
Доклад Алексея Чекушина, руководителя отдела трафикового продвижения в Kokoc Group, на тему «Автоматизация работы с семантикой в SEO-студии».

В докладе подробно рассказывается о системе just-magic.org, которая позволяет автоматизировать процесс сбора семантики. Перечисленные подходы, призваны решать следующие ключевые задачи SEO-студии:
- Составление семантики для КП.
- Разработка семантики для сайтов в продвижении.
- Расширение структуры сайта.
- Разработка семантики для крупных сайтов: как правило, это интернет-магазины либо информационные порталы.
Основными проблемами на данном этапе становятся:
- Составление семантического ядра занимает длительное время.
- Качество семантики: важна как полнота семантического ядра, так и правильное постраничное распределение.
Существует два подхода к работе с семантикой. Это классический метод – долгий и затратный и автоматическое определение маркеров.
Классический метод сводится к сбору запросов для сайта, группировке запросов, распределению по страницам. В случае, если облако запросов уже сформировано: в текущей системе оно составляет 95 миллионами запросов. Однако просто собрать облако запросов мало, необходимо добиться быстрой и правильной привязки запросов из него к страницам на сайте.
Чтобы решить эту задачу, в соответствие каждому продвигаемому URL сайта ставится один «запрос-маркер», который точно ему соответствует. Тогда система идет вглубь «облака» запросов и сравнивает «запрос-маркер» с каждым запросом, который есть в облаке, и привязывает к странице:
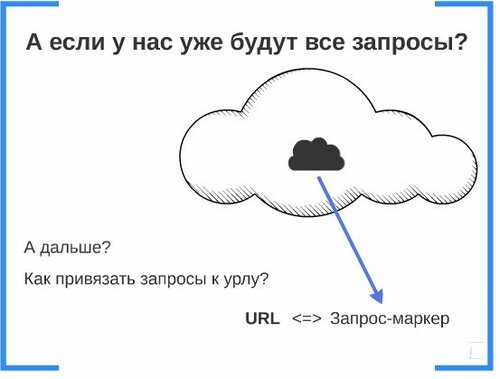

Как видно из примера, такой алгоритм позволяет решить проблему поиска не только дополнительных слов в запросе (купить, цены), но и синонимов. Samsung <=> Самсунг, телевизор <=> тв.
Таким образом, время на подбор семантики с постраничным распределением существенно сокращается – достаточно раскидать по одному запросу на страницу, чтобы получить её полное семантическое ядро. В случае КП для маленького сайта это занимает менее пяти минут суммарно. Для большого интернет-магазина запросы могут быть собраны по маскам (названию категорий и товаров), и на полный сбор семантики уйдет 15-20 минут.
Плюсы данного подхода заключаются в том, что он позволяет осуществить быстрый сбор семантики для сайта любого размера; также при помощи данного метода хорошо находятся синонимы, переколдовки и дополнения запросов. Главные минусы в том, что при использовании данного подхода для составления семантики критична полнота «Облака», а результаты чувствительны к качеству выдачи поисковых систем:
Кроме того, важен правильный выбор маркеров: если странице дать неверный «запрос-маркер» – то на выходе будет получен неправильный результат.
Запросы-маркеры можно определять не только вручную, но и автоматически. Особенно важно автоматическое определение там, где вручную это делать очень и очень долго. Например, в случае некоммерческого информационного сайта:

Оригинал статьи со слайда доступен здесь.
Для автоматического определения маркеров было решено использовать данные Яндекс.Метрики. Выбор системы статистики связан с шифрованием запросов Яндексом. Из Метрики выгружается следующая связка:
URL + Key + Vis +AvgTime + AvgPage + Bounce Rate.
Далее берем каждую пару URL+Key и алгоритм на основании последующих 4х параметров определяет – соответствует ли запрос странице или нет.
На слайде ниже показан пример его работы для упомянутой выше статьи:
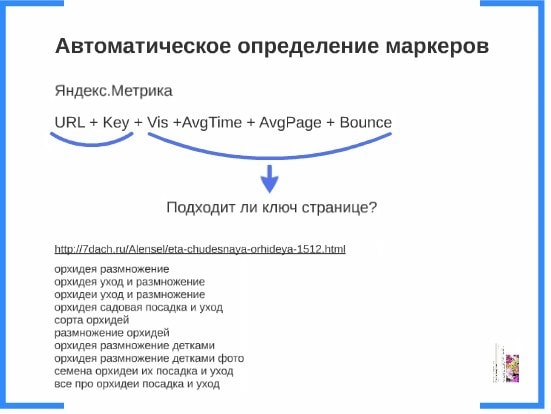
Преимущества данного алгоритма заключаются в том, что он позволяет осуществлять полностью автоматизированную работу по определению запросов для страниц, обеспечивает высокую точность результатов (90-95%) и работает для любого типа сайтов. Минусы подхода: необходимо работать с Яндекс.Метрикой; нужен органический трафик на сайт с Яндекса.
Эти запросы после ручной обработки (все-таки ~10% ошибок присутствует) могут быть использованы как «запросы-маркеры» и получения полного семантического ядра страниц.
Следующий кейс, который необходимо решать в SEO-студии – это расширение структуры сайта. На сегодняшний день удалось найти два метода решения проблемы.
Первый метод заключается в использовании текущего семантического ядра сайта для поиска схожих по SERP запросов внутри «Облака» системы. При этом хорошо находятся околотематические запросы, лингвистически не связанные с поданными на вход.
На практике это выглядит так:
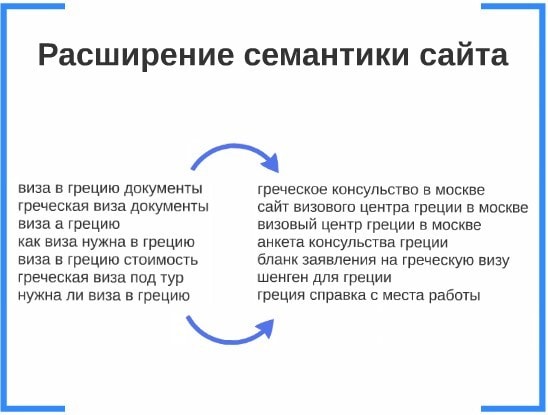
Основным преимуществом подхода является то, что он позволяет получить дополнительную семантику для расширения структуры в один клик. Главный недостаток – он не обеспечивает 100% полноты дополнительной семантики. И чем менее полное семантическое ядро будет обеспечено на входе – тем менее полное расширение будет получено в итоге.
Чтобы решить проблему полноты, можно делать несколько «итераций» поиска внутри базы (искать не только похожие на поданные на вход запросы, но и «похожие на похожие», и т.д.). Полнота найденных запросов при этом стремительно растет, но столь же стремительно падает точность. Уже на 3-4 шаге могут начать попадаться смежные тематики, а при большом ядре сайта – уже и на втором.
Второй метод – идти не от SERP, а от самого запроса. Это полезно, когда нужно углубить структуру раздела сайта или сделать сайт в неизвестной нам тематике. В этом случае из «Облака» извлекаются запросы по определенной «маске» – например «телевизор» или «виза». Можно задать более сложную маску с использованием регулярных выражений.
Получив запросы, их группируют по SERP и получают искомое углубление структуры. При этом подходе всплывает ранее неизвестная проблема – омонимия. Например, «виза» может быть в страну, а может быть банковской картой. Еще может быть виза начальника на документе; а еще есть нижнее белье – «виза виз», и мебельная фабрика «Виза».
Бывают и менее сложные случаи – само слово обозначает одно и то же, но дополнительные слова в запросе меняют интент. Например: «купить телевизор», «ремонт телевизора», «программа телевизор на компьютер», и т.д.
Можно, конечно, вручную раскидывать получившиеся кластеры, но желательно эту работу как-то автоматизировать.
Для разделения таких случаев были придуманы «тематические группы»:

Здесь, опять же, используется собственная база запросов и их SERP. Система анализирует, насколько различны URL и домены, встречающиеся в разных кластерах. Ведь очевидно, что по запросам «виза в Турцию» и «виза электрон» будут выдаваться разные сайты. По получившимся тематическим группам можно очень быстро отфильтровать даже ядро в 10-20 тысяч запросов.
Еще одна часть процесса работы с семантикой, которая может быть автоматизирована, – это построение структуры на основе полученных групп запросов.
Алгоритм здесь должен анализировать сами запросы групп воспроизводить последовательность действий человека – если есть запросы: «телевизоры», «телевизоры samsung» и «телевизоры Samsung 32 дюйма», то нам как пользователю понятно, что «телевизоры Samsung 32» дюйма – это дочерняя категория для «телевизоры samsung», а та, в свою очередь, – для «телевизоры».
На практике все сложнее – группы имеют дополнительные слова и синонимы. Как сделать автоматически?
Решение, которое было применено, – это расчет покрытия одной группой запросов другой группы.
Например, если в группе А есть запрос «телевизоры samsung», то имеет смысл рассчитать, во сколько запросов группы Б входят одновременно слова «телевизоры» и «samsung», и какая доля слов запросов группы Б таким образом покрывается. Такая работа проделывается для всех запросов группы А. Группу А называют наилучшей родительской группой («best parent»), если она покрывает группу Б лучше всех остальных групп.
Это позволяет «раскидать» полученные «группы» в структуру сайта:

Применение данного подхода позволяет заметно сократить время ручной работы по построению структуры сайта или раздела. Однако данный метод не может быть использован в полностью автоматическом режиме, т.к. получаемые связи могут быть неоднозначными (например, кластер «телевизор Samsung 32 дюйма» одновременно может быть отнесен к кластерам: «телевизоры Samsung» и «телевизоры 32 дюйма»).
Резюмируя изложенное выше, важно отметить, что разработанная система – это следующий шаг вперед в работе с семантикой после кластеризации по ТОП-ам. Теперь задачи полноты подбора и правильного распределения решаются одновременно, что позволяет оптимизатору посвящать основное время не сбору семантики, а оптимизации проекта. SEO-студии, в свою очередь, получает сокращение дорогого времени работы с семантикой при улучшении качества семантики.
Примеры использования системы Just-Magic
Кейс №1
Первый пример использования системы Just-Magic – сбор семантики в неизвестной тематике. Чтобы продемонстрировать возможности системы, в качестве образца взята тематика с омонимией (когда слово имеет несколько разных значений при одинаковом написании).
Задача: требуется узнать, как устроен поисковый спрос про визы и получить сгруппированную семантику.
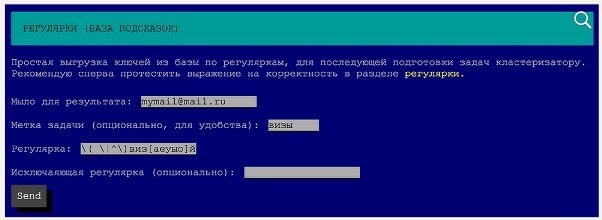
Для начала нужно получить список запросов, которые содержат слово «виза». С этой целью будем использовать функционал «регулярки»: подав на вход регулярное выражение, получим все запросы, которые ему соответствуют. Самое простое регулярное выражение будет: "виза" (без кавычек).
Однако, слово «виза» может содержаться в запросе в другом падеже и/или числе. Поэтому, переберём все возможные буквы окончания: "виз[аеуы]".
Данному регулярному выражению соответствуют: виза, визе, визу, визы. Однако у нас остался творительный падеж, «визой». Чтобы его добавить, модифицируем регулярку: "виз[аеуыо]й\?". Далее, необходимо ограничить поиск именно словами: виза, визе, и.т.д. Чтобы исключить попадания слова «ВИЗАнтия», модифицируем регулярку, указывая, что в начале должен быть либо пробел, либо начало строки, а в конце - пробел или конец строки: "\( \|^\)виз[аеуыо]й\?\( \|$\)"
Данную регулярку подаем в систему:
Оригинал скриншота доступен по ссылке.
Менее чем через минуту получаем на почту ссылку на скачивание excel-файла с результатом.
В файле с результатом содержится несколько десятков тысяч запросов. Анализировать файл вручную можно несколько дней. Поэтому, отправляем файл as is на кластеризацию.
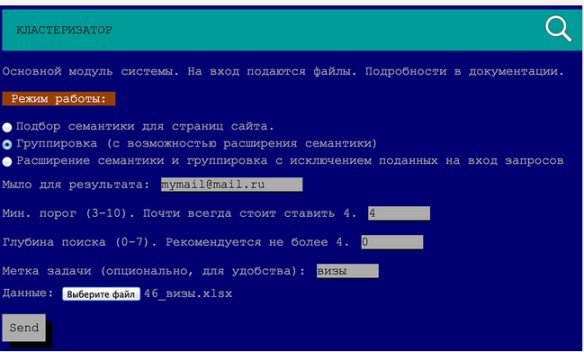
Оригинал скриншота доступен по ссылке.
И менее чем через минуту получаем на почту ссылку на скачивание excel-файла с результатом.
В выходном файле – три столбца:

Оригинал скриншота доступен по ссылке.
В первом столбце – id группы запроса. Запросы одной группы можно смело вести на одну страницу.
Во втором – id «тематики запроса». «Тематика» включает в себя несколько групп, зачем она нужна – увидим далее.
В третьем столбце содержится сам запрос.
Начиная анализировать файл, довольно быстро наталкиваемся на примеры омонимии:
- «карты мастеркард или виза»
- «виза электрон»
- «банковская карта виза»
- и.т.п.
Причем просто по стоп-словам в данном случае вырезать нельзя. Например, если мы исключим запросы по вхождению «банк», то выпадут не только нетематические запросы, но и вполне пригодные «выписка из банка для визы».
Разрешить эту коллизию поможет вторая колонка файла – «id тематики запроса». Мы видим, что запросы, содержащие слово «банк» вида «выписка из банка для визы» имеют id тематики «3», который совпадает с самой большой тематической группой релевантных запросов:

Оригинал скриншота доступен по ссылке.
Ненужные нам запросы имеют совершенно иной id тематики:

Оригинал скриншота доступен по ссылке.
При дальнейших «раскопках» обнаружим еще один пример омонимии. «Виза на документ». Система также распределила подобные запросы в отдельную тематическую группу.

Оригинал скриншота доступен по ссылке.
Исключив ненужные тематические группы, довольно быстро получаем отфильтрованное ядро. Остался последний штрих – а всё ли мы учли? Быть может, в тематике «визы» есть запросы, не содержащие слова «виза», которые мы упустили?
Ответить на этот вопрос поможет функционал расширения семантики:
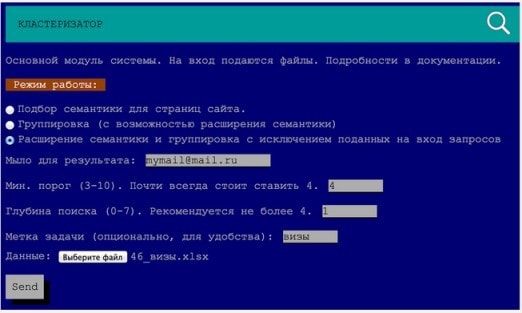
Оригинал скриншота доступен по ссылке.
Примечание: для начала устанавливаем глубину поиска - 1.
Получив результирующий файл с еще десятком тысяч запросов и просмотрев его, мы быстро обнаруживаем что забыли:
«безвизовые страны»

Оригинал скриншота доступен по ссылке.
«шенген» (какие визы, страны, анкеты, страховки,...)

Оригинал скриншота доступен по ссылке.
«посольства/консульства»
Оригинал скриншота доступен по ссылке.
И даже «мпп»

Оригинал скриншота доступен по ссылке.
И.т.д., и.т.п.
Полученная семантика уже разделена на группы, которые могут продвигаться на одной странице. Поэтому, можно на основании полученных данных начинать проектировать структуру будущего сайта.
Кейс №2
Второй кейс использования системы Just-Magic – сбор семантики для существующего сайта. Для демонстрации возможностей мы вновь рассмотрим сложный и неудобный случай – неструктурированный инфопортал 7dach.ru, на котором намешаны SEO-статьи и UGC-контент.
Задача: требуется получить максимально полную семантику по обоим типам страниц.
Оригинал скриншота доступен по ссылке.
Глядя на UGC-статьи данного сайта, даже опытный оптимизатор может прийти в замешательство, поэтому для начала мы задействуем модуль генерации запросов-маркеров. Для этого нам потребуется только ввести id счетчика метрики. Все остальное система сделает самостоятельно:

Оригинал скриншота доступен по ссылке.
Через пару минут получаем на почту файл с результатом. Система нашла для сайта 8924 запроса. Причем для многих страниц все релевантные запросы определены верно:

Оригинал скриншота доступен по ссылке.
Впрочем, чудес не бывает, и автоматика иногда ошибается. Например, есть статья «как покупать семена в интернете». А два из трёх определенных ей запросов явно являются коммерческими – хотя, и подходят по смыслу:
![]()
Оригинал скриншота доступен по ссылке.
Пробежавшись по файлу и удалив подобные запросы (их здесь порядка пятисот), можем приступать к построению полного ядра для существующих страниц. Для этого задействуем функционал постраничного сбора семантики через «запросы-маркеры».

Оригинал скриншота доступен по ссылке.
Через минуту получаем на почту файл с результатом. Ядро удалось расширить до 40 тысяч запросов. Пример семантики для одной из страниц сайта:

Оригинал скриншота доступен по ссылке.
В данном случае запрос «дачное пугало» был определен системой через Яндекс.Метрику и является «запросом-маркером». Остальные запросы подобраны системой к этому «маркеру». Обратите внимание, что данная страница является чистым UGC, и хотя данные запросы однозначно подходят ей по смыслу, необходима её оптимизация для хорошего ранжирования.
Еще один пример – на этот раз SEO-страница:

Оригинал скриншота доступен по ссылке.
Полученное ядро может быть использовано для оптимизации контента страниц и установки ссылок.
Выступление Алексея Чекушина, состоялось на втором дне отраслевой конференции для рынков интернет-маркетинга и веб-разработки «Интернет и Бизнес. Россия» в рамках секции «Инструменты и автоматизация продвижения сайтов».
Конференция «IBC Russia» проходила в Москве с 27 по 28 ноября 2014 года. Мероприятие организовано компанией «Ашманов и партнеры» совместно с Российской ассоциацией электронных коммуникаций и является крупнейшим отраслевым событием для рынков интернет-маркетинга и веб-разработки.