
Автор: Майкл Коттам (Michael Cottam) – SEO-консультант в OzTech, эксперт Moz.
Работая SEO-консультантом, я видел множество клиентов с самыми нелепыми заблуждениями в отношении XML Sitemap. Карта сайта – это мощный инструмент, но чтобы умело им пользоваться, нужны небольшая подготовка и опыт.
Индексация
Наверное, самым частым заблуждением является то, что XML-карта сайта помогает индексации страниц. Первое, что нужно чётко понять: Google не индексирует страницы только потому, что вы любезно об этом попросили. Google индексирует их потому, что: а) он их находит и сканирует; б) он считает их достаточно качественными, чтобы индексировать. Если вы указываете Google на страницу и просите проиндексировать её, совсем не обязательно, что так и будет.
Важно отметить, что отправляя файл sitemap.xml, вы даёте Google подсказку. В результате поисковик понимает, что вы считаете эти URL достаточно качественными целевыми страницами, стоящими индексации. Но это лишь подсказка, что они важны. Такая же, как ссылка на страницу из главного меню.
Последовательность
Одной из самых частых ошибок, которые я наблюдал у клиентов – отсутствие последовательности в передаче Google информации о конкретной странице. Если вы блокируете страницу в файле robots.txt, а затем включаете её в файл XML Sitemap, вы запутываете Google. Ваша карта сайта говорит: «Google, вот хорошая, качественная страница, которую тебе точно нужно проиндексировать». При этом файл robots.txt запрещает её индексировать.
То же самое касается и метатега robots: не включайте страницу в файл Sitemap, если вы планируете добавить на неё метатег robots со значением «noindex, follow». Используйте этот метатег только в том случае, если вы не хотите, чтоб Google индексировал страницу.
В целом, мы хотим, чтобы каждая страница нашего сайта попала в одну из двух категорий:
- Служебные страницы (полезные для пользователей, но не целевые страницы для поисковых запросов);
- «Вкусные», высококачественные посадочные страницы для поисковых запросов.
Всё, что попадает в категорию №1, должно блокироваться в файле robots.txt или через метатег robots со значением «noindex, follow» и не должно указываться в файле Sitemap.
Всё, что попадает в категорию №2, не должно блокироваться в файле robots.txt или с помощью метатега robots со значением «noindex» и должно присутствовать в файле XML Sitemap.
Качество сайта в целом
Судя по всему, Google оценивает качество сайта в целом и использует этот показатель в ранжировании. И здесь имеется в виду не ссылочный вес.
Подумайте об этом с точки зрения Google. Допустим, у вас есть отличная страница с прекрасным контентом, который охватывает все сигналы, начиная от релевантности и «Панды» и заканчивая вовлечённостью в социальных сетях.
Если Google видит ваш сайт как 1000 страниц контента, из которых лишь 5-6 страниц являются такими, как эта отличная страница, то он направляет пользователей на один из этих URL. Но что будет, если пользователь нажмёт на ссылку на этой странице? Он может попасть на некачественную страницу сайта. В данном случае речь идёт о плохом UX. Зачем направлять пользователей на такой сайт?
Инженеры Google явно понимают, что у каждого сайта есть определённое количество «служебных» страниц, которые полезны для пользователей, но не обязательно должны быть целевыми страницами для поисковых запросов. Это страницы авторизации, ответа на комментарий и прочие.
Если файл Sitemap содержит все эти страницы, то что вы сообщаете Google? Что у вас нет подсказок, что считать хорошим контентом на вашем сайте, а что к нему не относится.
Теперь давайте рассмотрим картину, которые вы можете нарисовать Google вместо этой: «Да, у нас есть сайт с 1000 страниц. 475 из них – страницы с отличным контентом. Остальные вы можете игнорировать. Это служебные страницы».
Допустим, Google сканирует эти 475 страниц, и с помощью своих метрик определяет, что 175 из них – это страницы класса «А»; 200 – класса «В+»; а 100 – «В» или «В-». В целом это довольно неплохой результат, и он может говорить о том, что сайт достаточно хорош для того, чтобы направлять к нему пользователей.
Для сравнения, представьте ситуацию, когда все 1000 страниц сайта внесены в файл XML Sitemap. Google смотрит на все страницы, которые вы указали как хороший контент и видит, что более 50% из них – это страницы класса «D» или «F». В среднем, сайт выглядит как некачественный, и Google, возможно, не захочет направлять к нему пользователей.
Скрываем ненужные страницы
Помните, что Google собирается использовать то, что вы подаёте через файл Sitemap, как подсказку, что считать важным на сайте. Но если какие-то URL отсутствуют в файле Sitemap, совсем необязательно, что Google их проигнорирует. У вас по-прежнему могут быть тысячи страниц с достаточным количество контента и ссылочных сигналов для индексации, хотя на самом деле они не должны индексироваться.
Используйте команду «site:», чтобы увидеть все страницы, которые Google индексирует на сайте. Так вы сможете найти страницы, о которых вы забыли, и исключить их из «средней оценки», которую Google присваивает сайту, с помощью метатега robots «noindex,follow» или блокировки в robots.txt. Как правило, самые слабые страницы в индексе будут перечислены последними в результатах поиска, выполненного с помощью оператора «site:».
Noindex против robots.txt
Существует важное, но тонкое различие между применением метатега robots и файла robots.txt для предотвращения индексации страницы. Использование метатега robots со значением «noindex,follow» позволяет передавать ссылочный вес от этой страницы к тем URL, на которые она ссылается. Если вы блокируете страницу в robots.txt, то он просто уходит в никуда.
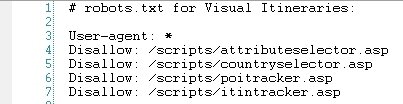 На примере выше мы блокируем страницы, которые на самом деле не являются страницами. Это отслеживающие скрипты. Поэтому мы не теряем ссылочный вес, поскольку у этих страниц нет хедера с главным меню и т.п.
На примере выше мы блокируем страницы, которые на самом деле не являются страницами. Это отслеживающие скрипты. Поэтому мы не теряем ссылочный вес, поскольку у этих страниц нет хедера с главным меню и т.п. 
Возьмём для примера страницу «Контакты» или «Политика конфиденциальности». Ссылки на них могут содержаться на каждой странице сайта – через главное меню или меню в футере. Соответственно, на эти страницы поступает большое количество ссылочного веса. Зачем от него отказываться? Не лучше ли позволить ему поступать ко всем ссылкам в главном меню? Ответ очевиден, не так ли?
Управление бюджетом сканирования
В каких случаях вместо метатега robots нужно использовать robots.txt? Возможно тогда, когда у вас есть проблемы с краулинговым бюджетом, и Googlebot тратит много времени на сканирование служебных страниц только для того, чтобы обнаружить метатег robots «noindex,follow» и покинуть их. Если у вас так много служебных URL, что Googlebot не добирается до важных страниц, тогда их нужно заблокировать в robots.txt.
У некоторых наших клиентов после очистки файла Sitemap и блокировки индексации служебных страниц улучшалось ранжирование:
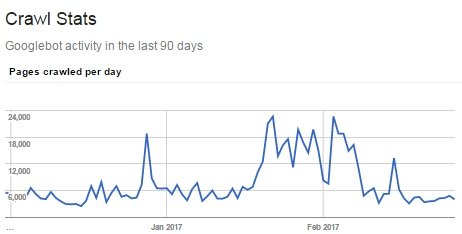
Вы действительно считаете, что 6-20 тысяч страниц вашего сайта должны сканироваться ежедневно? Или же краулинговый бюджет расходуется на служебные страницы?
Если у вас есть основной набор страниц, контент которых регулярно меняется (блог, новые продукты или страницы категорий товара) и есть множество страниц (таких, как страницы отдельных товаров), которые нужно бы индексировать, но не за счёт повторного сканирования и индексирования основных страниц, то вы можете внести основные страницы в файл XML Sitemap. Таким образом, вы дадите Google подсказку, какие страницы вы считаете более важными, чем те, что не заблокированы, но и не внесены в XML-карту сайта.
Устранение проблем индексации
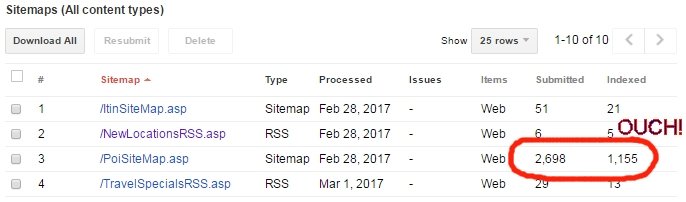
Инструмент XML Sitemap реально полезен для SEO в том случае, если вы отправляете в Google выборку страниц для индексации, но только некоторые из них индексируются. Google Search Console не предоставляет информацию о том, какие именно страницы индексируются. В сервисе можно узнать лишь общее количество проиндексированных URL в каждом файле Sitemap.
Допустим, вы являетесь владельцем e-commerce сайта, у которого 100 тыс. страниц товара, 5 тыс. страниц категорий и 20 тыс. страниц подкатегорий. Вы отправляете в Google файл XML Sitemap, который содержит 125 тыс. URL, и выясняете, что он индексирует только 87 тыс. из них. Но какие именно?
Во-первых, возможно, ВСЕ страницы категорий и подкатегорий являются для вас важными поисковыми целями. В таком случае можно создать файлы category-sitemap.xml и subcategory-sitemap.xml и отправить их в Google по отдельности. Предоставив поисковику эти файлы, вы ожидаете, что индексация будет на уровне 100%. Если же показатель ниже, тогда вы понимаете, что нужно добавить больше контента на эти страницы, увеличить ссылочный вес или же работать над обоими аспектами. Вы можете обнаружить, что страницы категорий и подкатегорий не индексируются, потому что на них указан только 1 товар (или ни одного). В таком случае на этих страницах можно настроить метатег robots «noindex,follow» и убрать их из XML-карты.
Есть вероятность, что проблема кроется в некоторых из 100 тысяч страниц товаров. Но в каких именно?
Начните с гипотез и разбейте страницы товаров по отдельным XML-файлам, чтобы проверить эти гипотезы. Вы можете тестировать несколько гипотез одновременно. Добавлять один и тот же URL в несколько файлов Sitemap допустимо.
Вы можете начать со следующих трёх теорий – не индексируются те страницы товара, на которых:
- Нет изображения товара;
- Уникальное описание включает менее 200 слов;
- Нет комментариев или отзывов.
Создайте файл XML Sitemap для каждой из этих категорий. Не обязательно, чтобы он включал все страницы в категории. Достаточно того количества, на основании которого можно будет делать обоснованные выводы об индексации. К примеру, в каждом файле может быть 100 страниц.
Ваша цель – использовать общий процент индексации в каждом из этих файлов Sitemap для определения свойств страниц, которые приводят к тому, что они индексируются или не индексируются.
Как только вы выясните, в чём заключается проблема, вы можете изменить содержимое страниц (или ссылки на них) или закрыть их от индексации. Например, у 20 тыс. из 100 тыс. страниц товара на сайте описания включали менее 50 слов. Если это не трафиковые ключевые слова, и вы получаете описания от производителей, возможно, не стоит вручную добавлять ещё 200 слов на каждую из этих 20 тыс. страниц. Можно добавить метатег robots «noindex, follow» на все страницы с описанием из менее чем 50 слов, поскольку Google всё равно не собирается их индексировать, и они снижают общую оценку качества сайта. Также не забывайте удалять такие страницы из файла Sitemap.
Динамическая XML-карта сайта
Вы, возможно, думаете: «Отлично, Майкл. Но теперь мне нужно вручную поддерживать синхронизацию XML-файла с метатегом robots на всех 100 тыс. страниц».
Но нет никакой необходимости делать это вручную. XML-карта сайта не должна быть статичным файлом. В действительности, у файла даже не обязательно наличие расширения .XML для отправки его в Google Search Console.
Вместо этого настройте правила, указывающие, должна ли страница добавляться в файл Sitemap или нет, и используйте ту же логику на самой странице, чтобы настроить метатег robots index или noindex. Если описание товара из фида производителя обновится и увеличится с 42 слов до 215, страница будет автоматически добавлена в файл Sitemap и получит метатег robots со значением «index, follow».
Когда эти файлы обрабатываются, вместо рендеринга HTML-страницы код со стороны сервера просто возвращает XML. Этот цикл повторяется для набора записей из одной из моих таблиц базы данных и выдаёт запись для каждой, которая соответствует определённому критерию.
Файл Sitemap для видео
Вместо создания файла Sitemap для видео, используйте JSON-LD и разметку schema.org/VideoObject на самой странице.
Выводы
- Будьте последовательными: если вы блокируете страницу от индексации в robots.txt или с помощью метатега robots «noindex», она не должна присутствовать в файле Sitemap.
- Используйте XML-карту сайта как инструмент для выявления и устранения проблем индексации. Позволяйте/просите Google индексировать только те страницы, которые он захочет индексировать.
- При наличии крупного сайта используйте динамические файлы sitemap.xml. Не пытайтесь вручную поддерживать синхронизацию между robots.txt, метатегами robots и файлами Sitemap.





