
Передача ссылочного веса, индексация, краулинговый бюджет
Автор: Максим Ковкрак, руководитель SEO-отдела ADINDEX — украинского агентства комплексного интернет-маркетингаСозданию статьи послужил пост Игоря Шулежко в своём фейсбуке. Он попросил своих “френдов” и “SEO-титанов” прокомментировать заявление Рэнда Фишкина о бесполезном скульптурировании PageRank (PR) старыми методами (rel=nofollow и JS).
В комментариях много дискуссий и открытых вопросов, а значит, тема актуальна.
В этой статье вы узнаете все нюансы при использовании JS для управления ссылочным весом и краулинговым бюджетом, риски и недостатки. Разберём вопросы распознавания JS гуглом, экономии краулингового бюджета, актуальности работ скульптурирования PR.
1. Сразу к сути: распознаёт ли Google JS-код?
Ответ — да.
Об этом официально говорит Google в своём блоге. Об этом говорят все топовые эксперты отрасли. Также есть множество подтверждающих тестов, один из масштабных провели специалисты из Merkle|RKG, своё заключение они изложили в статье на Search Engine Land.
Что показали результаты проведенных тестов?
- Редиректы JavaScript
Использовался метод — функция window.location. Было проведено два теста: тест А включал абсолютный URL, тест Б — относительный.
Результат:
Google быстро распознал их по схеме переадресации 301 — конечные URL заменили в индексе URL, с которых шли редиректы.- JavaScript-ссылки
Протестированы стандартные JavaScript-ссылки. Это наиболее распространенные типы ссылок, которые используются SEO-специалистами:
- Функции за пределами href AVP, но в рамках тега (“onClick”)
- Функции внутри href AVP (“javascript:window.location”)
- Функции за пределами тега a, но вызываемые в пределах href AVP (“javascript:openlink()”)
- и т. п.
Результат:
Ссылки полностью краулились и отслеживались.
- Динамическая подгрузка контента
Проверялись две ситуации:
- Возможность поисковика сканировать динамический текст, если текст находится на HTML-странице. Что-то вроде кнопки “Читать полностью”, при нажатии на которую раскрывается остальная часть контента.
- Способность поисковика принимать во внимание динамический текст, если он расположен во внешнем JavaScript-файле.
Результат:
В обоих случаях текст краулился, индексировался и влиял на ранжирование страниц.
- Динамическая загрузка метаданных и элементов страницы
Динамически внедрили в DOM различные теги, важные для SEO:
- Элементы title
- Метаописания
- Метатеги robots
- Теги canonical
Результат:
Во всех случаях теги краулились — точно так же, как HTML-элементы в исходном коде.
Итого: Google давно научился распознавать JS-код как простой, так и сложный. Он не просто выполняет различные типы событий JavaScript, но и индексирует динамически генерируемый контент, читая DOM.
Другой вопрос, если запретить боту доступ к файлу *.js, в котором хранится исполняемый код и скрываемый контент, вдобавок закодированный стандартом Base64. Причём в html-коде вы также не увидите URL-адреса, будет что-то вроде этого:
<span hashstring="0lrrg9c0ljrgdc70l7qvdcw" hashtype="content"> </span>
В таком случае браузеры смогут исполнять код, а Google — нет.
Да, это рабочий метод, технология называется SEOhide, но вы же понимаете разницу между “распознаёт” и “закрытый доступ”?
2. Сокрытие ссылок
Зачем возникает необходимость скрытия ссылок от поисковых систем?
- Для управления PR (простыми словами ссылочным весом).
- Экономии краулингового бюджета.
2.1. Управление ссылочным весом
История начинается с создания поисковой системы Google, особенностью которой и являлся алгоритм PageRank. Идея заключалась в том, что страница считается тем “важнее”, чем больше на неё ссылается других страниц. При этом также учитывается “важность” ссылающихся страниц. Попросту говоря, ноу-хау заключалось в учёте внутренней и внешней ссылочной массы.
С тех пор алгоритм PageRank неоднократно подвергался изменениям, он улучшился и изменился во многих аспектах (например, учитывается тематичность ссылки, её расположение на странице), но основной принцип остаётся прежним.
Каждая страница сайта обладает определённым весом, который она с некой долей потери передаёт другим страницам через ссылки, расположенные на ней. Вес зависит от того, сколько страниц и с какой авторитетностью ссылаются на эту страницу (как внешние источники, так и внутренние страницы сайта).
Скульптурирование PR заключается в предотвращении передачи ссылочного веса бесполезным страницам сайта (или не приоритетным) и аккумулировании ссылочного веса на важных страницах.
Бесполезные — страницы не генерирующие трафик: корзина, контакты, "О нас", пользовательское соглашение и пр. Обычно ссылки на такие страницы расположены в шапке и подвале сайта, а значит собирают ссылочный вес с абсолютно всех страниц сайта.
Важные — это приоритетные страницы, находящиеся в продвижении.
1) Предотвращение передачи ссылочного веса
До 2009 г. скульптурирование ссылочного веса заключалось в использовании атрибута rel="nofollow". Значение nofollow ставилось на уровне ссылки или страницы и запрещало поисковой системе сканировать и передавать PageRank.
Изначально Google ввёл этот атрибут для борьбы со спамом. Идея заключалась в предоставлении вебмастерам инструмента борьбы с ссылками, оставленными сеошниками с целью продвижения своих проектов. Nofollow делал бессмысленным такой откровенный вид линкбилдинга.
Когда Google понял, что все за счет nofollow просто перераспределяют PR внутри своего сайта, он обновил механизм работы тега. О новой логике работы атрибута рассказал Мэтт Каттс во время конференции SMX. Позднее на его блоге вышла статья “PageRank Sculpting”.
Теперь через ссылки nofollow ссылочный вес исчезает в никуда: он не остаётся на текущей странице и не передается странице акцептору.
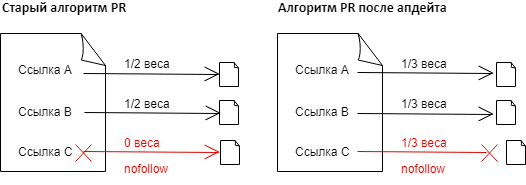
Итак, атрибут rel="nofollow" не ограничивает передачу ссылочного веса, наоборот, нужно помнить, что через такие ссылки вы будете терять PR вашего сайта.
Как мы выяснили раньше, JS не скроет ссылки сайта от Google. Остаётся рабочий метод SEOHide. Но есть один минус, который ставит под сомнение использование данной технологии и о котором стоит упомянуть — возможные санкции со стороны Google.
В июле 2015 г. Google массово разослал вебмастерам сайтов в Search Console уведомление об ошибке: “Googlebot не может получить доступ к файлам CSS и JS на сайте” и предупреждение о возможной потере позиций в поисковой выдаче в случае, если проблема не будет устранена.
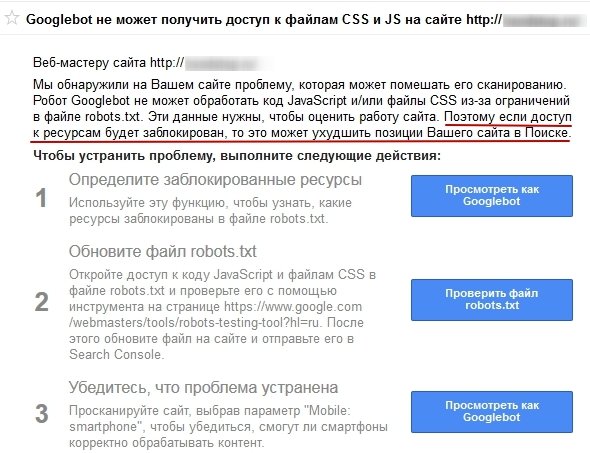
То есть, если для поисковой системы закрыт доступ к CSS и JS-файлам, есть вероятность понижения сайта в поисковой выдаче.
Принято считать, что это влияет на позиции в мобильной выдаче, проверить адаптивность сайта без анализа CSS и JS-файлов бот не сможет, а значит тест может быть не пройден. Если это так, то SEOhide не повлияет на прохождение теста Mobile Friendly и понижения не будет.
2) Передача ссылочного веса важным страницам сайта (перелинковка)
Для передачи ссылочного веса важным страницам используют различные варианты и методы перелинковки. Например, ссылки размещают в меню сайта, на фильтровой панели, на отдельных перелинковочных блоках. Логика заключается в том, чтобы накопленный ссылочный вес направить на приоритетные категории, находящиеся в продвижении.
В последнее время мы всё чаще встречаем упоминания о слабом влиянии внутренней перелинковки, всё чаще поднимается вопрос: “А стоит ли вообще заниматься скульптурированием ссылочного веса, стоит ли тратить на это время?”. В частности об этом говорит Рэнд Фишкин в статье “Как работать с внутренними ссылками сегодня: советы и практики”. Он утверждает, что классический формат скульптурирования, о котором мы говорили выше, редко эффективен, а если эффект и есть, то он небольшой:
“В настоящее время эффективность PR очень сильно уменьшилась. Тем не менее какой-то результат это приносит. В любом случае, наличие большого количества необоснованных ссылок на странице может оказать негативное влияние на ранжирование, в то время как небольшое число тщательно отобранных ссылок даёт положительный эффект. Однако в большинстве случаев оптимизация внутренних ссылок не добавляет большой ценности и не приносит значительных результатов.”
Здесь не говорится о влиянии внешних ссылок — они работают. Идёт речь об изменении эффективности алгоритма PR. В частности, об изменении влияния одной из составляющих алгоритма — внутреннего ссылочного веса. Внешние ссылки генерируют больше ценности для ранжирования и больше влияют на позиции, а вес внутренних практически не ощутим.
Высказывания Рэнда подтверждаются проведёнными тестами Дмитрия Шахова, с результатами которых он выступил на онлайн-конференции “WebPromoExperts SEO Day” 2018 года, представив доклад на тему: “Внутренняя перелинковка: мифы и реальность”. Были взяты коммерческие сайты, которые давно находятся в топе, со стабильной статистикой по позициям. Активных работ по проектам давно не проводилось.
Проверены схемы:
- шершня (перелинковка уровнями)
- линковка с релевантных страниц
- линковка с рандомных страниц
- влияние кол-ва ссылок
В ходе экспериментов не удалось добиться значительного эффекта от точечной перелинковки. Результаты были настолько слабы, что передавить влияние внешних текстовых и ссылочных факторов не удаётся — эффект близок к нулю.
Единственный найденный вариант — подтолкнуть страницу очень большим количеством ссылок. Здесь важную роль оказывает уровень траста самого хоста. Влияние будет у сайтов, которые хорошо ранжируются в поиске.
Вывод: опять-таки, очень слабое влияние внутренней перелинковки. Эффекта можно добиться только большим количеством ссылок и только для трастового сайта.
Но так ли всё однозначно с вопросом перелинковки?
Ответ — Нет :)

Было одно событие, из которого можно сделать вывод, что есть и другие факторы, влияющие на эффективность линковки.
На вопрос: “Если на странице размещено 3 ссылки: 2 dofollow и 1 nofollow, какой PR будет передаваться через каждую dofollow ссылку: 1/3 или 1/2?” Андрей Липатцев, старший специалист по качеству поиска Google, ответил, что ни 1/2, ни 1/3:
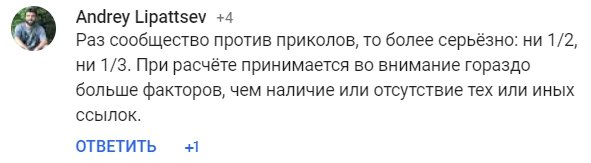
Какие это могут быть факторы? Точно неизвестно, но, скорее всего, речь идёт о “полезности и релевантности ссылки”. Все мы знаем, что на работу бэклинков влияет месторасположение ссылки на странице, переходят ли по ней пользователи, релевантна ли она содержанию — всё это работает и для внутренних ссылок сайта и их эффективности.
Вот и получается, как говорил Рэнд, что в одних случаях есть небольшой эффект от внутренней перелинковки, а в других нет. Скорее всего, всё зависит от вида реализации.
Управление ссылочным весом: общий итог
Здесь будьте очень осторожны, ниже описано заключение, к которому пришёл автор статьи, и оно может не совпадать с вашим. Это нормально, это же SEO и у нас всегда так. Если считаете по-другому, напишите свои рассуждения в комментариях к статье.Со дня своего появления алгоритм PageRank значительно изменился и усложнился. Одна из его составляющих — внутренний ссылочный вес, утратила своё былое влияние.
Обновление алгоритма требует и изменения подхода в скульптурировании ссылочного веса.
Стоит ли скрывать ссылки?
Раз влияние внутреннего веса незначительно, зачем использовать сложную технологию SEOhide для закрытия дырок перетекания ссылочного веса, реализация которой стоит денег? Скорее всего, это будет нерентабельно, учитывая то, что алгоритм передачи ссылочного веса не работает по схеме “делим поровну между всеми ссылками на странице”.
Мы не рекомендуем использовать технологию SEOhide и подобные для экономии PR-веса. Атрибут nofollow вообще будет красть ссылочный вес вашего сайта.
Что делать с перелинковкой?
Перелинковочные блоки внизу страницы сайта неэффективны, старайтесь все элементы перелинковки сделать частью пользовательского функционала, чтобы они были полезны и приносили дополнительную ценность. Тогда использование этой ссылки пользователями, если хотите — её важность, будет дополнительным сигналом влияния для страницы акцептора.
Классическую перелинковку можно использовать для максимизации индексирования.
2.2. Экономия краулингового бюджета с помощью JS
Логика какая — нет ссылки на странице, значит бот не тратит время на её индексацию.
Желание использовать JS возникает у вебмастеров, например, для того, чтобы скрыть ссылки на панели фильтрации.
Зачастую их очень много и большая часть из них закрыта от индексации. “Убрав” лишние ссылки со страницы, бот должен пойти по страницам пагинации, товарам, ссылкам на подкатегории.
Если для скрытия использовать JS, который, как мы уже выяснили, с лёгкостью распознается гуглом, мы только усугубим ситуацию и увеличим расход краулингового бюджета.
Почему увеличим? Ответ на этот вопрос полностью раскрыт в статье Барри Адамса “JavaScript и SEO: разница между сканированием и индексированием”.
Вся суть заключается в тесной работе двух парней гугла: краулера — Googlebot и индексатора — Caffeine.

Googlebot. Его задача — ходить по страницам сайта, находить все URL-адреса и сканировать их. У него также есть модуль парсинга, который смотрит на исходный код HTML и извлекает любые найденные ссылки. Парсер не рендерит страницы, он просто анализирует исходный код и извлекает любые URL-адреса, найденные в <a href="..."> фрагментах.
Когда googlebot видит новые или изменённые URL-адреса, он отправляет их второму парню.
Caffeine — парень, который сидит на месте и пытается понять полученные URL-адреса от краулера, анализируя их контент и релевантность. Он отвечает за рендеринг веб-страниц и выполнение JS кода.
В опубликованной документации Google для разработчиков объясняется, как работает их служба веб-рендеринга WRS.
Именно WRS в Caffeine выполняет JavaScript. Функция “Получить и отобразить” в Search Console позволяет посмотреть, как WRS Google видит вашу страницу.
Теперь мы выяснили, что за ширмой механизма “сканирования страниц сайта” спрятан сложный процесс взаимодействия двух систем: сканирования и индексирования.
На сайте, где большое количество ссылок не является частью исходного HTML-кода, при первом посещении краулер находит только ограниченный набор URL. Потом ему нужно подождать, пока индексатор обработает эти страницы и извлечёт новые URL, которые краулер затем просканирует и отправит индексатору. И так раз за разом.
Не исключена ситуация, когда Google будет тратить много времени на сканирование и рендеринг ненужных страниц и очень мало времени на обработку важных.
А что с SEOHide, о котором было сказано выше?
Да он будет работать, но есть куда более простой и рекомендованный способ от гугла.
В официальной справке указано:

Проще говоря, если вы хотите сэкономить краулинговый бюджет для более важных страниц, для управления приоритетом сканирования, на все второстепенные ссылки нужно добавить атрибут nofollow.
Есть один минус у этого варианта, в таком исполнении у нас получается конфликт интересов между скульптурированием PR и экономией краулингового бюджета. Если вы всё же хотите управлять ссылочным весом, помните, что через такие ссылки будет “исчезать” PR.
Вам решать, что важнее — действуйте по ситуации. Если у вас проблемы с индексацией сайта — ставьте nofollow, не давайте роботу обращать внимание на эти “бесполезные страницы”. Если не хотите терять PR, лучше просто оставить ссылки открытыми.
Если рассматривать наш пример со ссылками на страницы фильтров, которые не нужны в поисковой выдаче, то можно использовать еще два способа:
1) Закрыть такие страницы в robots.txt
Если у вас страница закрыта только тегом meta name="robots" content="noindex, follow" вы не будете экономить краулинговый бюджет. Данным тегом пользуется индексатор, а не краулер, поэтому страница будет просканирована и обработана, но в индекс не добавлена.
Нужно использовать оба метода — robots.txt заблокирует доступ краулеру.
2) Настроить в Search Console запрет на сканирование по параметрам URL
Общие выводы
- JavaScript распознаётся гуглом. Но если исполняемый код закодировать и спрятать в файле, а файл закрыть от доступа в robots.txt — получим метод скрывающий любой контент (SEOhide).
- Использование JS для скрытия ссылок только усугубит ситуацию. Во-первых, ссылки видно; во-вторых, тратится больше краулингового бюджета.
- Использование nofollow с целью управления ссылочным весом даст противоположный результат желаемому - через такие ссылки ссылочный вес будет утекать в никуда.
- SEOhide — затратный по бюджету метод с сомнительным эффектом.
- Сколько передастся PR по ссылке зависит не только от количества линков на странице и параметра nofollow. Месторасположение, использование, “важность” ссылки также влияют на данный фактор.
- Перелинковку с целью передачи PR нужно делать частью пользовательского функционала сайта, тогда можно получить результат. Перелинковка внизу страницы сайта — только с целью максимизации индексирования.
- Если смотреть на SEOhide в качестве экономии краулингового бюджета - то вариант рабочий, но есть методы и попроще.
- Экономить краулинговый бюджет без скрытия ссылок можно. Максимально эффективный способ — использовать атрибут nofollow на уровне ссылок. Для страниц, ненужных в индексе, есть ещё два варианта: закрыть в robots.txt или в настройках вебмастера. Минус всех методов — теряем PR.
- Индексирование сайта — это взаимодействие двух систем краулера и индексатора, каждый из которых руководствуется своими правилами. Краулер — файлом robots.txt, параметром ссылок nofollow, настройками в Search Console и др. Индексатор — тегом meta name="robots" content="".





