
Анна-Вероника Дорогуш, руководитель группы машинного обучения Яндекса, об основных алгоритмах машинного обучения, которые используются в поиске Яндекса, и о существующей инфраструктуре их использования.
Пользователь приходит на сайт поисковой системы, задает свой запрос и задача поисковой системы состоит в том, чтобы выдать по запросу топ самых релевантных документов. Документов, подходящих под данный запрос, в индексе – миллиарды, и даже после первых фильтраций их – миллионы. Эти миллионы нужно как-то упорядочить. На помощь в составлении формулы ранжирования приходит машинное обучение, а именно – Матрикснет, собственный алгоритм градиентного бустинга Яндекса.
Матрикснет – это градиентный бустинг на деревьях решений, который поддерживает все основные режимы: классификации, мультиклассификации, регрессии, ранжирования и др. Есть еще более сложные режимы – комбинации вышеперечисленных. Наш отдел разрабатывает новые режимы для нужд смежных отделов, а также внутренние пользователи Яндекса сейчас тоже могут добавлять свои собственные режимы.
Матрикснет умеет работать с пропущенными значениями – если значение какого-то фактора не указано, это не будет проблемой. Кроме того, обучение Матрикснета может быть запущено на кластере - это распределенный алгоритм. Это важно потому, что в поиске обучающие выборки сейчас такого размера, что в оперативную память одного сервера они просто не помещаются, вот почему нужно делать распределенное обучение.
Применения Матрикснета в Яндексе
Матрикснет в Яндексе применяется повсеместно. Во-первых, в поиске. Матрикснет изначально писался именно для поиска. Во-вторых, он используется в рекламе для того, чтобы показывать пользователям самые интересные для них объявления, предсказывая количество кликов по рекламе. В-третьих, прогноз погоды в Яндексе строится по формуле Матрикснета. Также алгоритм применяется во внешних проектах Яндекса – YDF, в системе рекомендаций Яндекс.Дзен, в обнаружении ботов, разрешении омонимии, сегментации пользователей и многих других.
Особенности Матрикснета
Сейчас в открытом доступе есть сразу несколько алгоритмов градиентного бустинга, поэтому я расскажу, чем от них отличается Матрикснет. Важной его особенностью является то, что для него почти не нужен подбор параметров. Почему?
Когда писался Матрикснет, его тестировали на наборе разных обучающих выборок (пулов) так, чтобы он на всех давал хорошее качество, поэтому на новых дата-сетах мы тоже получаем хорошее качество. Матрикснет легко использовать не только потому, что почти не нужен подбор параметров, но еще и потому, что в Яндексе есть инфраструктура, позволяющая запускать обучение буквально в один клик (об этом подробнее ниже). Матрикснет выигрывает по качеству у других алгоритмов градиентного бустинга на деревьях решений в режиме регрессии.

У Матрикснета сильно оптимизированное обучение. Это важно для всех задач Яндекса, но в большей степени для поиска. Хотя у нас и большие обучающие выборки, мы не можем себе позволить, чтобы формула обучалась месяц, потому что от этого будет страдать качество. Поэтому применяются всякие оптимизации, как алгоритмические, так и низкоуровневые, а также оптимизация нагрузки на сеть. Применение формулы Матрикснета тоже сильно заоптимизировано (за 1 сек. в одном потоке формула может быть применена к 100000 документов).
Градиентный бустинг на деревьях решений
Деревья решений – это такая структура данных - бинарное дерево – где во всех узлах данных, кроме листовых, находится разбиение по какому-то фактору или числу, а в листовых вершинах находятся числа. Вот таким образом дерево можно применить к документу:
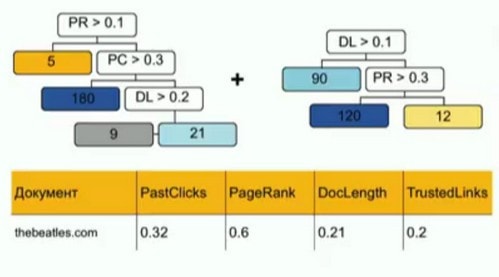
Градиентный бустинг – это сумма простых моделей (в данном случае деревьев решений), каждая из которых улучшает результат предыдущей комбинации.
Матрикснет – это не произвольные деревья решений, а так называемые «oblivious деревья решений», где на каждом уровне находится разбиение по одному и тому же признаку и одному и тому же числу. У такого способа построения дерева есть набор особенностей:
• получение очень простых моделей, устойчивых к переобучению
• разбиение пространства при помощи гиперплоскости, а значит, что для вычисления значения в листе, нужно вычислить значение всех разбиений, а значит, не важно в каком порядке это делать
• регуляризация. Нужно гарантировать отсутствие листьев, в которых почти не бывает объектов, поэтому приходится придумывать различные регуляризации, чтобы штрафовать такие ситуации
Обучение на кластере
Есть несколько способов, как градиентные бустинги на деревьях решений параллелят на несколько серверов:
1. по признакам
2. по документам
Если мы параллелим обучение по признакам (когда различные признаки лежат на нескольких серверах), то тогда количество информации, которую нужно будет пересылать по сети, будет прямо пропорционально числу документов. Так как число документов у нас очень большое и постоянно растет, ы не можем себе такое позволить и параллелим обучение по документам.
Узким местом в обучении всех градиентных бустингов на деревьях решений является выбор структуры дерева, т.е. набор признаков, из которых будет состоять наше следующее дерево. Выбор делается из двух способов:
1. master-slave режим, когда есть один ведущий узел и набор слейвов, каждый из которых считает какие-то статистики по признакам и отправляет их мастеру, который их агрегирует и выбирает лучший признак
2. all radius режим, где нет выделенного мастера, а каждый узел считает все статистики и агрегирует у себя сам
У каждого из этих подходов есть серьезные недостатки. В режиме master-slave мастер становится узким местом по сети, в режиме all radius идет очень много трафика, потому что каждый узел должен получить много информации. Например, XGBoost работает в режиме all radius, поэтому не так хорошо параллелится. В Матрикснете обе эти проблемы решены следующим способом: при выборе очередного дерева, для каждого признака выбирается случайный узел, который объявляется виртуальным мастером, и все остальные слейвы общаются уже с этим узлом. Он агрегирует нужную информацию, обсчитывает этот признак и отправляет мастеру результат.
Мы также стараемся минимизировать трафик разными способами. Например, при выборе лучшего разбиения, мы на каждом слейве выбираем набор кандидатов для лучших признаков, и виртуальным мастерам скидываем информацию только по нескольким признакам. Не вообще по всем имеющимся, а только по топу самых лучших.
Матрикснет в ранжировании
График того, как со временем менялся размер формулы ранжирования, где число итераций – это число деревьев в модели, а килобайты – это размер модели.
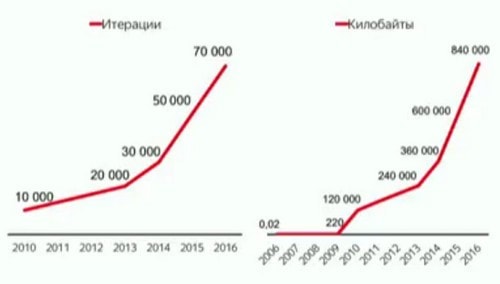
Как видим, нужно постоянно ускорять как обучение, так и применение модели, чтобы соответствовать вот такому росту.
Как же применяется машинное обучение для поиска? Для начала нужно собрать обучающую выборку, в которой будет набор пар (документ, запрос). Каждой такой паре асессоры ставят оценку – насколько этот документ подходит к запросу. Кроме того, в этой строке – документ, запрос, оценка – еще будут признаки (запросные, документные, документно-запросные). Если признак запросный, то мы его просто продублируем для всех документов запроса.
По полученной обучающей выборке и будет обучаться модель. Режимы обучения, используемые в поиске Яндекса:
• Регрессия (поточечный режим): Отличный = 1, Хороший = 0.8, Плохой = 0 => Минимизация MSE
• Попарный режим – генерируем набор пар документов с разными оценками. Формула оптимизирует правильное ранжирование внутри пар.
• Оптимизация ранжирующей функции nDCG (не гладкая, не получится сделать шаг по градиенту). Дифференцируемое приближение функции.
Задачи в Матрикснете
• Автогенерация фичей, умный выбор фичей
• Ускорение обучения (CPU, GPU)
• Оптимизации для разреженных данных
• Обучение на кластере с неравномерным распределением ресурсов
• Новые регуляризации и функции ошибок
• Инструменты для анализа обученной формулы
• Предсказание времени обучения и требуемых ресурсов
Что нужно сделать исследователю в Яндексе, если ему нужно обучить формулу? Нужно решить ряд очень сложных и первоочередных задач:
1. Найти последнюю версию алгоритма
2. Собрать данные для обучения в нужном формате
3. Найти себе вычислительные ресурсы (кластер)
4. Запустить распределенное обучение
В Яндексе есть специальная инфраструктура, которая решает все эти задачи и делает жизнь исследователей лучше – это Нирвана.
Принципы Нирваны
Нирвана – это платформа для запуска произвольных процессов. Основной ее особенностью является то, что все процессы в ней конфигурируются в виде графов.
Если взять, например, обучение формулы Матрикснета, то пользователь создает граф, оперируя определенными блоками, связывая их между собой, и запускает. Каждый блок – это операция, принимающая и генерирующая какие-то данные, через которые и осуществляется между ними связь. Пользователь запускает граф с обучением и вся история его запуска сохраняется, после этого он может посмотреть любой свой предыдущий граф, склонировать его, запустить еще раз и гарантированно получить такой же результат.
В Нирване специально уделено отдельное внимание воспроизводимости. Любые эксперименты с машинным обучением в Яндексе – воспроизводимы. Кроме того, Нирвана позволяет посмотреть историю экспериментов любых других пользователей в Яндексе, склонировать их эксперимент, как-то его изменить и перезапустить. Например, можно взять обучение нашей поисковой продакш-формулы, посмотреть этот граф, склонировать, изменить там какой-нибудь параметр и получить свою поисковую формулу, которая может быть лучше существующей.
В Нирване реализовано множество операций, сейчас их порядка 10 тысяч. Реализованы различные утилиты, есть удобный поиск по операциями. Если нужная операция не находится, то есть возможность создания своей операции. Нирвана поддерживает так называемое визуальное программирование, что значительно облегчает создание функций и композитных операций. И разумеется, в Нирване реализованы наиболее часто используемые в Яндексе алгоритмы машинного обучения – и Матрикснет, и обучение нейросетей. В Нирване очень просто обучить свою нейросеть, ничего сложного в этом нет, и даже не требуется никаких дополнительных специальных знаний.

Нирвана – довольно новая система, ее альфа-версия была запущена в 2015 году. Но у нее уже очень много пользователей – на сегодняшний день их более 2 тыс. (треть от всего Яндека), в неделю Нирваной активно пользуется около 500 человек, которые запускают по 50 тыс. графов еженедельно.





