
Автор: Гленн Гейб (Glenn Gabe) – SEO-консультант в агентстве G-Squared Interactive. Работает в области digital-маркетинга более 20 лет.
За последние годы мы несколько раз сталкивались с интересной ситуацией с robots.txt, которая может быть сложной для владельцев сайтов. После выявления проблемы и разговоров с клиентами о том, как её решить, мы обнаружили, что многие люди даже не подозревают, что такое может произойти. А поскольку речь идёт о файлах robots.txt, то это может оказывать большое влияние на SEO.
Мы имеем в виду файлы robots.txt, обрабатываемые по поддоменам и протоколам. Другими словами, на сайте может быть одновременно несколько файлов robots.txt, добавленных по поддоменам: www и non-www, или по протоколам: https www и http www.
Поскольку Google обрабатывает каждый из них в отдельности, вы можете передавать совершенно разные инструкции о том, как сайт должен сканироваться.
В статье мы рассмотрим два реальных примера сайтов, которые столкнулись с данной проблемой. Мы также ознакомимся с документацией Google по robots.txt и разберёмся, как обнаружить другие файлы.
Подход Google к обработке файлов robots.txt
Выше мы упоминали, что Google обрабатывает файлы robots.txt по поддомену и протоколу. Например, сайт может иметь один файл robots.txt в версии с www и совершенно другой в версии без www. В своей практике мы несколько раз наблюдали такую ситуацию по сайтам клиентов и недавно снова столкнулись с ней.
Помимо www и non-www, сайт также может иметь файл robots.txt, расположенный в https- и http-версиях поддомена. Таким образом, может быть несколько файлов robots.txt с разными инструкциями для поисковых роботов.
Документация Google чётко объясняет, как обрабатываются файлы robots.txt. Вот несколько примеров того, как будут применяться обнаруженные инструкции:
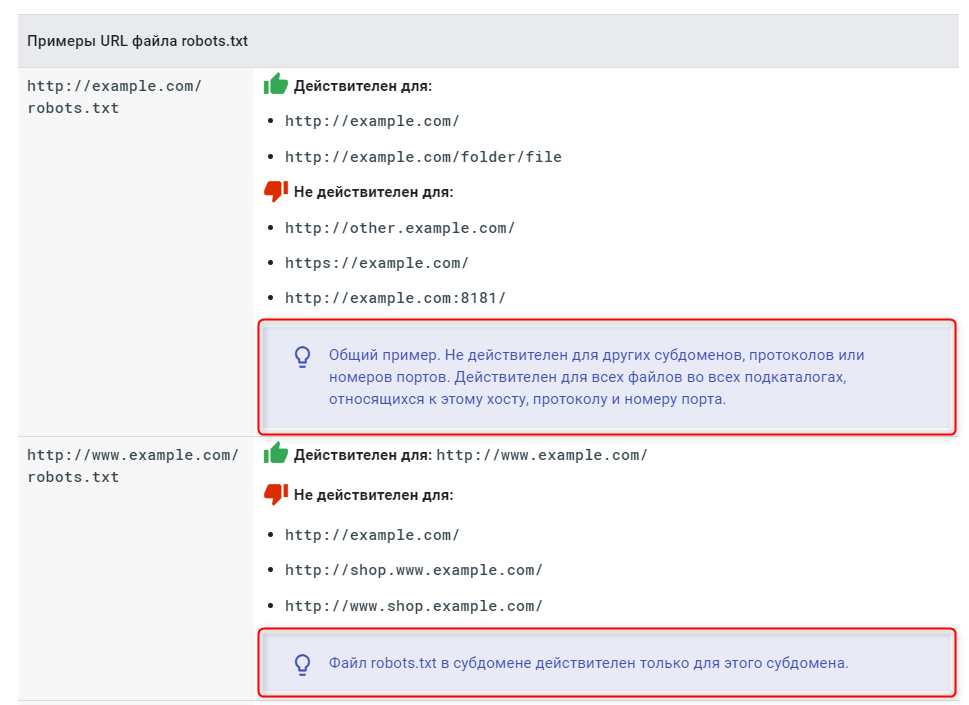
Такой подход определённо может вызвать проблемы, так как Googlebot может получить разные файлы robots.txt для одного и того же сайта и по-разному сканировать каждую его версию. И тогда возможна ситуация, когда владельцы сайтов полагают, что Googlebot выполняет один набор инструкций в то время, как он также получает ещё один набор во время других обходов сайта.
Ниже мы рассмотрим два случая, где мы столкнулись с такой проблемой.
Кейс № 1. Разные файлы robots.txt с конфликтующими директивами в www и non-www версиях
Недавно, выполняя аудит сканирования на одном из сайтов, мы заметили, что некоторые страницы, заблокированные в robots.txt, по факту сканируются и индексируются. Мы знаем, что Google на 100% соблюдает инструкции в файле robots.txt, поэтому это был явный красный флаг.
Отметим, мы имеем в виду те URL, которые сканируются и индексируются в обычном режиме, несмотря на то что инструкции в robots.txt должны запрещать сканирование. Google также может индексировать URL-адреса, заблокированные файлом robots.txt, не сканируя их, но это другая ситуация, которую мы рассмотрим ниже.
Проверяя файл robots.txt вручную, мы увидели набор инструкций для версии без www, и там было прописано ограничение. Затем мы начали вручную проверять другие версии сайта (по поддомену и протоколу), чтобы посмотреть, есть ли какие-либо проблемы там.
И они были: в поддомене с www был ещё один файл robots.txt. И, как вы можете догадаться, он содержал другие инструкции.
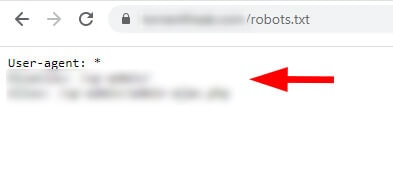
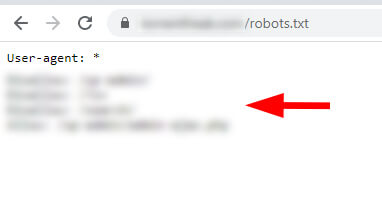
На сайте не было правильной переадресации robots.txt для www-версии на версию без www. Таким образом, Google смог получить доступ к обоим файлам robots.txt и найти два разных набора инструкций для сканирования.
Опять же, как показывает наш опыт, многие владельцы сайтов не знают, что такие ситуации возможны.
- Краткое примечание о заблокированных страницах, которые могут быть проиндексированы
Ранее мы упоминали, что страницы, правильно заблокированные в файле robots.txt, могут быть проиндексированы. Они просто не будут сканироваться.
Google объяснял это много раз, и вы можете узнать больше о том, как он может индексировать такие URL-адреса в справочной документации по robots.txt.
Мы знаем, что это запутанная тема для многих владельцев сайтов, но Google определенно может индексировать страницы, которые заблокированы. Например, это возможно в том случае, когда Google видит входящие ссылки, указывающие на эти страницы.
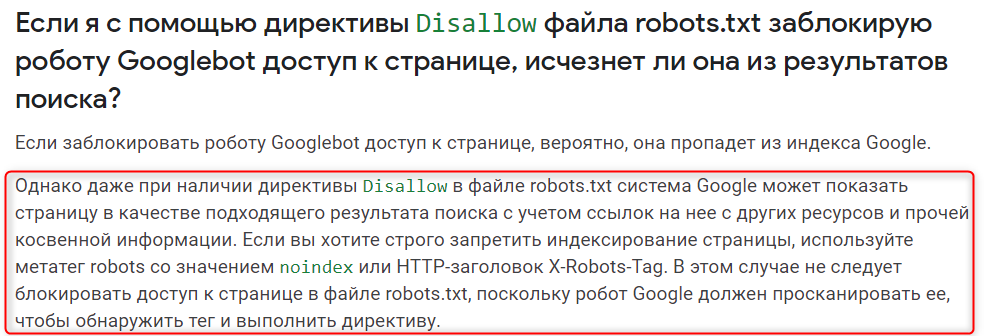
Когда это происходит, Google индексирует URL-адреса и указывает в результатах поиска, что информации об этих страницах нет. Они будут отображаться без описания.
Но это не та ситуация, которую мы рассматриваем в данной статье. Вот скриншот из FAQ Google по robots.txt, где говорится про возможную индексацию заблокированных URL:
А как насчёт Search Console и файлов robots.txt?
В Search Console есть отличный инструмент, который можно использовать для отладки файлов robots.txt – Robots.txt Tester.
К сожалению, многим владельцам сайтов этот инструмент сложно найти. На него нет ссылок в новом Search Console. Но в него можно попасть из Справочного центра сервиса.
Используя этот инструмент, вы можете просматривать предыдущие файлы robots.txt, которые видел Google. Как вы можете догадаться, мы увидели оба файла robots.txt по анализируемому сайту. Поэтому, да, Google действительно видит второй файл.
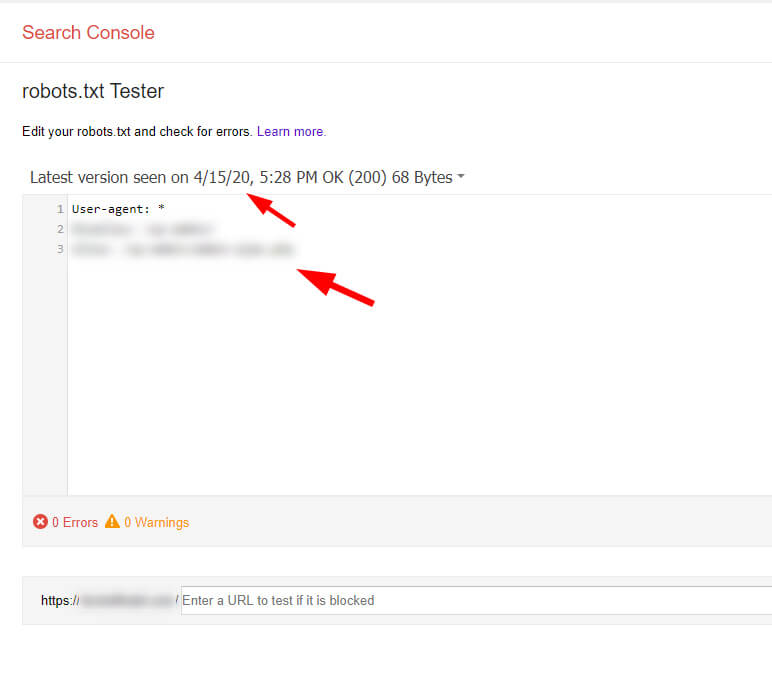

Выявив проблему, мы быстро отправили клиенту всю необходимую информацию, скриншоты и т.п. Мы также велели им удалить второй файл robots.txt и настроить переадресацию 301 с www-версии на версию без www. Теперь, когда Google будет заходить на сайт и проверять файл robots.txt, он будет видеть правильный набор инструкций.
При этом на сайте остались те URL, которые были проиндексированы из-за смешанных директив. Поэтому теперь наш клиент открывает эти URL для сканирования, но следит за тем, чтобы файлы были заблокированы от индексации через метатег robots.
Когда общее количество таких URL в GSC снизится, мы снова добавим правильно реализованную директиву disallow, чтобы заблокировать эту область.
Кейс № 2. Разные файлы robots.txt для http и https
Несколько лет назад к нам обратился один вебмастер в связи с падением органического поискового трафика по сайту без видимых причин.
Покопавшись, мы решили проверить разные версии сайта по протоколу (включая файлы robots.txt для каждой версии).
При попытке проверить https-версию файла robots.txt нам сначала пришлось просмотреть предупреждение безопасности в Chrome. И как только мы это сделали, то увидели второй файл robots.txt, который блокировал весь сайт от сканирования.
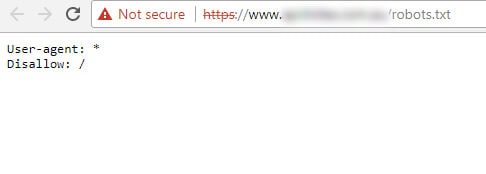
В https-версии файла robots.txt оно было полностью запрещено с помощью директивы Disallow: /.
Помимо этого, на сайте были и другие проблемы, но наличие нескольких файлов robots.txt, один из которых полностью запрещал сканирование, трудно назвать оптимальным.
Https-версия файла robots.txt (скрытая за предупреждением безопасности в Chrome):
Проблемы по сайту, отображаемые в Search Console для https-ресурса:

Просмотр https-версии сайта как Googlebot показывает, что она заблокирована:
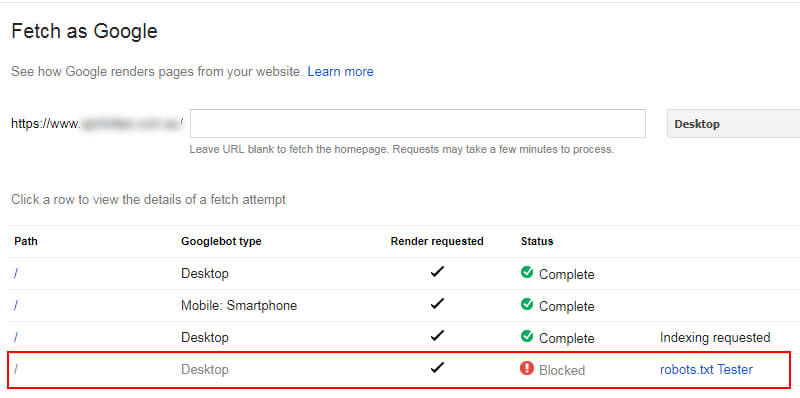
Как и в первом случае, владелец сайта быстро решил проблему (что было нелегко, учитывая их CMS).
Это ещё один хороший пример того, как Google обрабатывает файлы robots.txt, и в чём опасность наличия на сайте нескольких файлов по разным поддоменам или протоколам.
Как найти несколько файлов robots.txt: инструменты
Есть несколько инструментов, которые можно использовать, помимо ручной проверки файлов robots.txt по поддомену или протоколу.
Они также могут помочь увидеть, какие файлы robots.txt ранее отображались по сайту.
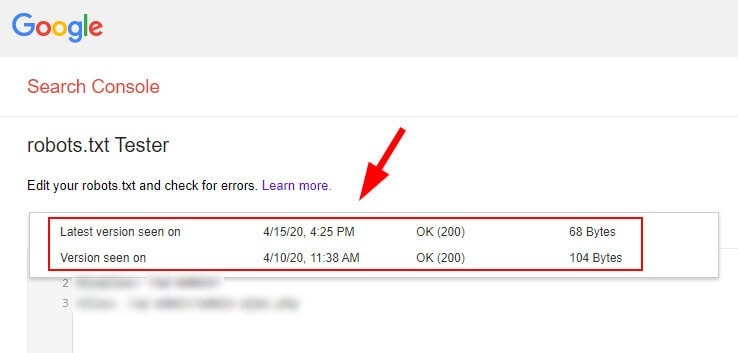
- Инструмент проверки robots.txt в Search Console
Этот инструмент, который мы уже упоминали выше, позволяет видеть текущий файл robots.txt и предыдущие версии, обработанные Google.
Он также функционирует как «песочница», где можно протестировать новые директивы.
В целом это отличный инструмент, который Google по непонятным причинам поместил в дальний угол.
- Wayback Machine
Интернет-архив также может быть полезен в этой ситуации. Мы уже рассматривали его использование в своей колонке на Search Engine Land.
Однако Wayback Machine можно использовать не только для проверки стандартных веб-страниц. Этот инструмент также позволяет просматривать те файлы robots.txt, которые были на сайте ранее.
Таким образом, это отличный способ отследить предыдущие версии файла robots.txt.

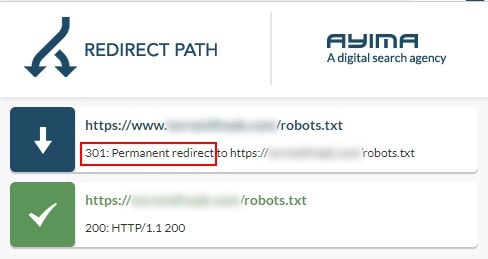
Решение: переадресация 301
Чтобы избежать проблем с robots.txt по поддомену или протоколу, нужно реализовать переадресацию файла robots.txt на нужную версию с помощью 301 редиректа.
Например, если сайт работает на www, нужно перенаправить robots.txt в поддомене без www на версию с www.
Что касается https и http, то у вас уже должна быть настроена эта переадресация. Просто убедитесь, что файл robots.txt переадресован на нужный протокол и версию поддомена. А также – что все URL правильно перенаправлены на нужную версию.
Для других поддоменов вы можете выбрать отдельные файлы robots.txt, что вполне нормально. Например, у вас может быть форум, расположенный на поддомене forums.domain.com, и инструкции по нему могут отличаться от инструкций для www-версии.
В данной статье мы говорим о www/non-www и http/https для основного сайта.
Вместо заключения: следите, чтобы инструкции в файлах robots.txt совпадали
Поскольку robots.txt контролирует сканирование, чрезвычайно важно понимать, как Google обрабатывает эти файлы.
Некоторые сайты могут содержать несколько файлов robots.txt по отдельным поддоменам и протоколам с разными инструкциями. В зависимости от того, как Google сканирует сайт, он может находить один из этих файлов, что может приводить к проблемам.
Поэтому важно убедиться, что все файлы robots.txt содержат согласованные директивы.





