
 Автор: Алексей Чекушин – SEO-эксперт Kokoc.com (Kokoc Group), создатель сервиса Just-Magic.org
Автор: Алексей Чекушин – SEO-эксперт Kokoc.com (Kokoc Group), создатель сервиса Just-Magic.org
Вместо трейлера…
Сегодня я продолжу свой рассказ о текстовых факторах и их оптимизации, начатый в предыдущей статье: «Текстовая оптимизация: жизнь без ссылок».
Мы рассмотрим такие вопросы, как:
- Почему не нужно считать BM25?
- Как делать текстовую оптимизацию без текста?
- Почему текстовая оптимизация и кластеризация если не синонимы – то близкие родственники?
- Какой эффект дает текстовая оптимизация страниц?
- И многое другое.
Часть 1. Мифология текстовой оптимизации
На что привык ориентироваться среднестатистический оптимизатор? Какие показатели оценивает? К сожалению, в его сознании их не много. Максимум, на что он ориентирован – это «плотность ключевиков»: «5 вхождений на 1000 символов». Причиной тому – целый ряд мифов, которые сложились вокруг текстовой оптимизации. Рассмотрим самые популярные из них.
Плотность ключевиков
Оптимизаторы продолжают мыслить представлениями десятилетней давности и пытаются измерять «плотность» ключевиков, нормируя при этом, почему-то даже не на количество слов, а на число символов. Видимо, из-за оплаты за копирайтинг в символах. Очевидно, что это очень сильно устаревшие представления.
Текст нужно писать на все страницы
До сих пор популярный миф гласит, что текст должен обязательно присутствовать на всех страницах сайта. Однако, целый ряд страниц вполне возможно продвигать совсем без текстов. Причем – за счет текстовой оптимизации. Этот факт взрывает мозг более чем половине оптимизаторов на рынке. Если вы посмотрите топы по коммерческим запросам, то страницы каталогов интернет-магазинов в тематиках «электроника» и «бытовая техника» двигаются вообще без SEO-текстов. Но вот в тематике «диваны», SEO-текст является обязательным условием попадания в топ.
Сказка про BM25
В последнее время стал популярен подсчет самых простых текстовых метрик из возможных – простого TF-IDF или BM25. Суровый вид формулы вселяет в обывателя уверенность, что это должно сработать. Фактически же, они представляют собой чуть улучшенную версию показателя «плотность ключевых слов».
Приведу два аргумента, которые раз и навсегда искоренят желание считать какой-либо из этих факторов в отдельности.
Аргумент первый: Факторное изобилие
Текстовых факторов Яндекс знает не два и не три. Его сотрудники заявляли, что не менее 50-ти (из 800) факторов ранжирования относятся к текстовым. Таким образом, даже если мы посчитаем один или два фактора, абсолютное большинство останется нам неизвестными.
Аргумент второй: Машинное обучение
Применение машинного обучения позволило существенно повысить эффективность ранжирующей формулы за счет использования большого количества факторов. Это делает закономерности нелинейными. То есть, больше – уже не значит лучше.
Суммируя два аргумента, мы получаем куда большую сложность, чем это представляют свидетели BM25. Подсчет 1-2 факторов из 50, да еще и при нелинейных зависимостях, вряд ли может привести к хорошему результату.
Мы построим свою формулу текстового ранжирования!
Самые продвинутые пытаются построить формулу текстовой релевантности, по аналогии с представленной Яндексом на Ромип-2006 формулой. Это уже более интересный подход, чем просто использование BM-25, но и он в нынешних реалиях не применим.
Причиной становится всё то же машинное обучение. Дело в том, что оно не только делает закономерности нелинейными, но и разными по разным группам запросов. И даже если мы сможем «оттюнить» формулу на какой-то узкой группе запросов, к другим она будет не применима.
Часть 2: Кто виноват и что делать?
Как известно, из любой ситуации есть как минимум два выхода. И у нас их, действительно, как минимум, - два:
- Сделать реверс топа, применяя машинное обучение. Фактически написать свой мини-матрикснет и обучить его на некотором числе запросов.
В этом методе нам нужно посчитать те же факторы, которые анализирует Яндекс, и на основании полученной формулы строить оптимизацию своей страницы.
- Анализировать сайты в топе, пытаясь понять оптимальные значения вхождений.
В этом случае мы не пытаемся считать факторы, а ищем закономерности, которые позволили сайтам попасть в топ.
Из двух подходов я предпочитаю второй, потому как первый дает результат в виде значений факторов, который трудно преобразовать в фактические рекомендации. Второй выдает уже готовые наборы значений.
Однако, у обоих методов есть минус. Нам надо знать, что за факторы использует поиск. В первом случае, чтобы заложить их в свою модель; во втором, чтобы знать какие вхождения искать. Но есть ли способ узнать все 50 текстовых факторов ранжирования?
50 оттенков текстовых
На самом деле, картина, конечно, не так драматична. Если вы знакомы с актуальным состоянием технологий информационного поиска, то знаете, что пять десятков различных факторов набрать просто неоткуда. Все текущие технологии, так или иначе, сводятся к BM-25-образным формулам, всевозможным учётам пар слов, межсловным расстояниям, расстоянию Левенштейна и униграммной языковой модели. Более сложные вещи, такие как как: би- и три-граммные языковые модели, смысловой анализ текста и им подобные – не получили широкого распространения, поскольку не прошли критерий стоимость/эффективность. Под «стоимостью» в данном случае понимается машинное время.
Откуда же тогда берется 50+ факторов, заявленных сотрудниками Яндекса? Здесь ответ будут знать только они, но на основании знания работы других поисков можно сделать прикидку: если применять базовые формулы к разным зонам, да еще и считать отдельно точные формы, словоформы и синонимы – получится примерно такой порядок. Таким образом, из-за схожести факторов, реально различающихся не так много. И все знать нам не нужно, важно знать как они получаются. Практика подтверждает эту гипотезу.
Часть 3: от теории к практике
Что нам потребуется для проведения текстового анализа. В первую очередь – инструментарий. Подсчет вхождений руками – занятие увлекательное, но быстро надоедает, т.к. на разбор одной страницы будет уходить порядка двух часов. Я для работы использую текстовые анализаторы «Кокоса» и just-magic.org
Анализ по одному запросу
Разбор 1-го запроса – относительно простая штука. Необходимо разобрать топ, исключить оттуда заведомо неподходящие результаты. Такими могут быть – витальные ответы, сайты с ручным хостовым бустом (Яндекс, Википедия). После этого необходимо разобрать запрос на все вхождения, которые может учитывать поиск, включая всевозможные части запроса, порядок слов и словоформы. Для двухсловного запроса по минимуму это будет 10 вариантов вхождений. А для трёхсловного – уже 22. Повторюсь – это минимум, анализатор может учитывать больше, но меньшим числом обойтись нельзя. После этого, на основании распределений числа вхождений в топе, необходимо оценить число необходимого числа вхождений каждого варианта в каждую зону документа, воспользовавшись методами работы с зашумленной информацией.
Анализ по нескольким запросам
Как правило, на страницу продвигается не один запрос, а несколько. Здесь процесс выглядит сложнее. Во-первых, необходимо понять, совместимы ли запросы между собой. То есть, могут ли они одновременно быть продвинуты на одной странице. Самый простой и эффективный способ – провести кластеризацию по «hard-методу». Подробнее – в моей статье «Азбука кластеризации».
Если этой проверки не сделать, то результаты, выданные текстовым анализатором, окажутся «бредовыми», либо (в лучшем случае) у вас будут вечные «качели», когда при переделке оптимизации будет выходить одна часть запросов, а другая – проваливаться.
Результат анализа по нескольким запросам, очевидно, должен складываться из анализа по каждому в отдельности. Однако здесь есть свои тонкости. У оптимизаторов популярно утверждение, что невозможно сделать вхождения под 10 запросов – будет переспам. Однако в реальности фраза «купить мобильный телефон» содержит сразу множество вхождений. Это и «мобильный телефон», и «купить мобильный телефон», и «купить * телефон» (последнее – вхождение через слово). Поэтому, если запросы подобраны правильно, то скомпоновать их на страницы возможно, «упаковав» одни вхождения в другие.
Примеры анализа можно найти в моей предыдущей статье о текстах: «Текстовая оптимизация: жизнь без ссылок».
Насколько эффективен текстовый анализ?
Насколько же эффективен текстовый анализ при продвижении? Для этого специально к конференции IBC Russia было проведено небольшое исследование. Для него было отобрано 5 сайтов различных коммерческих тематик по следующим критериям:
- Видимость в диапазоне 15-30% (по топ-10).
- Отсутствие ссылочного или его давняя (>180 дней) неизменность.
- Измерение дельты видимости через 2 апдейта после попадания изменений в индекс.
На каждом сайте страницы были разделены поровну между двумя различными методами оптимизации – по описанному в статье текстовому анализу и сделан подсчет необходимого числа вхождений через BM25. Сами запросы были также разделены на три группы: высоко-, средне- и низкоконкурентные.
Для текстовой оптимизации использовался текстовый анализатор сервиса just-magic.org. Для вычислений оптимальных значений BM25 – небольшой самописный скрипт.
Результат отражен на графике ниже. Дельта видимости измерялась в процентных пунктах. Т.е. рост видимости на 14% – это, например, изменение видимости с 15% до 29%:
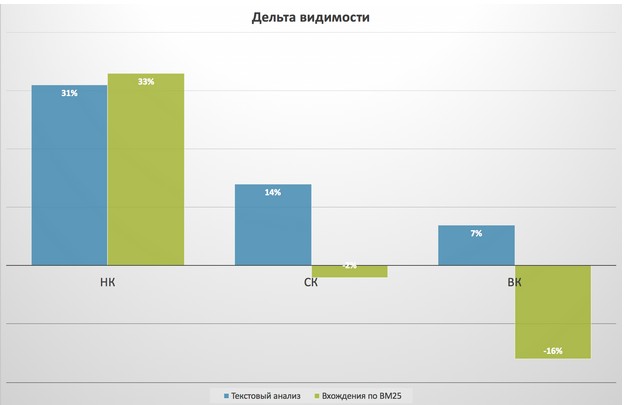
Как и предполагалось, эффективность метода серьезно зависит от конкурентности запроса. Чем более конкурентен запрос, тем меньшего прироста удавалось добиться за счет текстовой оптимизации. Интересно сравнение полноценного текстового анализа на вхождения и оптимизация по оценке BM25. На низкоконкурентных топах методы показали высокий стабильный результат, отличающийся в пределах погрешности. Но вот уже на среднеконкурентных запросах BM25 дал небольшое снижение, а по ВК-запросам – и вовсе поспособствовал полному выпадению их из топа.
В целом, никаких неожиданностей обнаружено не было. Используйте текстовую оптимизацию в работе, и ваши волосы сайты будут мягкими и шелковистыми попадать в топ.


