
Органическая выдача – это выдача, получаемая в результате штатной работы алгоритма ранжирования. Однако в ряде случаев эти результаты по той или ной причине не устраивают разработчиков Яндекса, и в этом случае происходит «подмешивание» к топу органической выдачи результатов, полученных с помощью других способов. Причем позиции таких результатов участвуют в сквозной нумерации поисковой выдачи. На данный момент можно утверждать о наличии следующих видов примеси к органике:
- Свежие результаты
- Спектральная примесь
- Мобильные приложения
Примеси к органике примечательны тем, что через них можно попасть в топ поисковой выдачи, минуя основной алгоритм ранжирования. Это особенно актуально для высокочастотных запросов, органическая выдача по которым плотно «законсервирована» обратной связью кликовых факторов ранжирования. Рассмотрим подробнее первые два вида примеси. Страницы с мобильными приложениями относятся к специальным классам документов и находятся на специальных сайтах, и в плане достижения топа в обход органики они не так актуальны.
Свежие результаты («быстробот»)
В текущем виде введены в феврале 2012 года, хотя собственно быстроботовская примесь существовала гораздо раньше.
Идентификация этой примеси не составляет особого труда. У результатов этой примеси между номеров позиции в выдаче и сниппетов выводится дата новости. Формат даты может быть различным:
- N м назад – для результатов, датированных менее, чем час назад,
- N часов назад - для результатов датированных менее, чем сутки назад,
- «позавчера» или «вчера» - для результатов, датированных от суток до двух назад.
- ДД.ММ.ГГГГ – для результатов, датированных более чем двое суток назад.
Под сниппетом результата или блока результатов (в случае когда подмешивается несколько результатов подряд) новостной примеси идет ссылка «Еще свежие результаты по запросу …». Характерной особенностью адреса страницы выдачи только по свежим результатам является наличие в нём параметра &time_from=-3dE.
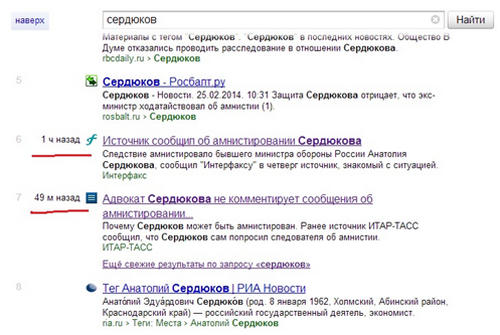
Согласно пресс-релизу Яндекса от 29 октября 2012 года «среди свежих материалов будут показаны ссылки, наиболее популярные у аудитории сервиса микроблогов Twitter». По сути, здесь мы имеем дело с прямым влиянием социальных сигналов на выдачу, пусть и неорганическую, а примесь к ней.
Основной недостаток примеси свежих результатов – короткое время жизни «бысторобовской» копии страницы (не более 3-х дней) и нестабильность примеси (может показываться разный набор подмешиваемых результатов на разных местах поисковой выдачи в разные моменты времени и в разных браузерах). Тем не менее, при попадании в данную примесь по достаточно частотному запросу можно получить на какое-то время неплохой трафик.
Спектральная примесь
Технологию «Спектр» Яндекс внедрил в декабре 2010 года. Целью ее является разнообразие топа выдачи по тем запросам, по которым подразумевается наличие различных потребностей у пользователей (т.н. «интентов»). Таким образом, к результатам органической выдачи по исходному запросу подмешиваются результаты, характеризующие тот или иной интент. Одним из способов идентификации спектральной примеси является ее отсутствие по запросу, получаемому из исходного путем добавления символа @ в его конец.
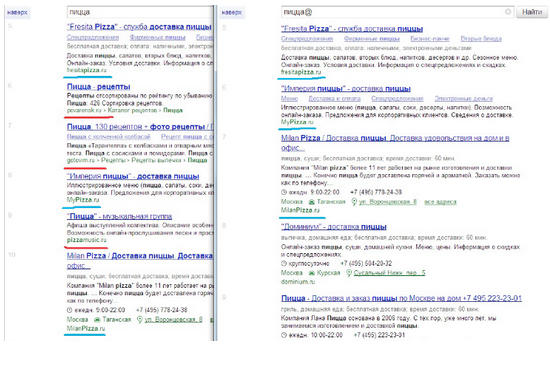
Идентифицировав результаты, попавшие в спектральную примесь, можно попытаться построить предполагаемые запросы, характеризующие подмешиваемые интенты. Есть гипотеза, что эти запросы конструируются добавлением к исходному запросу слов, характеризующий тот или иной интент (маркеров интента). Эти слова могут подсвечиваться в сниппетах наряду со словами исходного запроса, причем подсвечиваются они у всех результатов, независимо от того, органика это или примесь. Так в приведенном выше примере в сниппетах есть подсветка слова «рецепты», и можно убедиться, что подмешиваемые на 6-е и 7-е место результаты являются лидерами по запросу «пицца рецепты»:
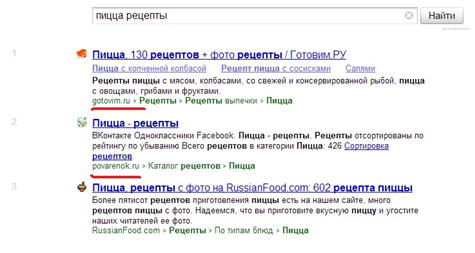
Определив запрос, характеризующий подмешиваемый интент, можно сосредоточить свои усилия на достижение топовой позиции по нему с прицелом на попадание в спектральную примесь. Несомненный плюс – это то, что конкуренция по таким запросам намного ниже, чем по исходному. Однако есть и существенные минусы – во-первых, правильная идентификация запроса, характеризующий подмешиваемый интент, является довольно непростой задачей, во-вторых, даже правильная идентификация подмешиваемого запроса и достижение топа но нему отнюдь не гарантирует попадание в спектральную примесь. Но , тем не менее, это возможно. И при попадании в спектральную примесь результат оказывается гораздо более стабильным, чем в случае быстроботовской примеси. И в третьих, идентифицированный интент может быть абсолютно некоммерческим (например, тот же «пицца рецепт»), и в случае продвижения по нему коммерческого сайта можно столкнуться с неизбежным падением конверсии по сравнению с органическими результатами поиска.
И в заключение хотелось бы упомянуть об альтернативных методах идентификации примеси. Результаты, подмешиваемые к органике, можно также идентифицировать с помощью анализа XML выдачи. У органических результатов значение поля name параметра <categ> представляет собой доменное имя, например, <categ attr="d" name="yandex.ru"/> либо идентификатор витального ответа, например, <categ attr="d" name="UngroupVital155.ru"/>. В случае же примеси в этом поле стоит URL документа, например, <categ attr="d" name="seoshnic.ru/2009/04/prodvigaem-sajt-v-top-samostoyatelno/"/>. Причем, если подмешиваемым документом является главная страница сайта, то от записи доменного имени, используемой для органических результатов, запись главной страницы в примеси отличает наличие слэша на конце, например, <categ attr="d" name="ssve.ru/"/>. Остается только отличить один вид примеси от другого.
Свежие результаты можно отличить по дате документа, которая указывается в значение параметра <modtime>, например, <modtime>20090716T040000</modtime>. Если дата не старше трех дней от текущей, то можно утверждать, что примесь быстроботовская.
Мобильные приложения легко идентифицировать по значению поля id параметра doc. Оно имеет следующий вид: <doc id="84-">.
Все результаты, идентифицированные как примесь, можно считать спектральной примесью.
Единственный минус данного типа идентификации – это то, что XML-выдача может в ряде случаев не совпадать с выдачей, показываемой пользователю в браузере.