.
- Лабораторные и полевые данные – разные. Когда Google оценивает сайты с точки зрения Core Web Vitals, то принимает во внимание только полевые данные, то есть те данные, которые поступают от реальных пользователей сайта. Поэтому при оптимизации для CWV необходимо ориентироваться на полевые данные (CrUX), которые доступны в PageSpeed Insights и отчете об основных интернет-показателях в Search Console (если сайт получает значительный объем трафика).
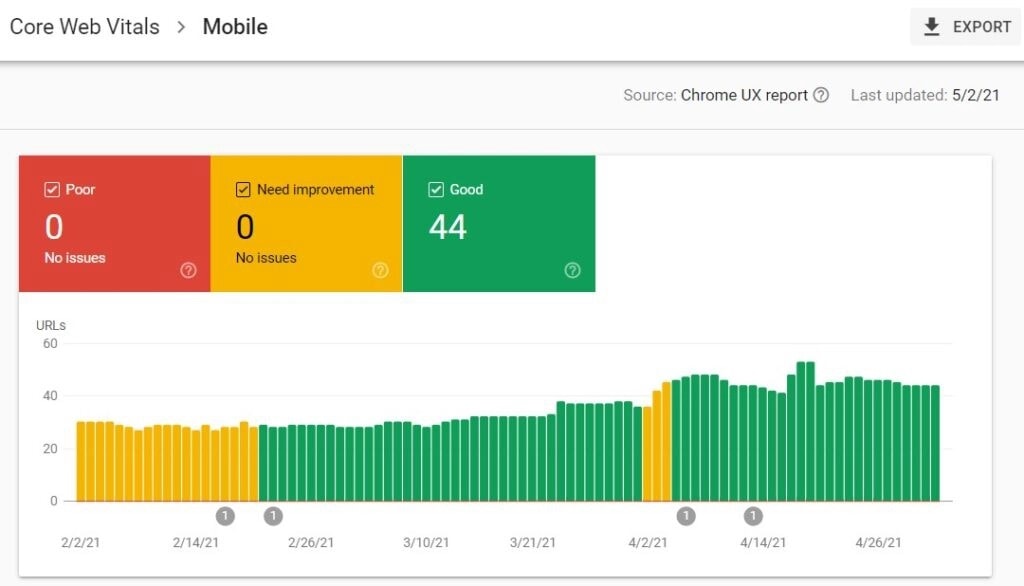
- PageSpeed Insights – это отличный инструмент для проверки показателей Core Web Vitals по отдельным страницам. При этом отчет в Search Console позволяет определить группы страниц с похожими проблемами.
Как устранить эту проблему?
Разница между лабораторными и полевыми данными может иметь разные причины и единственно верного решения для этого нет. Что можно сделать:
- Проанализируйте каждую проблему в отчете об основных интернет-показателях в Search Console и определите группы страниц с похожими ошибками.
- Проверьте примеры страниц из каждой группы в PageSpeed Insights, чтобы получить советы о том, что нужно оптимизировать.
- Выясните, какой из показателей Core Web Vitals является проблемным для указанной группы страниц? и определите тактики оптимизации.
Рекомендации по улучшению этих показателей можно найти в статье.
2. Блокировка ресурсов сайта в robots.txt
Если ресурсы сайта, такие как изображения, JS-файлы и/или CSS-файлы заблокированы в robots.txt, то краулеры не cмогут правильно отобразить страницу.
Googlebot и другие поисковые роботы не только сканируют, но и визуализируют посещенные страницы, чтобы иметь возможность видеть все их содержимое, даже если на сайте много JavaScript.
Ниже – пример такой неправильной реализации:
User-agent: *
Disallow: /assets/
Disallow: /images/
Блокируя определенные ресурсы в robots.txt, вы делаете невозможным их сканирование и корректный рендеринг страницы. Это может приводить к нежелательным последствиям, таким как проблемы с индексацией и более низкие позиции в выдаче.
Как устранить эту проблему?
Решение будет довольно простым. Все, что вам нужно, это удалить директивы disallow, которые блокируют сканирование ресурсов сайта.
Большинство систем управления контентом позволяют вносить изменения в robots.txt или настраивать правила того, как этот файл создается. Вы также можете внести изменения в robots.txt, подключившись к серверу через SFTP и загрузив измененный файл.
3. Файл Sitemap содержит неправильные записи
Файл Sitemap должен содержать только канонические индексируемые URL, которые должны быть проиндексированы Google. Большое количество ненужных URL в этом файле – это пустое расходование бюджета сканирования.
К таким записям относятся следующие:
- URL, которые возвращают код ответа сервера 5xx или 4xx;
- URL с тегом noindex;
- Каноникализированные URL;
- Переадресованные URL;
- URL, заблокированные в robots.txt;
- Повторяющиеся URL или URL, которые содержатся в нескольких файлах Sitemap.
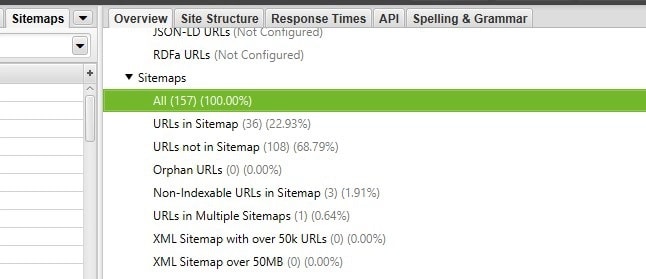
Наличие нескольких таких URL в файле Sitemap не является серьезной проблемой, но если речь идет о сотнях тысяч ненужных URL, то это определенно негативно отразится на бюджете сканирования.
Как устранить эту проблему?
Вам нужно удалить все ненужные записи из файла Sitemap, чтобы он содержал только канонические URL. В большинстве случаев файлы Sitemap генерируются автоматически, так что вам нужно будет лишь скорректировать правила, используемые для их создания.
В WordPress быстро скорректировать настройки файла Sitemap можно с помощью такого плагина, как RankMath.
Чтобы узнать, есть ли в файле Sitemap ненужные URL, можно использовать любой инструмент для сканирования сайтов.
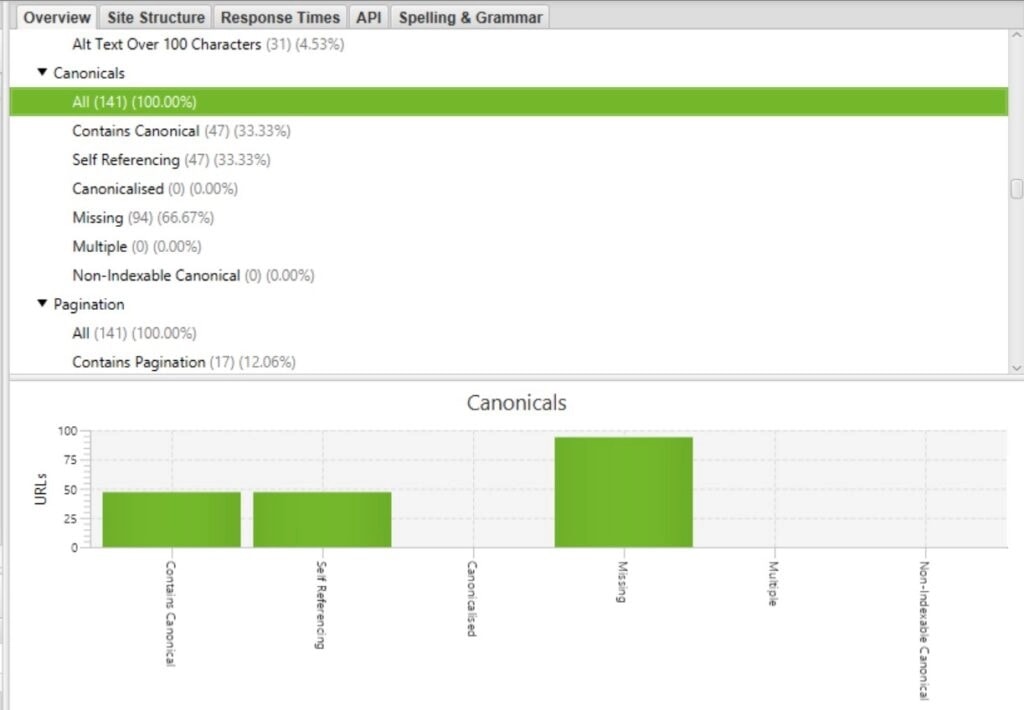
4. Некорректные, искаженные или конфликтующие канонические URL
К сожалению, существует множество способов неверной реализации канонических URL. В лучшем случае поисковая система просто проигнорирует их и сама выберет канонический URL для страницы.
Ниже – примеры неправильной реализации канонических URL:
- Атрибут rel=canonical указан в разделе <body>, а не <head>;
- Атрибут rel=canonical пустой или недействительный;
- Канонический URL указывает на HTTP-версию страницы;
- Канонический URL указывает на страницу с тегом noindex;
- Канонический URL указывает на страницу, которая возвращает код ошибки 4хх или 5хх;
- Канонический URL указывает на страницу, которая заблокирована в файле robots.txt;
- Канонический URL отсутствует в исходном коде, а есть только в обработанном HTML;
- Атрибут rel=canonical указывает на каноникализированный URL;
- Конфликтующие канонические ссылки в заголовке HTTP и разделе <head>;
- Канонические теги вообще не используются.
Как устранить эту проблему?
Исправить ее относительно легко. Все, что вам нужно, – это обновить атрибуты rel=canonical, чтобы они указывали на актуальные канонические URL.
Если вы просканируете сайт с помощью Sitebulb или Screaming Frog, то сможете точно увидеть, какие страницы нуждаются в оптимизации.
5. Конфликтующие директивы nofollow и/или noindex в HTML и/или заголовке HTTP
Если на сайте есть несколько конфликтующих директив nofollow и/или noindex в HTTP-заголовке и/или HTML, то Google, вероятнее всего, выберет самую строгую из них. Это может быть серьезной проблемой, если более строгая директива, такая как «noindex», была добавлена случайно.
Ниже – пример такой неправильной реализации:
- заголовок HTTP содержит директиву index, follow:
HTTP/... 200 OK
...
X-Robots-Tag: index,follow
- метатег robots в разделе <head> запрещает индексацию:
<head>
<title>SEO</title>
<meta name="robots" content="noindex,follow">
...
</head>
Директивы noindex/follow следует указывать только один раз в HTML или в заголовке HTTP.
Как устранить эту проблему?
Решить эту проблему относительно просто. Вам нужно удалить лишние директивы и оставить только одну, которой должны следовать Google и другие поисковые системы.
Чтобы найти такие страницы, тоже понадобится краулер. Если проблема затронула небольшое количество страниц, то их можно обновить вручную. Если же речь идет о тысячах или миллионах страниц, то тогда потребуется скорректировать правило, которое добавляет эти несколько директив.
6. Внутренние ссылки с директивами nofollow и disallow
Использование директив nofollow и disallow для внутренних ссылок может мешать их ранжированию, поскольку Google не сможет увидеть их контент, если они заблокированы в robots.txt, или же через них не будет передаваться ссылочный вес, если они закрыты атрибутом nofollow.
Если вы не хотите, чтобы Google индексировал конкретные URL, просто добавьте тег noindex. Директива disallow в robots.txt не блокирует индексирование.
Использование nofollow для внутренних ссылок тоже обычно не очень хорошая идея с точки зрения SEO.
Обычно оптимизаторы закрывают атрибутом nofollow те ссылки, которые ведут на страницы с условиями использованиями или правилами. Однако в Google уже несколько раз заявляли, что необходимости в этом нет.
Как устранить эту проблему?
Вам нужно удалить эти URL из robots.txt и удалить атрибут nofollow из внутренних ссылок.
Чтобы увидеть все внутренние ссылки с атрибутом nofollow, используйте краулер по типу Sitebulb. Вы также можете использовать Chrome-расширение NoFollow, которое помечает ссылки с nofollow на посещаемых страницах. Это особенно полезно в случае ручной проверки сайта.
7. Внутренние ссылки низкого качества с атрибутом follow
Низкокачественные внутренние ссылки не несут никакой полезной информации и являются пустой тратой SEO-потенциала.
Внутренние ссылки – один из самых сильных сигналов, предоставляющих информацию о связанных URL. Поэтому SEO-специалисты всегда должны стараться извлечь максимум из внутренней перелинковки.
Ниже – примеры низкокачественных ссылок:
- Текстовые ссылки с анкорным текстом типа «Нажмите, чтобы прочитать», «Узнать больше» и т.п.
- Графические ссылки без атрибута alt. В графических ссылках этот атрибут действует так же, как анкорный текст в текстовых ссылках.
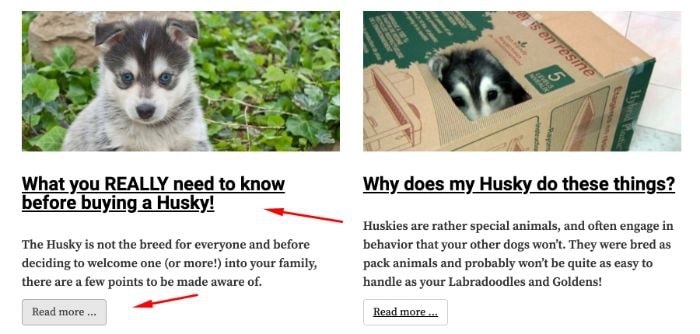
Как устранить эту проблему?
В идеальном SEO-мире вам нужно иметь лишь высококачественные текстовые и графические внутренние ссылки.
Самый простой способ решить проблему с низкокачественными ссылками – это удалить все ссылки типа «Узнать больше» и заменить их текстовыми ссылками с релевантным анкорным текстом.
Если вы не можете удалить эти ссылки, убедитесь, что есть более качественные URL, указывающие на ту же страницу. Например, в случае заголовка в блоге вы можете иметь две ссылки: одну с текстом «Читать дальше», а другую с описательным анкорным текстом типа «Руководство по аудиту сайта».
8. Отсутствие входящих и исходящих внутренних ссылок
Если у страницы отсутствуют входящие и/или исходящие внутренние ссылки, то она не передает ссылочный вес другим страницам или не получает ссылочный вес от них.
Если рассматриваемый URL не должен ранжироваться в Google, то это не проблема. В таком случае обычно лучше просто добавить к нему атрибут noindex.
Если же это важная страница, которая должна приносить органический трафик и иметь высокие позиции в выдаче, то у нее могут быть трудности с индексацией и/или ранжированием в Google.
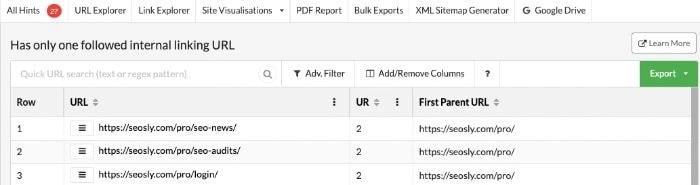
Как устранить эту проблему?
Для этого вам нужно добавить текстовые ссылки (с релевантным анкорным текстом) с этой страницы и на нее.
В идеале внутренние ссылки должны поступать с других тематически релевантных страниц. То же самое касается и исходящих ссылок: они должны указывать на связанные страницы.
Например, перелинковку можно сделать между страницами «Аудит технического SEO» и «Аудит Core Web Vitals» – они относятся к одной теме.
9. Внутренние и/или внешние редиректы с ошибками
И внутренние, и внешние редиректы могут приводит к плохому пользовательскому опыту и сбивать с толку поисковых роботов (особенно, если эти перенаправления не работают должным образом).
Как и в случае с каноническими URL, при переадресации многое может пойти не так.
Ниже – примеры самых частых проблем с редиректами:
- Внутренний редирект возвращает код состояния 4xx или 5xx.
- Внешний редирект возвращает ошибку 4xx или 5xx.
- Переадресованный URL зациклен сам на себя (циклическая переадресация).
Все примеры выше в случае большого количества URL на сайте могут негативно отразиться на его сканировании и пользовательском опыте. И пользователи, и поисковые системы могут покинуть сайт из-за ошибочной переадресации.
Как устранить эту проблему?
Проблемные URL можно найти с помощью любого доступного краулера.
В случае внутренних URL вам нужно будет обновить целевые URL таким образом, чтобы они возвращали код состояния 200 (ОК).
Что касается внешних перенаправлений, то нужно будет удалить ссылки, указывающие на переадресованные URL, и заменить их другими URL, возвращающими код состояния 200 (ОК).
10. Внутренние ссылки на переадресованные URL
Если на сайте есть URL, переадресованные на другие внутренние URL, то ссылки должны вести не на переадресованные, а на целевые URL.
Хотя у нас нет контроля над внешними ссылками, мы можем полностью контролировать внутренние ссылки. Убедитесь, что на сайте нет внутренних ссылок на переадресованные URL.
Как решить эту проблему?
И диагностика, и решение этих проблем очень просты, если вы используете краулер по типу Sitebulb или Screaming Frog. Когда инструмент покажет вам переадресованные URL, ваша задача:
- Подготовить список этих переадресованных URL вместе с их целевыми URL и теми URL, которые они замещают.
- Заменить все переадресованные URL на целевые.
В зависимости от масштаба проблемы, вы можете делать это вручную или же автоматизировать эту задачу.
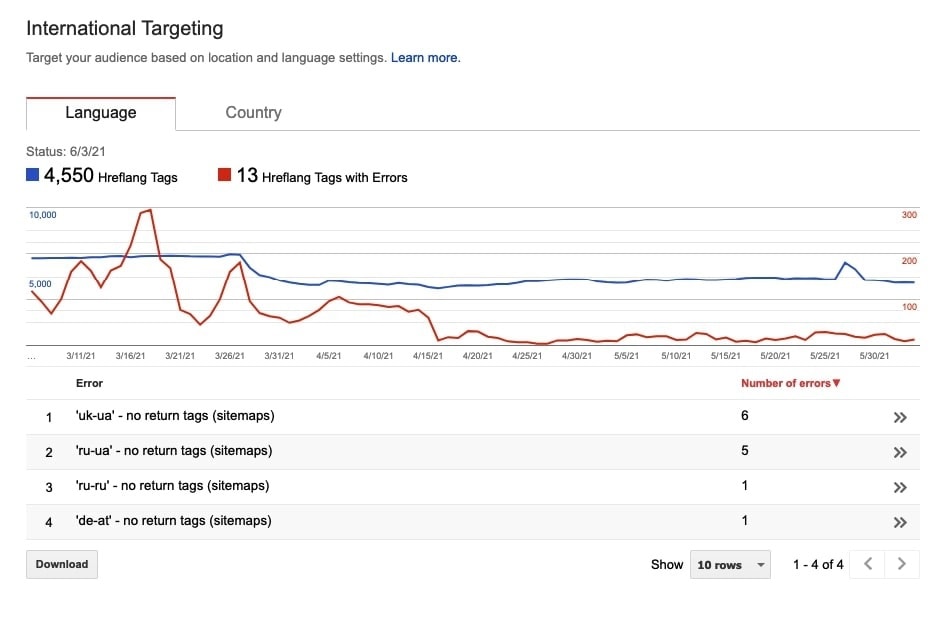
11. Недействительные и/или некорректные атрибуты hreflang
Если у международного сайта есть проблемы с реализацией hreflang, то он не сможет должным образом сообщить целевой язык или регион своих URL поисковым системам.
Среди возможных проблем значатся следующие:
- Недействительные аннотации hteflang (коды языков или регионов указаны неверно);
- Аннотации hreflanf указывают на закрытые атрибутом noindex, директивой disallow или каноникализированные URL;
- Атрибуты hreflang указывают на URL, возвращающие коды ошибки 4xx или 5xx;
- Атрибуты hreflang указывают на переадресованные URL;
- Атрибуты hreflang конфликтуют друг с другом;
- Атрибуты hreflang указаны с использованием нескольких методов (в разделе <head>, в заголовке HTTP и/или в файле Sitemap);
- Атрибуты hreflang отсутствуют на многоязычном сайте;
- Отсутствуют теги возврата hreflang;
- Отсутствует атрибут x-default.
Как устранить эту проблему?
Вам нужно отредактировать аннотации hreflang таким образом, чтобы убрать все перечисленные выше ошибки. Атрибуты hreflang должны быть валидными, указывать на корректные канонические URL, которые возвращают код состояния 200 (ОК), содержат теги возврата и прописанный атрибут X-default. В зависимости от размера сайта это может быть сделано вручную или автоматически.
Определить проблемы с реализацией hreflang можно с помощью инструментов для сканирования сайтов. Также можно использовать отчет «Таргетинг по странам и языкам» в Search Console, чтобы проверить, работают ли атрибуты hreflang должным образом.
12. В разделе <head> страницы содержатся недействительные HTML-элементы
Размещение невалидных HTML-элементов в раздел <head> может нарушить его или закрыть слишком рано. Это может привести к тому, что поисковые роботы пропустят некоторые важные элементы, такие как метатеги robots или ссылочные элементы с атрибутом rel=canonical.
На что смотреть:
- Если в разделе <head> содержится тег noscript, то в нем должны быть только такие элементы, как meta, link и style.
- Добавление других элементов, таких как h1 или img в тег noscript, который размещен в разделе <head>, недопустимо.
Если тег noscript размещен в теле страницы (в разделе <body>), то в него можно добавлять такие элементы, как img.
Как устранить эту проблему?
Необходимо обновить раздел <head> сайта, удалив из него все недействительные элементы.
В зависимости от типа сайта и используемой CMS редактирование этого раздела может отличаться.
13. URL доступны и в HTTP, и в HTTPS
Если сайт доступен и в HTTP, и в HTTPS, то это серьезная проблема SEO и безопасности. Это может вызвать недоверие к сайту как со стороны пользователей, так и поисковых систем. Кроме того, браузеры будут показывать предупреждение о том, что сайт загружается через HTTP.
Необходимо, чтобы на всех HTTP-страницах был настроен 301 редирект на HTTPS-версию.
Как решить эту проблему?
Ваша задача – убедиться, что на всех страницах есть перенаправление 301 на HTTPS-версию.
Узнать, есть ли на сайте URL, доступные в HTTP-версии, можно с помощью любого краулера.
Самый лучший способ реализации редиректов – это добавить их в файл .htaccess.
14. Смешанный контент и/или внутренние HTTP-ссылки
Если на сайте есть смешанный контент и/или внутренние ссылки на URL в HTTP-версии, то браузеры могут показывать красные предупреждения, что сайт не является полностью защищенным.
Если у сайта есть SSL-сертификат, то все URL, ресурсы и внутренние ссылки должны быть на HTTPS. В противном случае у сайта могут возникнуть проблемы с доверием как со стороны пользователей, так и поисковых систем.
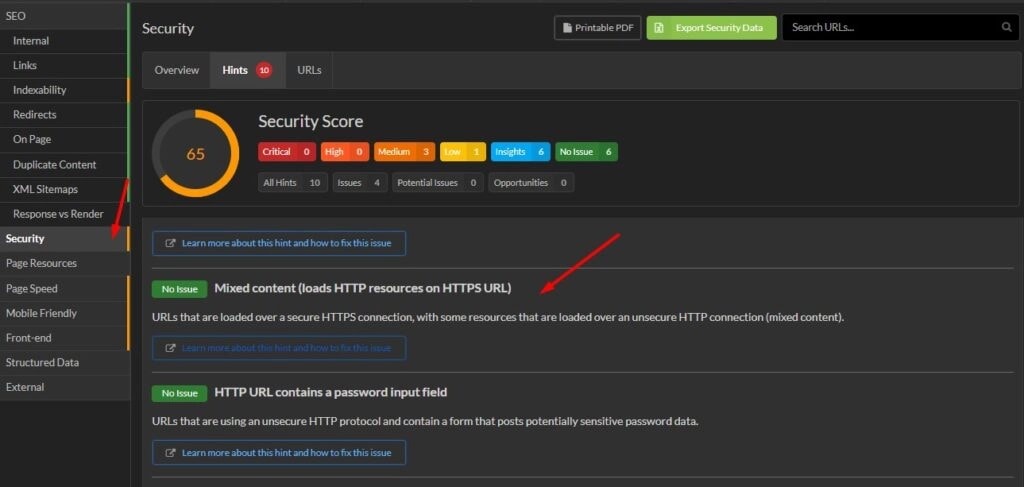
Как решить эту проблему?
Убедитесь, что все ресурсы и URL сайта переадресованы на HTTPS-версию с помощью 301 редиректов. HTTP-ссылки необходимо заменить на HTTPS-версии.
В случае WordPress вы можете использовать плагин SSL Insecure Content Fixer.
15. Техническое дублирование контента
Техническое дублирование контента может привести к созданию тысяч или даже миллионов URL-адресов с идентичным контентом. Это может негативно повлиять на бюджет сканирования и способность Google эффективно сканировать и индексировать сайт.
Такое дублирование контента происходит при наличии нескольких индексируемых и канонических URL-адресов с идентичным содержанием. Обычно это те URL, в которых регистр букв не важен и которые содержат параметры, не влияющие на содержимое URL.
Google – в большинстве случаев – знает, как справляться с техническим дублированием контента, но лучше все же убедиться, что таких URL на сайте нет.
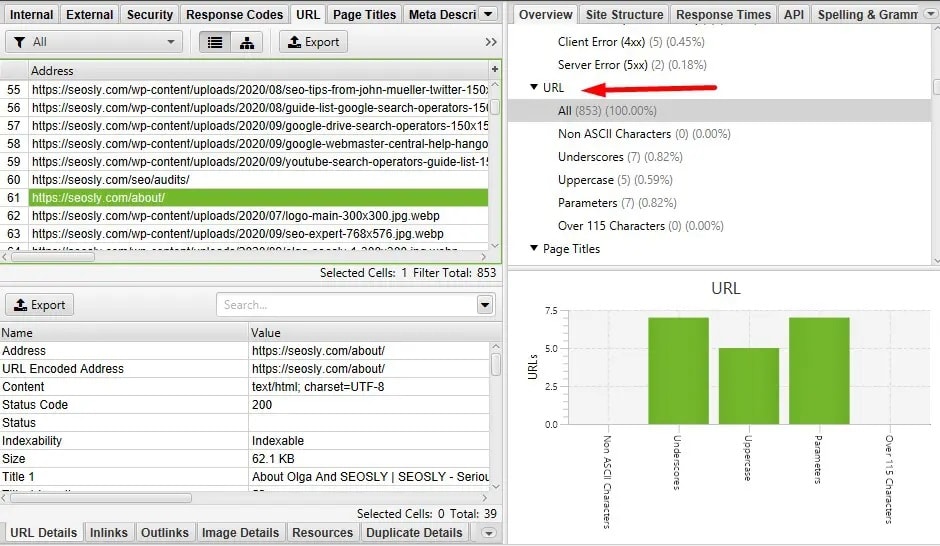
Как решить эту проблему?
Обычно сделать это довольно просто. Все, что вам нужно, – это добавить ссылочный элемент link с атрибутом rel=canonical, указывающим на основную версию URL (без параметров и в нижнем регистре), на все дублированные страницы.
Когда это будет сделано, все повторяющиеся URL-адреса появятся в разделе «Исключенные» в отчете об индексировании в Google Search Console.





