с использованием документированных операторов языка запроса
Несмотря на то, что гибкий и универсальный способ определения аффилированности двух сайтов в Яндексе, предложенный мной в статье «Проверка аффилированности двух сайтов в Яндексе», на данный момент является рабочим, тот факт, что он использует оператор отрицания ~~, поддержка которого Яндексом была официально прекращена, делает его не очень надежным. В принципе, этот оператор можно заменить другим оператором отрицания ~, но он также уже официально не поддерживается. А единственный оставшийся документированным оператор отрицания – (минус) нужного эффекта не даёт. И несмотря на то, что на данный момент в связке с оператором url: операторы ~~ и ~ обеспечивают принудительную группировку по сайтам разгруппированной в результате использования оператора url: выдачи (что является сутью предложенного метода), в любой момент можно ожидать потери работоспособности этого функционала. Тем более, что операторы ~~ и ~ уже частично потеряли свою работоспособность, о чем я писал в своей статье «Новая логика работы операторов языка запросов Яндекса. Морфология и поисковый контекст». В связи с этим возникает необходимость поиска альтернативного метода определения аффилированности двух сайтов, не зависящего от операторов, поддержка которых прекращена.
Одну из альтернатив я представил в статье «Определение аффилиатов в Яндексе – поиск альтернативных способов». Сутью этого метода являлось нахождение запросов, состоящих из точных фраз, взятых из контента главных страниц исследуемых сайтов, и формирование из них поискового запроса путем компоновки их через документированный оператор | (логическое ИЛИ). Важным свойством выдачи по такому запросу должно быть ее жесткое ограничение по количеству документов (в идеале все результаты должны умещаться на одну страницу), чтобы можно было достоверно оценить наличие или отсутствие одного из сайтов в выдаче. Это существенно повышает требования к выбираемым из контента страниц фразам, и, следовательно, ограничивает возможность автоматизации данного способа.
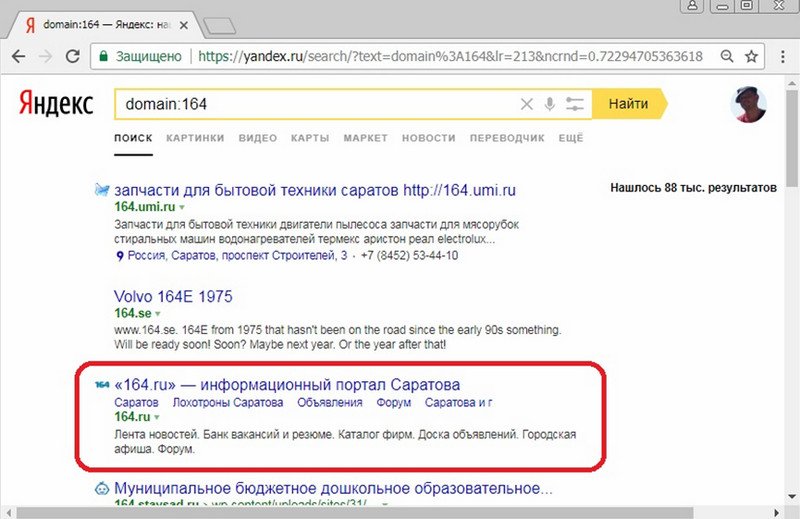
Поэтому я продолжил поиск более гибкого и универсального способа. В отличие от документных операторов url:, site:, host: и rhost:, оператор domain: не производит разгруппировки выдачи по сайтам, и в то же время его можно использовать для построения выдачи, в которой исследуемые сайты могут находиться достаточно близко к топу, что важно для анализа.
Возьмем в качестве исследуемых сайты из статьи «Определение аффилиатов в Яндексе – поиск альтернативных способов», которые определяются старым методом, как аффилированные (замечу, что сейчас нет необходимости использовать оператор | между операторами url:):
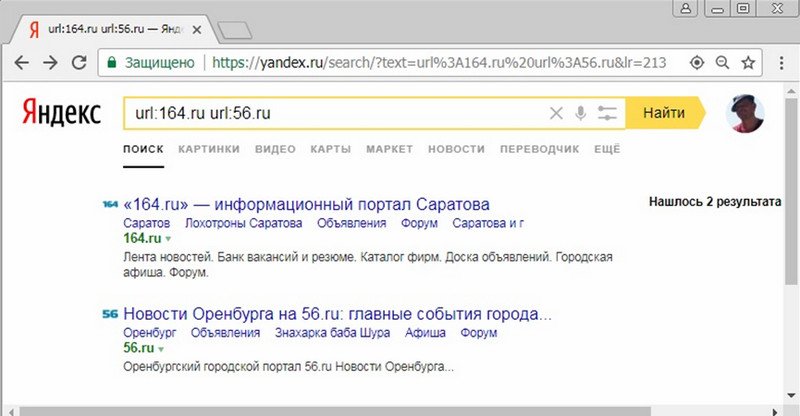
При поиске с помощью оператора domain: по их доменным именам 2-го уровня, они находятся достаточно близко к топу выдачи:
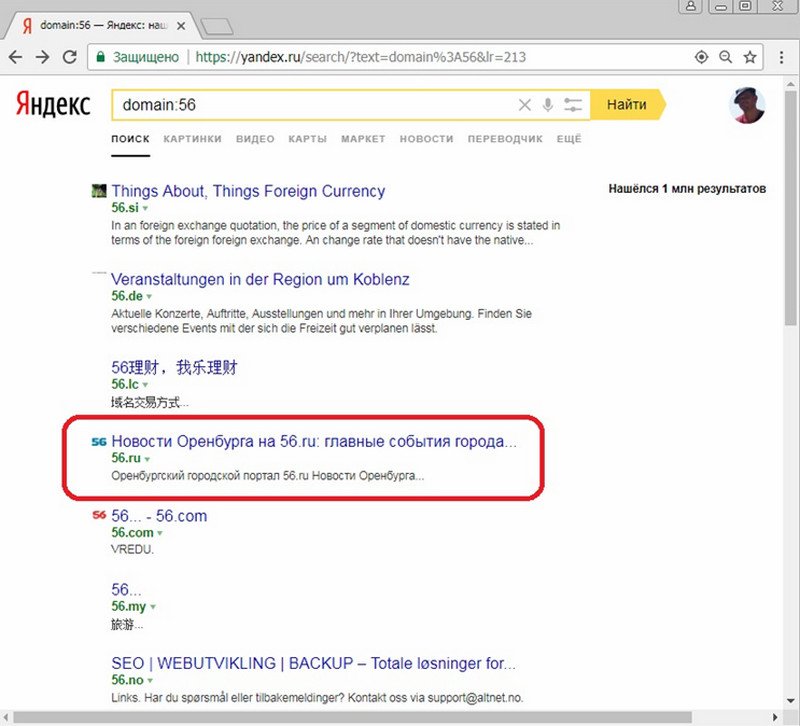
Теперь компонуем выдачу из этих двух запросов. На первой странице видим только один из двух сайтов:
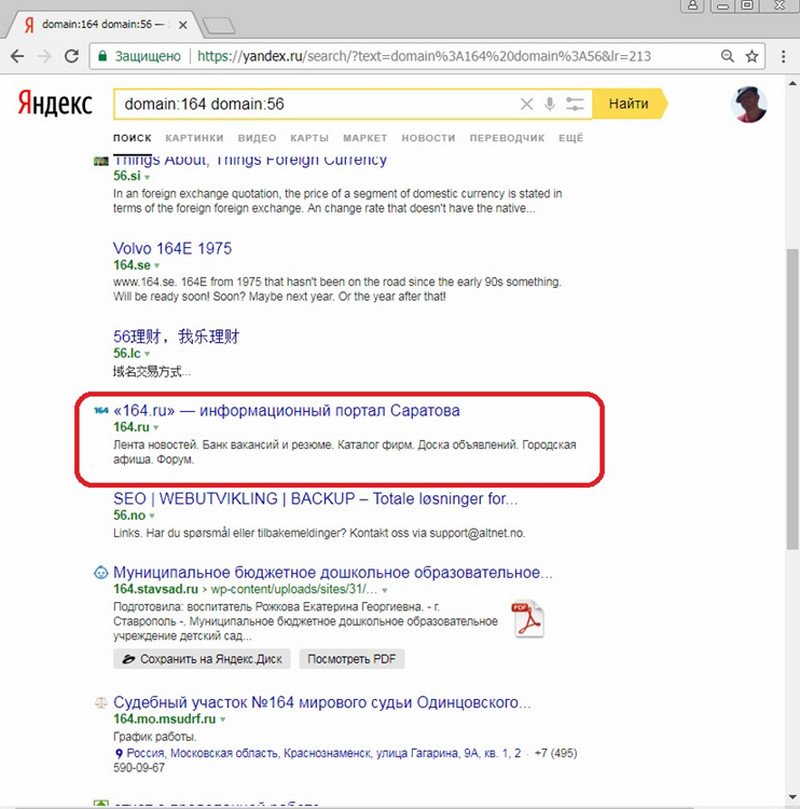
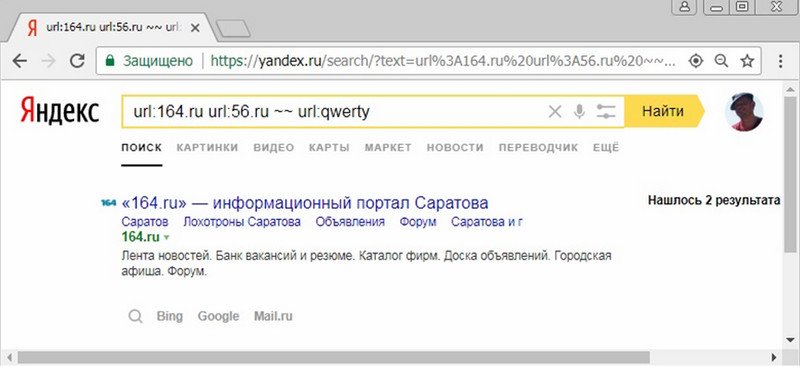
Попробуем разгруппировать эту выдачу по сайтам. В своей статье «Параметры URL страницы выдачи Яндекса» я упоминал про get-параметр pag=u, который обеспечивает разгруппировку результатов выдачи по сайтам и который можно использовать для поиска отфильтрованных аффилиатов в выдаче. Добавляя этот get-параметр в URL страницы поисковой выдачи, видим появление в ней второго сайта:
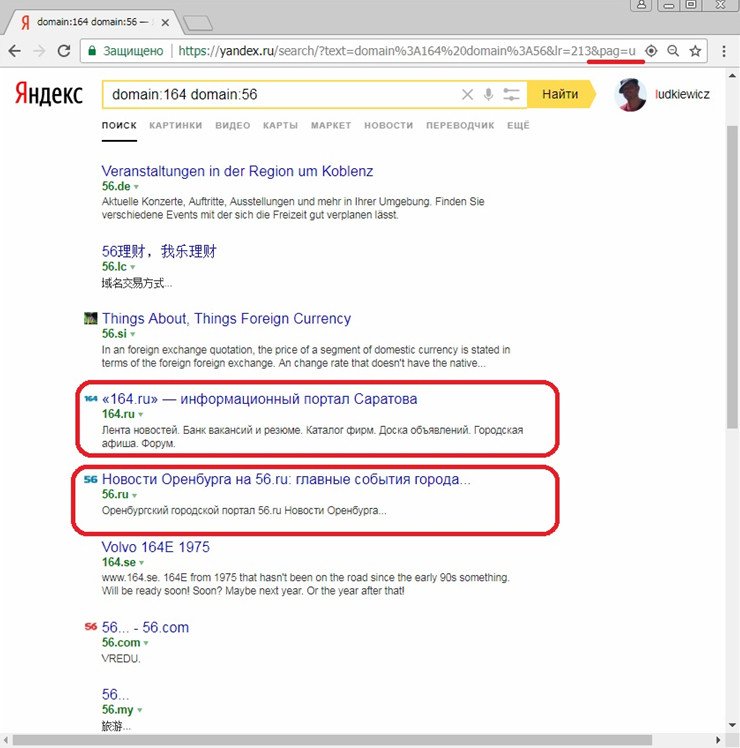
Таким образом, можно сделать вывод об аффилированности этих двух сайтов. Данный метод представляется гораздо менее трудоемким и лучше поддающимся автоматизации, чем представленный в предыдущей статье.
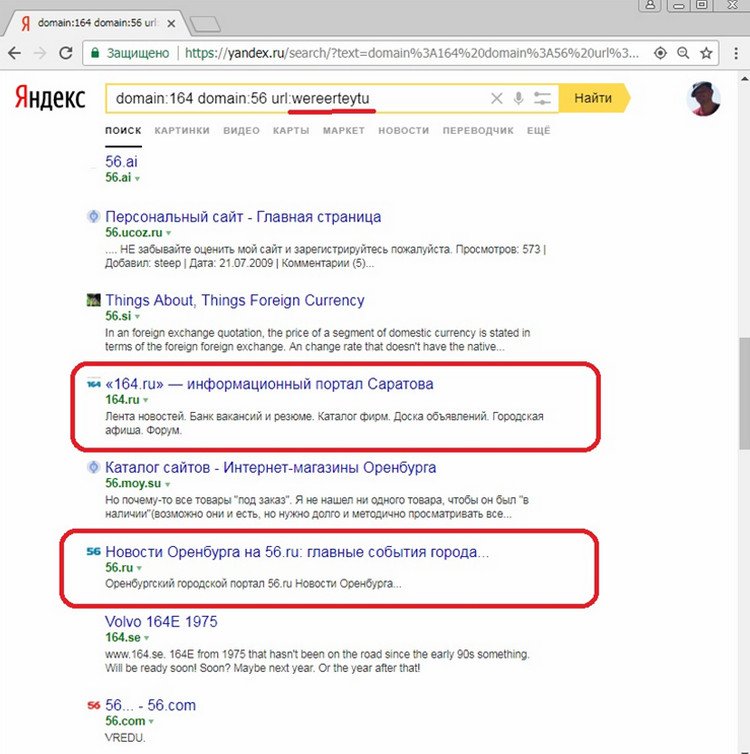
Также можно разгруппировать выдачу и с помощью добавления в запрос любого оператора из группы url:, site:, host: и rhost: (чтобы не увеличивать число документов в выдаче, целесообразно будет задавать в качестве их значения какую-нибудь абракадабру). В этом случае определенное неудобство состоит в том, что запрос фактически изменяется, и анализируемые сайты могут весьма существенно смещаться в выдаче. Так, для рассматриваемого примера анализируемые сайты несколько смещаются вниз, но, тем не менее, попадают на первую страницу выдачу при выводе по 50 результатов, что существенно облегчает анализ: