
Каждые три-четыре года Google (это касается и Yahoo и MSN/Bing, но в меньшей степени) производит серьезные усовершенствования в своей метрике. Вот даты основных нововведений:
1996-1999: Ключевые слова On-page + мета данные
1999 - 2002: PR + On-page
2002 - 2005: Якорный текст + Доменное имя + PR+ On-Page
2005 - 2009: Вес доменного имени + Разнообразие ссылающихся доменов + Моделировние тематики + Якорный текст + Доменное имя + PR + On-Page
В 2010 и 2011 мы могли наблюдать введение в алгоритмы социальных сигналов из Фейсбук и Твиттера. Недавние статьи о потоке кликов (clickstream) показали нам, что и Google и Bing используют информацию о потоке кликов в своих алгоритмах, хотя это и довольно незначительная переменная в их системах (Bing открыто пользовался этим параметром на протяжении последних трех лет, Google делал это втихаря и, наверное, дольше).
Я думаю, что сигналы ранжирования следующего поколения будут полагаться на три группы метрик:
#1: Сигналы от брендов
Одна из причин, по которой Google не сразу понизил ранг JCPenney (это был первая спам-схема, о которой я узнал в конце 2009), было то, что информация и рейтинги пользователей демонстрировали полную удовлетворенность результатами поиска, особенно среди тех, кто искал по ключевым словам [платья] и [постельное белье]. Что сыграло свою роль, и почему Google не пересматривал рейтинги JCPenney? - Авторитет бренда и то, что люди были довольны результатами поиска. И только потом, когда в прессе уже начали появляться разоблачающие статьи, поисковые инженеры решили наказать нарушителя (я уверен, что они и раньше знали о манипулятивных техниках сайта, но пытались решить проблему с помощью алгоритмов, а не вручную).
Миллионы пользователей, ищущих товары в интернете, и готовых заплатить за них онлайн, даже не догадываются, как легко подтасовать результаты SERP в Google. Если посвятить этому вопросу несколько часов, то можно найти тысячи примеров манипуляций. Вот один из таких наглядных примеров – поиск по запросу [желтые кроссовки Пума]:

Я недавно купил вот такие желтые кроссовки, но самые лучшие и недорогие магазины (как вот этот) невозможно найти на первой и второй странице результатов поиска. Большинство лидеров поиска по этому ключевому слову не являются специализированными магазинами и многие из них вообще не продают такие кроссовки, которые я задал в поиск.
Если Google хочет решить эту проблему, то, я думаю, для начала надо отделить бренды (те, которые производят товар) и довольных пользователей от «генерических» сайтов (которые часто виноваты в негативном опыте пользователей, потому, что берут ограниченную ответственность за свою деятельность). Как вебмастера и владельцы малого бизнеса мы можем не согласиться, но как обычные пользователи поиска, мы понимаем, что компания Puma и магазины Amazon или Zappos должны быть на первых позициях в SERP.
Итак, какие же виды сигналов использует Google, чтобы определить, является сайт брендовым или генерическим?

Это только несколько примеров данных и источников, которые Google/Bing могут использовать в качестве сигналов, а на самом деле поисковики опираются на десятки, возможно, даже сотни переменных, которые легко интегрировать в поисковые алгоритмы (и даже научить этому компьютер, составляющий поисковые алгоритмы!)
Многие сайты-манипуляторы пытаются скопировать те или иные сигналы, но поисковики обычно давят количеством выверяемых переменных. Вот, например, обновление Vince, осуществленное в 2009 году, считается первой попыткой Google учета брендов в ранжировании.
#2: Ассоциации с реально существующими объектами
Поисковые системы всегда полагались на один универсальный алгоритм – оценку страницы на основе доступной метрики без учета всех вертикалей. Но за последние годы опытные пользователи и оптимизаторы обратили внимание, что некоторые сайты по конкретным запросам ранжируются лучше. Не то, чтобы все шансы были против аутсайдеров и новичков, но поисковые системы стремятся вывести в топ те сайты, которые, по их мнению, лучше соответствуют пожеланиям пользователей.
Например, если пользователь запрашивает ключевую фразу [баранья нога], то с точки зрения поисковых систем, уместно будет выдать список сайтов, предлагающий рецепты из бараньей ноги.
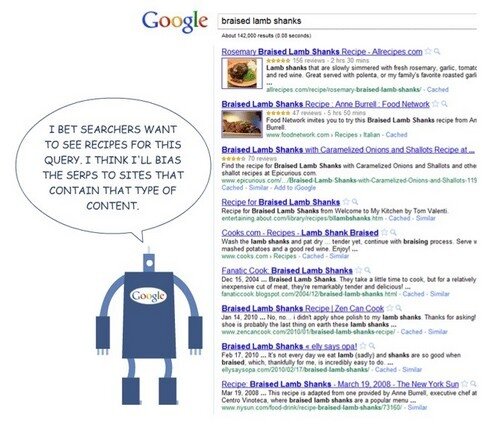
Точно с такой же позиции можно подойти к запросу о фильме «Король говорит». Поисковик скорее всего предоставит список сайтов, дающих информацию о фильмах (RottenTomatoes, IMDB, Flixster или Metacritic).
Билл Славский писал об ассоциациях в прошлом:
Вместо того, чтобы искать отдельные бренды, Google пытается разобраться, как искомый запрос описывает реально существующий объект – конкретный человек, место или вещь – и как это можно использовать в результатах поиска…
…Я уже неоднократно упоминал об этом раньше, когда Google получил патент на переписывание запроса для определения реально существующих объектов в мае 2009 года и в другой своей статье.
Недавнее приобретение Metaweb, на которое решился Google, заслуживает упоминания по ряду причин. Одна из них, это то, что Metaweb разработал собственный подход в каталогизации различных названий для одного и того же запроса.
Например, когда Google видит в сети запросы типа [терминатор], [говернатор] или [детсадовский полицейский], то их очень легко ассоциировать с Арнольдом Шварценеггером.
Ассоциативный ряд с реально существующими объектами может быть использован с целью усиления брендовых сигналов, классификации различных запросов (и видов результатов), а также помочь с запуском вертикальных/универсальных результатов, подобно Местам/Картам, Изображениям, Видео и т.п.
#3: Человеческий фактор в рейтинге и поведение довольных пользователей
В прошлом ноябре я написал пост в моем личном блоге под названием «Алгоритм + толпа = уже недостаточно»:
В последние десять лет виртуальный мир находился под контролем двойной силы: Толпы и Алгоритмов. Коллективный «пользователь» (типа архетип коллективного подсознательного – прим. перев.) в интернете – архетип Толпа – творил, кликал, выставлял рейтинги в то время как математические уравнения (архетип Алгоритмы) придавали какой-то осязаемый смысл потоку информации и давали возможность хоть что-то там найти. И эти две силы, подобно Луне над океаном, создавали приливы и отливы популярности в интернете. Кого-то эти волны выносили на гребне проходящей славы, а кого-то топили в безвестности. За это время информация стала доступной, полезной и эгалитарной (уравнительной), как никогда раньше.
Но внутреннее чутье начало мне подсказывать, что недостатки этого толпо-алгоритмического симбиоза неминуемо приведут к революции…
Приняв во внимание факт, что Google только что запустил приложение к своему браузеру Chrome, которое позволяет пользователям выборочно блокировать сайты на SERP, а также попытки учитывать пользовательскую информацию в поиске (помните SideWiki, SearchWiki, Starred Results?). Это очень хорошая тенденция, означающая, что алгоритмическая предубежденность постепенно будет уходить из поиска. Bing использует экспертную группу, оценивающую качество сайтов, точно также поступает и Google (но втихаря).
Оба поисковика принимают во внимание информацию потока кликов (ориентированную на пользователя). В этой статье можно почитать о том, как бывший инженер, контролирующий качество поиска в Google едко замечает, что Google использует точно такой же анализ потока кликов посредством тулбара, как и Bing; но ведь именно за этот инструмент Google яростно критиковал конкурента.
Вся эта информация показывает, что чем дальше, тем больше пользовательской информации будет собираться и учитываться в вычислении ранжирования сайтов. Я уже упоминал, что не люблю, когда явные сигналы о кликах используются в оценке ранжирования, но, неявные сигналы могут помочь сделать поиск качественней и приятней и в том числе показать поисковику сайты, которым можно доверять.
________________________________________
p.s. Хочу еще добавить, что вертикальные/универсальные результаты и «быстрые ответы» будут продолжать играть важную роль в ранжировании сайтов для обоих поисковиков (хотя и не являются сигналами ранжирования в классическом понимании).