

4 февраля 2016 года в Москве прошла первая «Data Driven SEO» - встреча по SEO, участники которой обсудили важнейшие аспекты поискового продвижения с фокусом на аналитику данных и актуальные проблемы. Организатором мероприятия выступил Rambler&Co, а партнёром конференции – Сообщество SEO.msk.
В рамках конференции Станислав Поломарь представил доклад «Семантика обработка, измерение и аналитика», посвященный вопросам работы с семантикой для крупных проектов. Основной темой выступления стало обсуждение этапов измерения и аналитики, более кратко спикер коснулся вопросов сбора и обработки данных.
Станислав Поломарь в деталях осветил подход и инструментарий продвижения больших сайтов с фокусом на аналитику (источники данных, работа с семантикой, SEO-метрики для запросов и документов, постапдейтный анализ). Подробно рассказал о том, какие данные из выдачи обязательны к анализу. В докладе были рассмотрены источники семантики, приёмы и способы их обработки, тонкости отслеживания семантики с помощью существующих сегодня метрик, контроль процесса оптимизации.
Сбор семантики
Основные источники семантики, по версии спикера, на сегодняшний день выглядят так. Это различные счётчики и данные в кабинетах вебмастера поисковых систем; автоматические подсказки; данные Wordstat; аналитика различных баров и браузеров; данные из многочисленных баз.
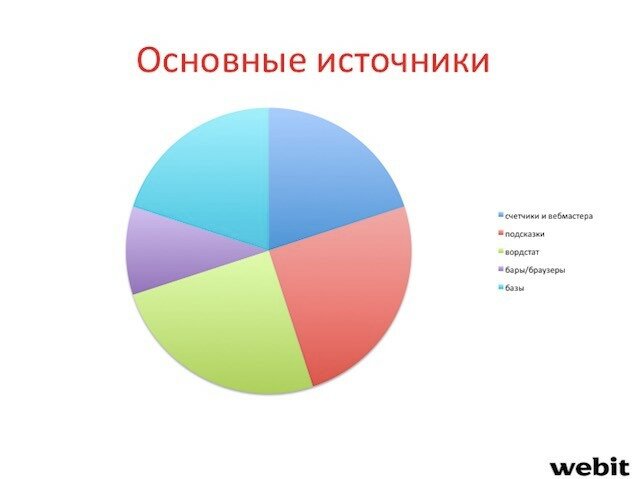
Если речь идет о больших проектах, то для анализа статистики поисковых запросов и прочей аналитики просто необходимо использовать счётчики и данные, доступные в кабинетах вебмастера в ПС. Если есть доступ к проекту, который похож по семантике на тот, с которым предстоит работать специалисту, – важно выкачивать всю семантику для дальнейшего анализа из уже работающего проекта. Впоследствии всю ненужную семантику можно отфильтровать, оставив только работающие ключевые слова.
Однако здесь необходимо учитывать значимый момент: если выбирать большие периоды, то количество актуальных и применимых данных заметно сужается. Поэтому лучше выгружать информацию за менее продолжительные периоды. Все собранные данные важно складывать в базу и в дальнейшем работать с ними.

Спикер отдельно обозначил преимущества нового Яндекс.Вебмастера. Наиболее полезным и содержательным в нём, по мнению докладчика, оказался отчёт за 2 недели. Важно работать с фильтрацией по переходам. Полезно постоянно скачивать этот отчёт, чтобы отслеживать актуальную статистику.
Упоминая о поисковых подсказках и Wordstat, Станислав Поломарь отдельно отметил, что сегодня существует большое количество сервисов, которые позволяют собрать все подсказки.

Если говорить о барах и браузерах, то база «Нейрона» позволяет собирать данные. Делать это можно и при помощи браузеров. Примерная статистика посетителей, данными о которых располагают только некоторые бары и браузеры представлена на слайде:

Главное преимущество баров и браузеров в том, что они предоставляют реальные и актуальные запросы.
Что касается баз, то статистика по некоторым из них выглядит следующим образом:

Большой объём данных на сегодняшний день собран в Just-Magic. Тем, кто не собирает подсказки в базу, рекомендуется пользоваться сервисом MOAB, он быстро работает, там есть пакетный поиск, Wordstat. Есть бесплатный сервис Bukvarix. В любом случае, если у оптимизатора имеется возможность получить больше семантики, то лучше сделать это. На следующем этапе можно будет актуализировать все данные и отфильтровать ненужное.
Обработка данных
Если специалист использует несколько ресурсов для получения данных, то в любом случае будут возникать проблемы с обработкой фразы. Чтобы облегчить процесс обработки запросов, можно использовать «отсечку по спросу». Прежде всего, важно отсеять запросы-клоны, ведь для работы с текстовыми факторами нужен лишь один вариант запроса.

В хранилище семантики существует 3 основные сущности: Проект; URL; Запрос. В качестве промежуточной сущности выступает Категория. На слайде представлены основные метрики, которые должны быть у каждого специалиста, ведущего проект:

Типовые задачи, которые решает оптимизатор, у которого есть подобное хранилище, сводятся к следующему: на базе собранных метрик отбираются документы, которые в силу выбора подлежат соответствующей отработке. Делается это в соответствии со схемой: Категория – Документы – Документ – Запросы.
Типовые сценарии обработки могут выглядеть следующим образом:

В первом случае документы уже хорошо ранжируются, по ним идет достаточный трафик, но ещё есть, что доработать. Фильтр отбирает документы, которые уже хорошо ранжируются, но трафик по которым можно ещё увеличить. Второй кейс сводится к тому, что URL-ы не так хорошо работают, как в первом; но они являются перспективными, и их в первую очередь стоит взять в работу.
Помимо обычного понимания картины, важно отслеживать метрики в динамике. Для не очень больших проектов хорошо работает съём показателей за определенный период времени.
Типовые сценарии позволяют задавать условия, чтобы отслеживать документы, с которыми произошли значимые изменения. А для того, чтобы получать конкретные рекомендации, удобно применять основные метрики, где есть наложение параметров.

Важно сводить показатели в дашборды для дальнейшего более детального анализа. Более сложная вещь – совмещение данных из пост-апдейт аналитики. Итоговый цикл сводится к сбору и обработке информации, куда входит тот или иной уровень кластеризации; отслеживанию и измерению; контролю оптимизации.
Также следует отслеживать динамику конкурентов. Однако здесь важно понимать, что своя семантика, либо внешнего сервиса (Spywords, Prodvigator, advodka и т.п.) зачастую сильно смещена и может плохо подходить для сравнения по трафику с конкурентами. Бары и браузеры дают возможность сравнить данные по запросам на реальной выборке. Однако здесь важно вычищать витальные результаты.
Чтобы отследить тренды по конкурентам, делают срез по большой выборке сайтов - то есть, по всем конкурентам. В каждой группе анализируется, какое количество сайтов в выдаче росло, а какое - сокращалось:

Завершая выступление, Станислав Поломарь перечислил несколько самых интересных трендов, которые были обнаружены за последнее время в ходе наблюдения за поисковой выдачей. Все они нашли отражение в таблице:

С полной версией презентации можно ознакомиться тут.

