
Сохраненная копия документа является одним из важнейших инструментов в работе оптимизатора. Именно по содержимому сохраненной копии можно оценить, какой вариант документа на данный момент проиндексирован поисковой машиной и участвует в ранжировании.
Однако, в последнее время в Яндексе наблюдается несоответствие того варианта документа, который показывается в сохраненной копии, тому который участвует в ранжировании.
Самый распространенный вариант – вместо сохраненной копии показывается текущее содержимое документа:
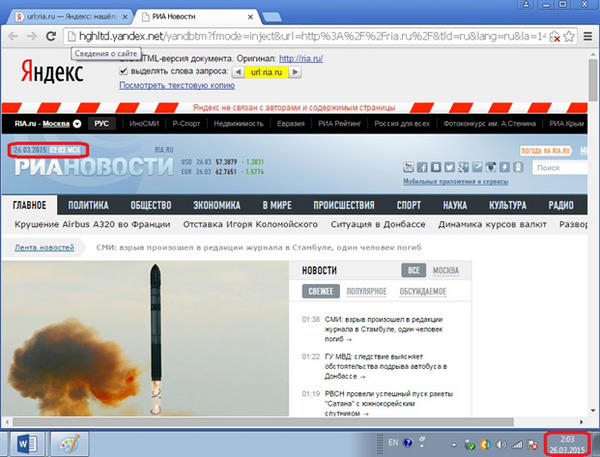
К сожалению, с некоторых пор, в шапке сохраненной копии Яндекс перестал указывать дату сохраненной копии, однако ее можно узнать, посмотрев код страницы сохраненной копии – в самом начале кода находится тег <script>, в содержимом которого есть дата:
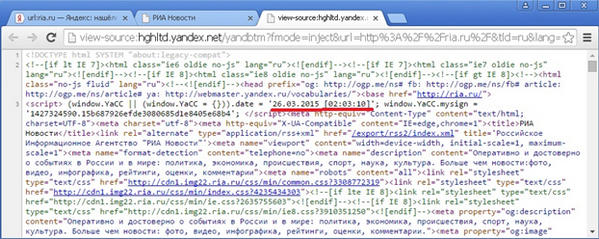
Бывают и более сложные случаи – когда в качестве сохраненной копии показывается не текущий, а действительно сохраненный вариант, только вот не тот, который на данный момент реально находится в индексе и участвует в ранжировании. И тут, для проверки, соответствует ли содержимое показываемой сохраненной копии тому варианту документа, который участвует в ранжировании, нам поможет недокументированный оператор idate, о котором я упоминал в своей статье «Недокументированные операторы языка запросов Яндекса. Продолжение сеанса поисковой магии» . Поясню на примерах.
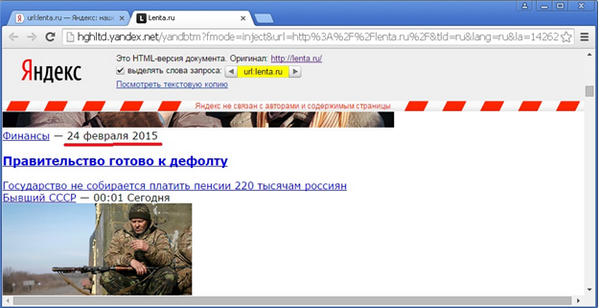
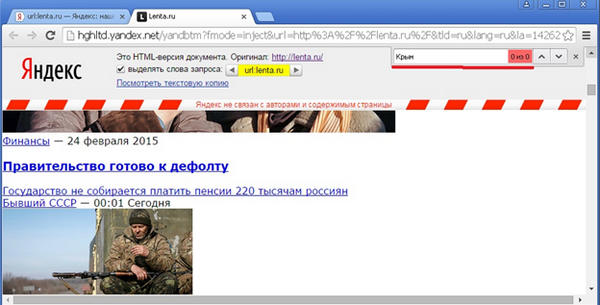
Так, например, на момент написания статьи, отдаваемая Яндексом сохраненная копия для документа, находящегося по адресу http://lenta.ru/, отдаваемая Яндексом по ссылке «Сохраненная копия», датируется 24 февраля 2015 года:
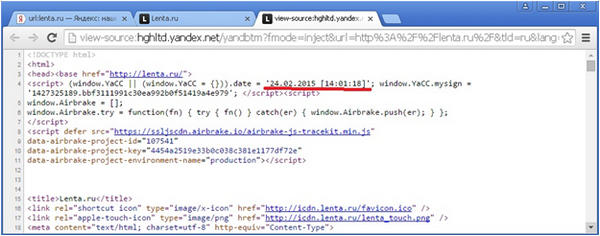
К тому же я специально выбрал для исследования такой ресурс, на котором публикуется текущая дата, и в том, что в сохраненной копии показывается действительно копия от 24 февраля, мы можем убедиться, найдя эту дату в ее содержимом:
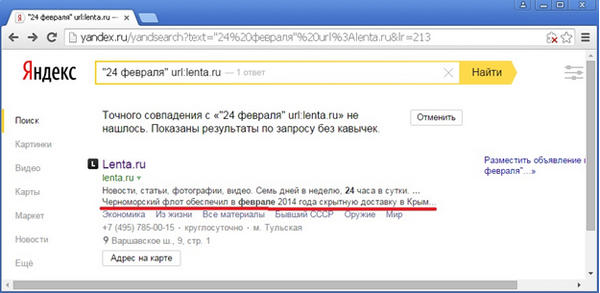
Однако, если мы попробуем поискать точную фразу «24 февраля» на исследуемой странице задав запрос в поиск, то получим ответ, что по точному совпадению с фразой «24 февраля» документ не находится:
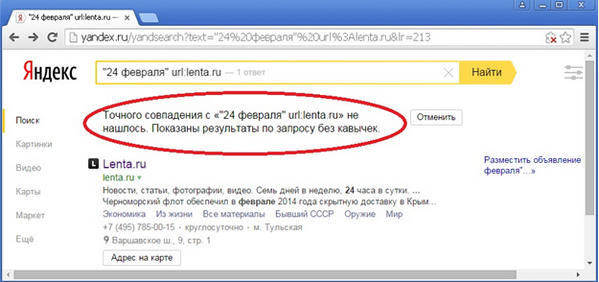
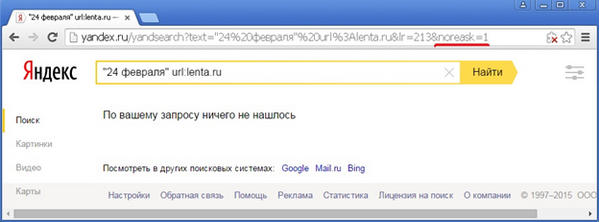
Документ присутствует в выдаче лишь из-за того, что туда автоматически добавлен результат поиска по неточной фразе без кавычек. Отменив добавление результатов по запросу без кавычек, видим, что выдача пуста (значение «1» параметра noreask в URL страницы выдачи означает, что отключено автоматическое исправление опечаток в запросе):
Ту же самую картину можно наблюдать, если попробовать поискать разнообразные точные фразы из текста сохраненной копии, например, фразу «Правительство готово к дефолту», которая видна на приведенном несколько выше скриншоте сохраненки:
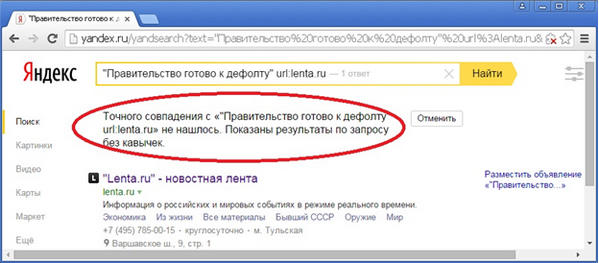
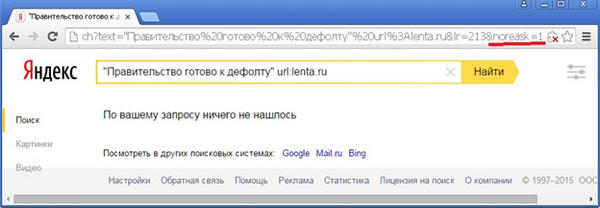
Выходит, что исследуемая страница не находится по содержимому сохраненной копии, а, значит, можно предположить, что в индексе находится другая копия этой страницы, проиндексированная в другое время. Попробуем это проверить с помощью оператора idate.
Действительно, если мы попробуем найти исследуемую страницу в Яндексе, используя в качестве значения оператора idate дату 24.02.2015, то мы получим пустой ответ:
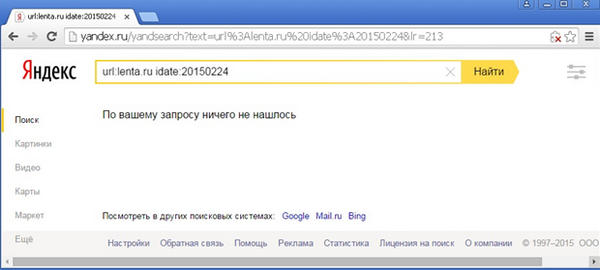
Воспользовавшись методом половинного деления, можно достаточно легко найти значение оператора idate, для которого исследуемый документ находится в выдаче:
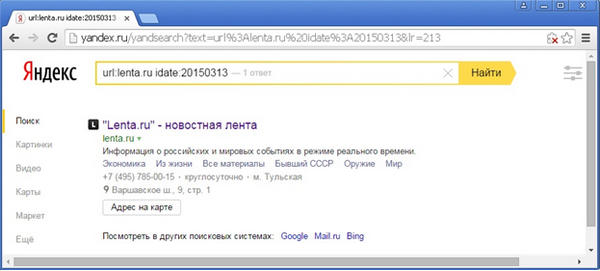
И, действительно, по точной фразе «13 марта» документ находится безо всяких автоматических исправлений:
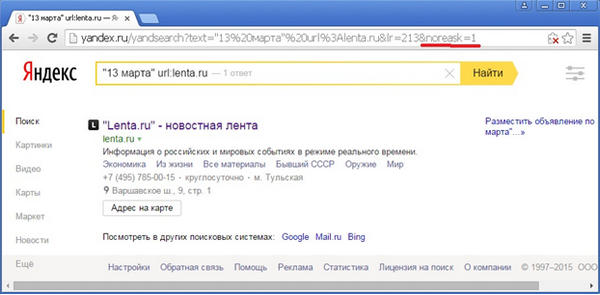
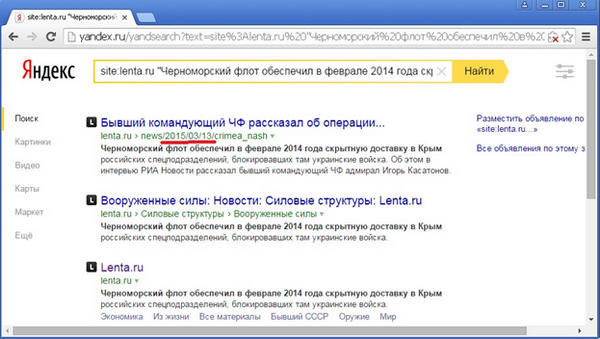
Проверим корректность работы оператора idate еще одним способом. В сниппете одного из предыдущих запросов видна фраза, явно взятая из контента страницы: «Черноморский флот обеспечил в феврале 2014 года скрытную доставку в Крым», – которая, очевидно, является частью одной из новостей:
Проверяем, что этой фразы нет в сохраненной копии от 24 февраля (в частности, вообще нет слова «Крым»):
Зато поиском по этой фразе в точном виде по сайту lenta.ru можно найти отдельную страницу новости, датированной именно 13 марта 2005 года:
Итого разными способами подтвержден факт несоответствия содержимого показываемой сохраненной копии и варианта документа, находящегося в индексе поисковой машины и участвующего в ранжировании. Факт возможности подобной рассинхронизации обязательно должен учитываться оптимизаторами и SEO-аналитиками при анализе выдачи Яндекса во избежание ложного срабатывания проверяемых гипотез.
Удачи в анализе поисковой выдачи!