
Издавна SEO-специалисты используют сохраненную копию страницы в поисковике для анализа индексации произведенных на странице изменений. Однако еще четыре года назад я заметил, что в Яндексе сохраненная копия может не совпадать с той версией страницы, которая реально находится на данный момент в поисковом индексе и используется в ранжировании. Сегодня мне хотелось бы проверить, можно сейчас ли доверять сохраненной копии Яндекса. Ну, и заодно посмотреть, как с этим обстоят дела у его основного конкурента на отечественном рынке поиска – Google.
Для анализа мне понадобится страница, на которой публикуется текущая дата. Сопоставляя дату, которая находится в сохраненной копии с датой, по которой эта страница находится в поисковике, и которая может показываться при этом в ее сниппете, можно сделать вывод о соответствии версии страницы, демонстрируемой в сохраненной копии, и версии страницы, находящейся в поисковом индексе. Для нашей цели как нельзя лучше подойдет главная страница Яндекса.
Итак, анализируем сначала ситуацию в самом Яндексе, найдя главную страницу Яндекса с помощью документированного оператора url: запросом url:yandex.ru и открыв ее сохраненную копию. Находим в ней дату (на момент анализа – это «25 февраля, понедельник, 22:23»):
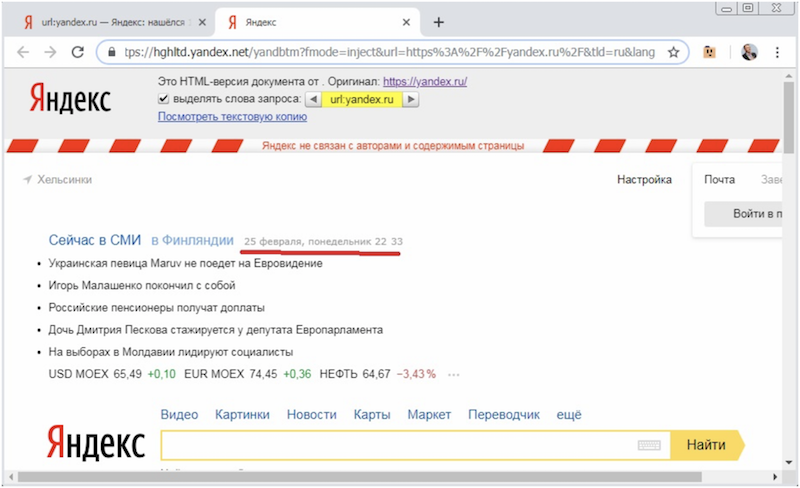
Итак, попробуем найти по точной текстовой фразе с этой датой в Яндексе его главную страницу. Увы, но сделать этого не удалось. Мы получаем сообщение, что точного совпадения не нашлось:
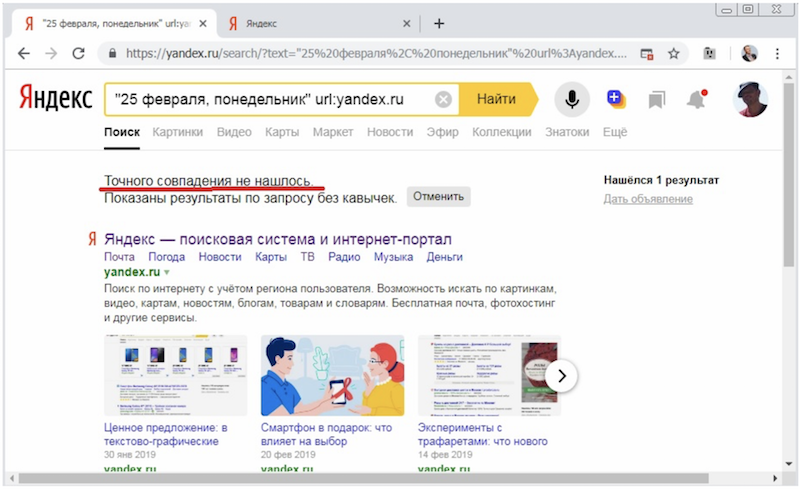
Получается, в поисковом индексе находится версия главной страницы Яндекса от другой даты. С помощью несложных манипуляций с изменением даты в поисковой фразе убеждаемся, что в индексе содержится более ранняя версия главной страницы Яндекса.
К сожалению, Яндекс не соизволил нас порадовать показом текстового соответствия в сниппете (видимо, считая данный текст служебным и малозначимым), однако отсутствие фразы «Точного совпадения не нашлось» красноречиво свидетельствует о том, что именно данная фраза содержится в той версии страницы, что находится на данный момент в поисковом индексе:
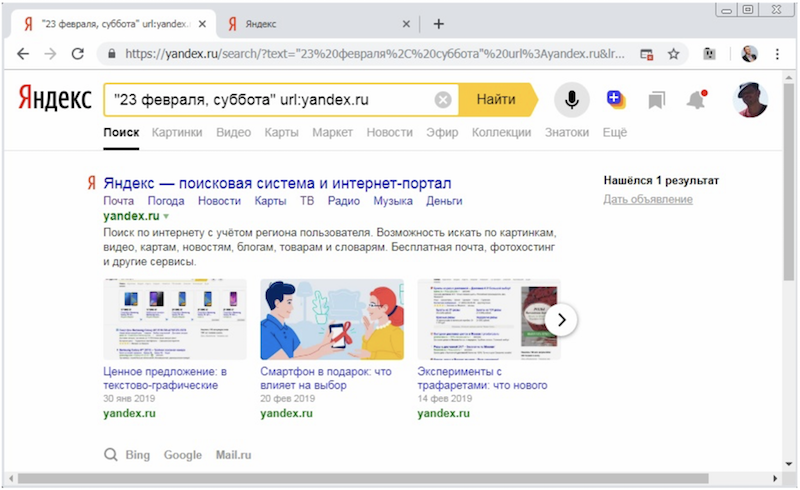
Более того, можно убедиться в том, что сохраненная копия в Яндексе может иметь несколько версий, показываемых попеременно. Так, обновляя страницу с сохраненной копией главной страницы в Яндексе, мы можем время от времени увидеть другую ее версию с другой датой (в моем случае – «24 февраля, воскресенье 22:37»), но все равно не совпадающей с той, по которой страница находится в индексе:
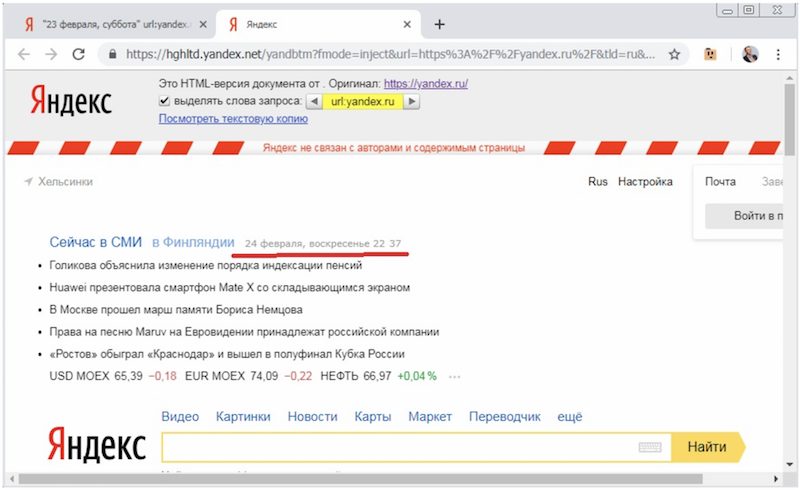
Итак, ситуация в Яндексе не изменилась. Сохраненная копия по-прежнему не совпадает с той, что находится в индексе и участвует в ранжировании.
Ну, а что же по этому поводу думает Google? Сохраненную копию страницы можно посмотреть напрямую с помощью оператора cache. Делаем в Google запрос cache:yandex.ru, получаем сохраненку и находим в ней дату:
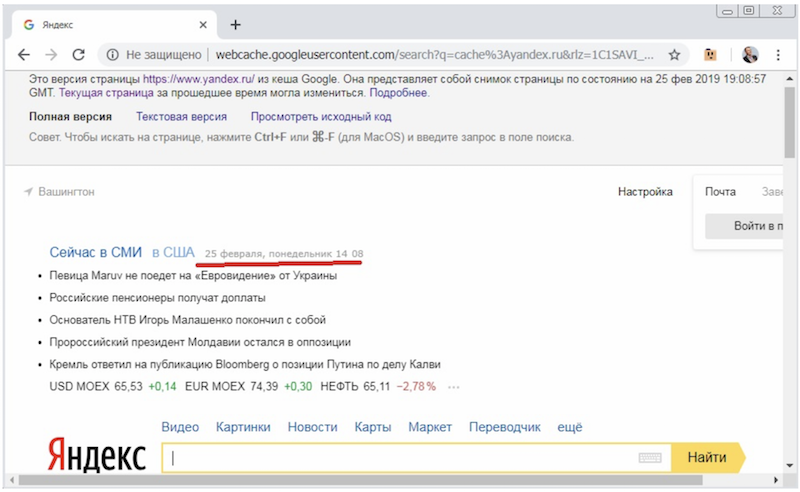
К сожалению, оператор site: в Google, в случае его применения к главной странице сайта, показывает выдачу по всему сайту, и по запросу по дате без времени мы получаем достаточно много страниц с сайта в выдаче (с сервиса Яндекс.Погода и т.п.), что затрудняет анализ. Но добавив в запрос время, убеждаемся, что по точной фразе выдача пуста:
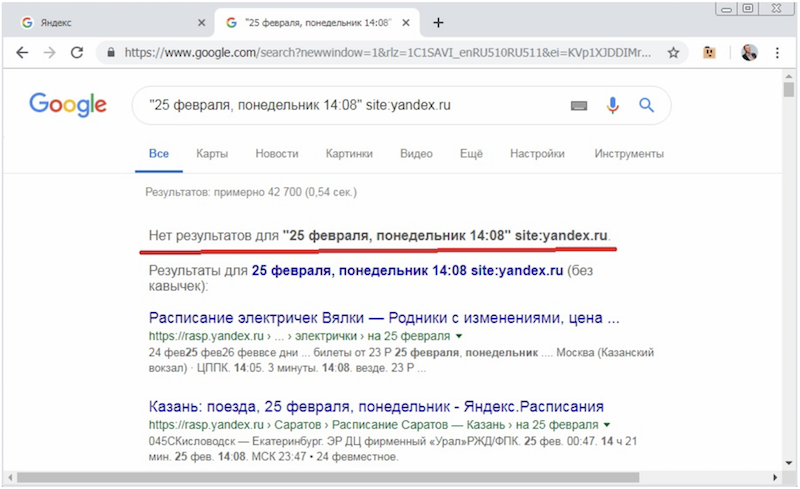
Для того, чтоб облегчить нахождение даты версии, находящейся в индексе, воспользуемся одним интересным приемом.
Есть в Google оператор получения сведений о странице info:, который показывает сниппет указанной страницы в случае наличия ее в индексе. К сожалению, этот оператор не желает корректно работать в связке с поисковым запросом, т.е. не является аналогом оператора site:. Однако, если справа от этого оператора использовать какой-либо термин, то в случае наличия его точного вхождения в тексте страницы, мы можем увидеть сниппет с подсветкой этого термина.
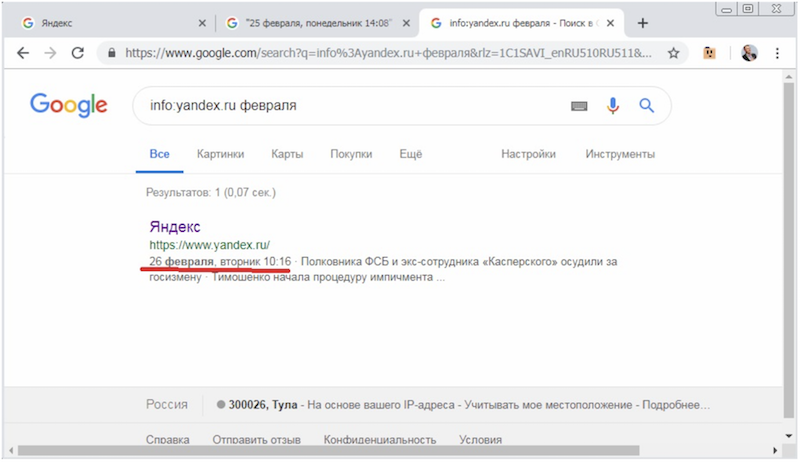
Используя в качестве такого термина название текущего месяца в соответствующем падеже, получаем отображение даты в сниппете, и убеждаемся в том, что она не совпадает с той, что содержится в сохраненке:
Проверим с помощью запроса по точной фразе, что в поисковом индексе действительно находится версия страницы с указанной датой:
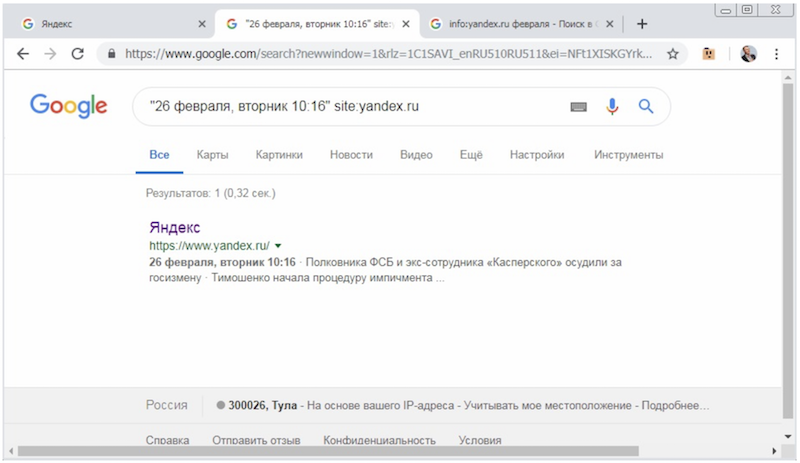
Любопытно, что в Яндексе версия анализируемой страницы в сохраненной копии свежее версии в индексе, а в Google – наоборот.
Итого в результате несложного анализа убеждаемся в том, что ни в Яндексе, ни в Google нельзя быть уверенным в том, что версия страницы, показываемая в сохраненной копии, используется для ранжирования. И этот факт обязательно необходимо учитывать при анализе поисковой выдачи, дабы избежать ложных выводов.





