
Команда разработчиков Screaming Frog SEO Spider сообщила о том, что инструмент обновлён до версии 7.0. В числе основных нововведений значатся следующие:
1. Новая вкладка «Rendered Page». Теперь пользователи смогут просматривать страницы, которые обработал SEO Spider. Вкладка динамически появляется в нижней части интерфейса во время сканирования в режиме JavaScript rendering. По умолчанию эта функция включена. С её помощью вебмастера смогут видеть, как каждая страница отображается на мобильных устройствах.

2. Заблокированные ресурсы. Эти элементы будут отображаться для каждой страницы на вкладке «Rendered Page». Их также можно просмотреть на вкладке «Blocked Resource» в разделе «Response Codes». Кроме того, информацию о заблокированных ресурсах и страницах, на которых они находятся, можно экспортировать. Для этого нужно выбрать «Bulk Export» > «Response Codes» > отчёт «Blocked Resource Inlinks».
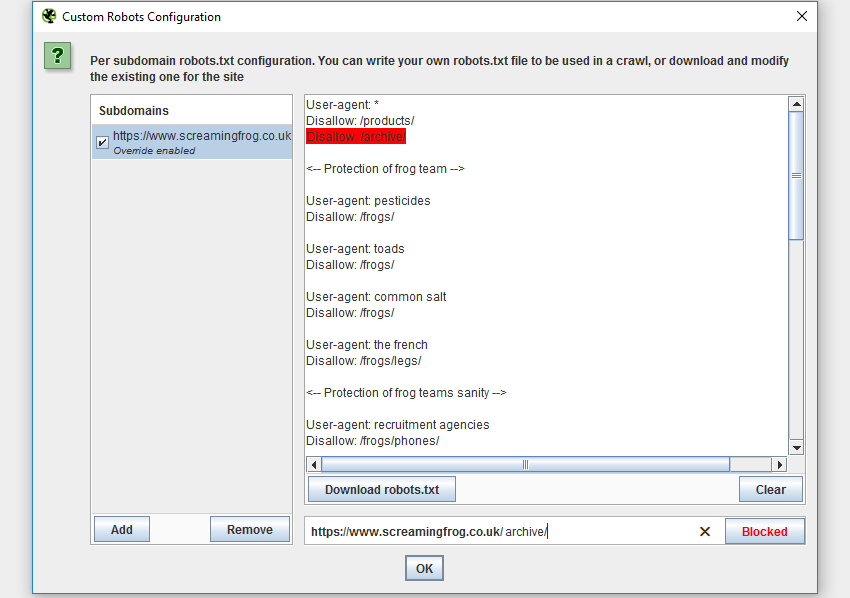
3. Пользовательский файл robots.txt. Теперь вебмастера смогут скачивать, редактировать и тестировать файл robots.txt с помощью новой функции «Custom» на вкладке «robots.txt» в разделе «Configuration». Функция позволяет добавить несколько файлов robots.txt на уровне поддомена, протестировать директивы в SEO Spider и посмотреть, какие URL заблокированы.
 4. Атрибуты hreflang. Обновлённый SEO Spider извлекает, сканирует и предоставляет отчёты по атрибутам hreflang в ссылках и заголовках HTTP. Эти атрибуты также извлекаются из файлов Sitemap во время сканирования в режиме списка. Инструмент предлагает 4 новых отчёта по разметке hreflang:
4. Атрибуты hreflang. Обновлённый SEO Spider извлекает, сканирует и предоставляет отчёты по атрибутам hreflang в ссылках и заголовках HTTP. Эти атрибуты также извлекаются из файлов Sitemap во время сканирования в режиме списка. Инструмент предлагает 4 новых отчёта по разметке hreflang:
- «Errors» показывает атрибуты, которые не возвращают код ответа сервера 200 или не привязаны к ссылкам на сайте;
- «Missing Confirmation Links» показывает страницу, на которой отсутствует ссылка подтверждения и страницу, которая её запрашивает.
- «Inconsistent Language Confirmation Links» отображает страницы подтверждения, которые используют коды разных языков на одной и той же странице;
- «Non Canonical Confirmation Links» показывает ссылки подтверждения, которые указывают на неканонические URL.
5. Ошибки rel=”next” и rel=”prev”. В этом отчёте содержатся данные об ошибках, связанных с атрибутами rel=”next” and rel=”prev”. Он покажет URL, которые заблокированы в robots.txt или возвращают код ответа сервера, отличный от 200.
6. Экспорт URL в том же порядке, что и на сайте.
7. Новая конфигурация аутентификации (вкладка «Configuration» > «Authentication»). Она позволяет пользователям авторизироваться в любой веб-форме в браузере SEO Spider Chromium и затем провести сканирование.
Напомним, что версия инструмента 6.0 вышла в июле. Главным нововведением в ней стал запуск переработанного краулера, функционал которого теперь во многом приблизился к возможностям GoogleBot. В частности, теперь краулер способен обрабатывать элементы на JavaScript. По умолчанию SEO Spider отображает контент также, как браузер, который используется в процессе запуска сканирования.





