
17-й российский интернет-форум «РИФ+КИБ 2013» прошел 17-19 апреля в подмосковном пансионате «Поляны». Организатор конференции – РАЭК (Российская ассоциация электронных коммуникаций). В конференционной программе были представлены секционные заседания, круглые столы, мастер-классы и мини-секции. Конференционные мероприятия прошли в 10 параллельных потоков, всего около 100 секций.
26-я секция была посвящена поиску. Провел секцию Юрий Синодов (Roem.ru-Factus.ru-Teleus.ru). Юрий отметил, как много произошло за прошедший год: выросли мобильные возможности, противостояние на мобильных платформах обрело довольно острую стадию. Он предложил спикерам секции рассказать об итогах прошедшего года.
Первым выступил директор по технологиям Яндекса Илья Сегалович.

Илья выделил самым главным за прошедший год то, что компания научилась масштабироваться. Достижения 2012 года: была начата работа сразу над многими проектами, улучшена инфраструктура поиска, причем сразу для разных рынков с совершенно разными задачами и целями, с большой командой независимо работающих людей. Это позволило многие вещи делать гораздо быстрее. Это позволило поставить на поток серию машинного обучения, о чем было много постов на Хабрахабре (был хороший рассказ из трех публикаций о том, как была построена система машинного обучения), также Яндекс научился быстро показывать пользователям изменения и смотреть на их реакцию.
Масштабируемые системы Яндекса, построенные в 2012 году:
FML - система поточного машинного обучения качеству поиска
TDI - система массовых пользовательских экспериментов
В результате у компании получилось вырасти по качеству как по отдельным классам запросов, так и по странам. Сделана персонализация, которая без этих технологий вообще была бы невозможна, персонализация, которая отличается от других и немножечко умнее.Илья рассказал, что качество поиска - многоаспектно. Оно включает в себя:
- релевантность по типам запросов (информационным/навигационным)
- свежесть, актуальность, оригинальность
- фильтрацию порно, спама, попандеров, фишинга
- разнообразие, фильтрацию дублей
- хорошие сниппеты, группировки результатов поиска, удобное представление выдачи
Задача поиска - учиться хорошо понимать разные типы запросов, понимать, когда свежие результаты релевантны, выделять актуальность и оригинальность материалов. Справляться надо с задачами спама, фишинга, разбираться с порнографией, чтобы удовлетворить и тех, кто болезненно на нее реагирует, и тех, кто от нее счастлив. Очень много задач, и каждая из них решается своими алгоритмами, своими разработчиками. Яндекс же научился делать все одновременно.
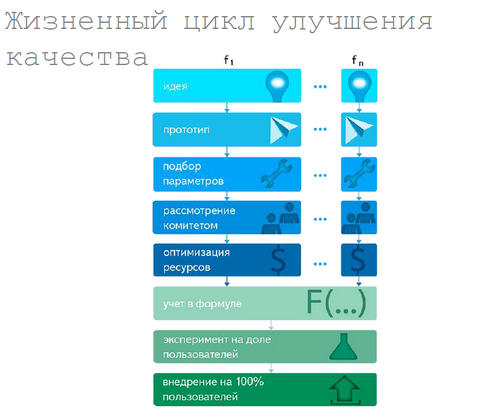
Илья рассказал, как вводится в работу новый фактор. Сначала приходит идея - "а давайте исправим, например, алгоритм нахождения оригиналов" или "добавим фактор, который повысит качество по экзотическому классу запросов, например, по поиску обзоров". Дальше подбираются параметры, находится красивое решение. Потом это обсуждается с группой людей, которые говорят - то, что тут написано, работать не будет. Потом присматриваются внимательно, и их можно убедить, что все будет работать. Осталось только доказать всем, что оно действительно улучшает поиск. Дальше начинается работа над качеством, признак добавляется в общий пул, задача ставится в очередь, просчитывается. Могут считаться одновременно десятки и сотни задач для разных пользователей. Дальше это выкатывается на пользователя в виде эксперимента, что тоже уже можно делать в большом количестве одновременно. Если пользователям понравилось - то мы молодцы.

За прошедший год в семь раз выросло количество подобранных формул. И это произошло благодаря системе масштабирования. Это видимый результат. Теперь можно гораздо быстрее улучшать и отдельные классы запросов, и делать это по разным странам.

На слайде - качество поиска по России в сравнении с конкурентами (данные за 2012-начало 2013 года). Тут много важных моментов. Надо понимать, как можно, используя построенную систему масштабирования, сделать так, чтобы не возникало артефактов. Например, построили систему, написали инструкцию. По инструкции оценки, которые сравниваются с другими системами, у Яндекса лучше. Но нет ли у Яндекса перекоса по сравнению с тем, как на самом деле пользователи реагируют на выдачу? Как раз для этого помогает система проверки качества на поисках. В частности, очень внимательно рассматриваются случаи противоречия между оценками системы и пользовательским поведением. В Турции конкурент Яндекса значительно качественнее.
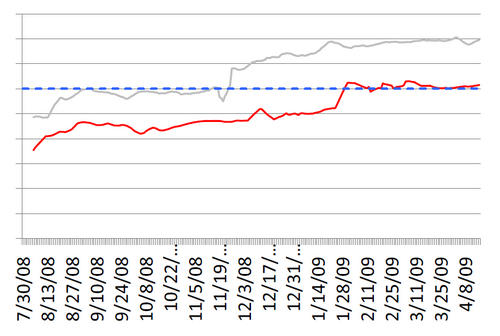
Яндекс сейчас примерно на уровне ноябрьского качества конкурента. И также видно, что конкурент серьезно занимается улучшением своего поиска. И это тоже хорошо в том смысле, что все друг на друга смотрят, и все стараются работать честно.
Для улучшения качества поиска Яндексом часто используется АB-тестинг - классический алгоритм сравнения двух версий одной системы или двух разных систем разбиением всех ответов системы на бакеты (корзины).
Если и есть какой-то артефакт той инструкции, которая написана и все время улучшается, то изучается поведение пользователей для того, чтобы понять, где поиск не соответствует ожидаемому. При введении нового алгоритма проводится сравнение двух выдач, когда аудитория делится условно пополам на тех, кто видит одну выдачу, и на тех, кто видит другую. АB-тестирование помогает понять, насколько статистически значимо отличие в поведении пользователей, по всем измеряемым показателям. Для получения статистически важных данных проводится примерно миллион измерений. TDI - новый алгоритм, который позволяет гораздо эффективнее и быстрее производить такие измерения и понимать, насколько новый алгоритм хуже или лучше старого.
Далее Илья подробней остановился на важности онлайн-метрик - ABT vs TDI:

TDI, или чередованием, компания начала активно заниматься полтора-два года назад, и вот что это такое. Например, есть система А. По запросу "карпов" она ищет сериалы. Есть система B. По запросу "карпов" она ищет шахматиста Карпова. И хочется понять, какая система лучше.
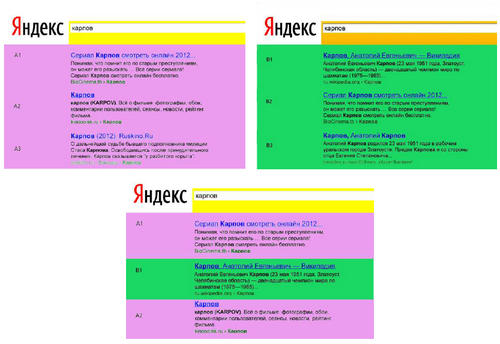
Делается простое действие. Вместо того, чтобы показывать систему А одной группе пользователей, а B - другой, результаты смешиваются. При смешивании выдачи двух систем, с разной вероятностью подставляя либо систему А, либо систему B, такой способ оказывается лучше потому, что Яндекс одному и тому же пользователю показывает сразу две выдачи, и пользователь выбирает тот результат, который ему нравится. Так улучшается и меняется формула выдачи для того, чтобы она удовлетворяла пожеланиям реальных людей, а не чьим-то представлениям о прекрасном.
Еще одним показательным примером, с точки зрения докладчика, может служить количество формул, запущенных в месяц благодаря этой всей цепочке, которую построили - одновременного машинного обучения, большого количества сотрудников, работающих над кластерами, и одновременного и очень быстрого способа измерять результаты на пользователях. Если раньше было 50 запусков в месяц, которые доходили до продакшна, то сейчас уже их за 200, а экспериментов было поставлено гораздо больше. И этот конвейер, построенный за прошедший год, дал возможность Яндексу делать уникальные продукты.
Уникальные продукты в том смысле, что Яндекс научился делать вещи, которые трудно расписать ментально, и очень трудно измерить. Персонализацию очень трудно измерить, написав инструкцию и посчитав, попросив асессора сказать - вот эта персонализированная выдача для девочки из Таганрога хороша ли? И он из каких-то своих представлений об этом человеке должен решить, хороша она или нет. Это невозможно сделать, не обучаясь на пользовательском поведении. Это история про то, как были сделаны персональные поисковые подсказки, персональный саджест. В частности, все пользовательские сессии были разбиты на кластеры, которые условно называются интересы. Получилось примерно 400 тысяч интересов. И у каждого пользователя по его поисковому поведению есть какое-то количество интересов, которыми его можно охарактеризовать. Дальше про каждый запрос тоже известно, какими интересами он может быть описан, в каких кластерах он встретился. И по предыдущим запросам, которые есть в логе у пользователя, можно определить, что его интересует музыка, игры, поэтому по начальным буквам запроса "ста" ему можно показать "сталкер" и "стас михайлов". А у другого пользователя в истории больше фильмов, книг. Ему будет показан "сталкер" Стругацких и Тарковского. По этому механизму делается персональный саджест, набор персональных подсказок благодаря тому, что поиск умеет сопоставить его интересы и интересы, которыми можно описать каждый запрос. Важный момент здесь - что это не могло бы быть сделано без механизма конвейерного измерения качества и приемки результатов.

Далее Илья рассказал о том, как поиск учится для каждого пользователя правильно выстраивать выдачу. Благодаря TDI можно описать модель пользователя по тому, какими словами он искал, какие клики он делал, какие сниппеты и слова, какие хосты ему нравились. Такая модель, которая репрезентирует пользователя, используется для того, чтобы переранжировать ответы поисковой системы. Получается очень персональная история. Ее невозможно настроить на инструкциях, ее можно настроить только на пользовательском поведении. Без механизма настройки результата по пользовательскому поведению было бы невозможно сделать нормальную персонализацию.
В простых случаях задача поиска - поднять любимые сайты пользователя выше в выдаче. В сложных случаях - понять, что человеку больше нравится. Вот что получилось в текущей модели:
- 60% потока
- в 30% запросов меняется первая пятерка (в каждом 3 запросе)
- Персонализированный первый результат на 35% кликабельней
В целом, кликабельность с учетом персонализации выросла на 5-6%. Это очень значимые изменения, которые влияют на всех нас. О них трудно красиво рассказать в том смысле, что их трудно изложить в понятной инструкции в красивый удобочитаемый слайд. Но то, что это касается всех нас - это очень важно, это то, что реально повышает наш KPI использования поисковой системы. Если при поиске на треть чаще выбирается первый результат - это значительный прорыв.
И завершил свое выступление Илья Сегалович рассказом о достижениях группы безопасности Яндекса в этом году. Во-первых, были определены поведенческие факторы заражения. То есть, можно понять, когда система ведет себя как-то необычно, включая ситуации, когда запущен Reader, или запущена Java, можно понять, когда что-то странное происходит с памятью компьютера, какие-то несанкционированные процессы запускаются, можно проверять файлы, которые загружаются с веб-страниц. Во-вторых, в 4 раза была увеличена производительность системы. То есть, теперь находится в 4 раза больше зараженных сайтов, чем в прошлом году. Например, в Турции в сутки проверяется 2 миллиона страниц, и получается 5 тысяч зараженных сайтов в турецкой зоне, в России - 40 тысяч. Поиск Яндекса на сегодняшний день показывает в Турции 270 тысяч предупреждений (в России - 6 миллионов).
Андрей Калинин (Mail.Ru Group), комментируя выступление представителя Яндекса, отметил, что по измерениям компании, отличие в качестве между разными поисковиками тоже небольшое. С другой стороны, к этому качеству путь Поиска Mail.ru был быстрее, чем у Яндекса, который начал делать свой поисковик в 2000 году, а Mail.Ru его запустил в 2010, сразу начав усиленно развивать.
Пройдя этот путь за три года, несколько смущают те шаги и те усилия, которые должны предприниматься для того, чтобы поднять качество еще выше. Да, очень много сложных механизмов, очень много формул, очень много людей, которые всем этим занимаются. Все это нужно контролировать и управлять этим. А результат, который виден, нужно объяснять полчаса. Вот сделано здесь, вот такую штуку сотворили, это очень здорово работает. И объяснять, насколько стало лучше.
Андрей рассказал, что, много общаясь с поисковыми стартапами, читая лекции по информационному поиску, видит, что на самом деле волшебное в поиске. Самое чудесное в нем, как это ни странно - это то, к чему все уже привыкли. Например, запрос "библия". Если ввести его в любой из поисковиков, они покажут то, что вы и ожидаете: ссылку на Википедию, на энциклопедии, на книги.
С другой стороны, можно взять какой-то поисковик не из первой тройки, а таких много: это книжные магазины, электронные библиотеки, торент-треккеры, где везде есть огромное количество поисковых запросов, и это тоже поисковые системы. Если вы видите Библию - это означает, что поиск хорошо ищет. Потому, что библий много: библия ведьмы, библия сатанистов, - это то, что показывают некоторые поисковики на первых местах. Есть библии коктейлей, библии рецептов. Попадание поиска в нужную библию - это уже очень хорошо. И это самое чудесное. Но это уже все сделали.
С другой стороны, что делают стартапы. Там совершенно сумасшедшие вещи творятся. Одна из самых, по словам Андрея, крышесносящих конструкций - поиск по чужим sms. Это то, что никто - ни Яндекс, ни Google, ни тем более Mail - сделать не могут в принципе. Но это же прикольно. Да, он ищет плохо - в библиях он наверняка не разбирается, никакой тонкой материи не делает; но, глядя на ребят, которые создали этот поиск, становится понятно: у них нет поисковой экспертизы, но у них есть драйв и идея.
А сейчас, если говорить за прошедший год, Поиск Mail.ru дошел до того, что по графикам конкурентов, который вот сейчас показали, у него очень хорошее положение, и это отлично, и дальше надо стараться. То, что Поиск Mail.ru сделал такой прыжок и так развился - это достижение. Но, на самом деле, интересно познакомиться с сумасшедшими стартапами и внедрить их в выдачу. Поиск по sms - все таки, нет, но если у вас есть сумасшедшие идеи - приходите. Поисковая экспертиза - от компании.
Владимир Офицеров, руководитель группы русского качества поиска Google, говоря об изменениях за прошедший год, отметил, что их по-настоящему много, и каждое из них проходит очень скрупулезное тестирование.

Первое - в этом году запущена Сеть знаний, или Knowledge Graph - панель справа от поисковой выдачи, которая показывает набор фактов. Это кажется мелкой вещью, но на самом деле это совершенно принципиальное изменение концепции поиска по сравнению с тем, каким его знали в прошлом. До этого поисковые машины находили контент в интернете и показывали его на запрос, очень сложными алгоритмами. То, что показывала поисковая машина - это было все, что существует в интернете.
Knowledge Graph - это более 500 миллионов фактов. Эти факты имеют достаточно простую структуру, триплекс: объект номер один, объект номер два, и чем они связаны. Простой пример: Том Круз, день рождения, конкретная дата. С точки зрения технической - довольно простая вещь. Но она позволяет построить базу данных фактов, в которой нет мнений, догадок, там только абсолютные факты. И каждый раз, когда вводится запрос, поиск происходит не только по тому, что находится в открытом интернете, но и по этой базе фактов. Если эти фаты являются релевантными запросу, они показываются прямо в поисковой выдаче, либо как строка, либо как панель справа.
Второе - Google Now. Это подсказки на телефоне, которые появляются без каких-либо усилий со стороны пользователя. Это тоже следующий этап. Зимой в России лишний раз снять варежки - это проблема. Идет работа и над голосовым поиском. На русском языке он уже тоже работает довольно хорошо. Если запрос относится к какому-то факту, о котором нет догадок и о котором мы знаем точно - это погода, или все то, что написано в Сети знаний - мы голосовым поиском отвечаем на этот вопрос. Можно спросить о расстоянии, или кто кому жена, какого роста, в каком фильме он играл, когда он родился и много другой информации, которую пользователь может получить из телефона, не нажимая никаких кнопок. Поиск Google пошел дальше и подумал - зачем вообще спрашивать телефон? Во многом, вещи, которые окружают пользователя, поиск уже итак достаточно хорошо знает. Он знает, что пользователь искал Depeche Mode, и, скорее всего, ему будет интересно, что группа гастролирует в Москве, и, может быть, он захочет купить билет.
Достаточно легко определить, глядя на передвижение телефона пользователя, где у него работа, а где у него дом. Тут не надо строить машинных моделей, это и так тривиально просто: с 9:00 до 19:00 пользователь на работе, потом в транспорте, потом дома. Это позволяет предложить ему маршрут, который покажет, вместе с трафиком, сколько времени сегодня займет дорога до работы, и, в случае аварии или большого трафика, предложит другой маршрут.
Из зала: Владимир, вы сказали об абсолютных фактах в Knowledge Graph. А каким образом эти факты становятся фактами, кто определят, что это - факт? Каким образом они добавляются в вашу базу и таким образом становятся абсолютными? Люди удостоверяют, асессоры, или просто по статистике?
Владимир Офицеров: Сеть знаний объединяет в себя много источников информации. Прежде всего, это Википедия и факты из Википедии, которые были проверены, в которых нет сомнения. В Knowledge Graph есть база данных фильмов, достопримечательностей, ресторанов, гостиниц, каких-то локальных объектов, достаточно известных. Там есть база данных актеров, песен, альбомов.
Из зала: Они собраны руками, или автомат принимал решение о достоверности?
Владимир Офицеров: Если вы пойдете на freebase.com, там большей частью весь Knowledge Graph представлен. Вся информация модерируется. В основном, модераторы разрешают проблемы схожести названий.
Из зала: Можно часто прочесть историю про некую актрису, которая обиженно пишет, что какой то ее недоброжелатель с хорошей кармой в Википедии непрерывно меняет ей год рождения, делает ее старше. И в Википедии 99% времени в этой статье у нее год неверный. Каким образом проверяется не то, что ее фамилия не совпадает с фамилией другого человека, а именно правильный год рождения?

Юрий Синодов: Может быть, Том Круз на год похудел на сантиметр. Но тот факт, что он снимался в "Mission: Impossible" - в принципе, абсолютный.
Из зала: Абсолютный - это признано кем? Есть 10 источников. Если есть расхождения - то кто принимает решение?
Владимир Офицеров: Обязательно курируется человеком. Любой человек может ошибиться. Часто информация приходит из нескольких источников. Поскольку эти базы данных более-менее независимы друг от друга, то, если в трех местах написано одно, а в четвертом - другое, то, скорее всего, в четвертом месте неправильно. Во всяком случае, модераторы поступают именно таким образом.
Из зала: То есть, люди на зарплате Google, фактически редакторы?
Владимир Офицеров: Да.
Из зала: То есть, это, по сути, такая своя карманная Википедия?
Владимир Офицеров: Можно сказать, что в Википедии на текущий момент присутствует порядка 4 миллионов записей, даже по сравнению с Британской энциклопедией это совершенно немыслимое количество.
Андрей Калинин: Можно поинтересоваться про Knowledge Graph. Мне сама идея очень нравится. С другой стороны, когда я с ней игрался, у меня возник такой вопрос. Круто показывается, здорово. А как вы понимаете, что нужно показать про тот или иной объект? Например, у Карла Маркса написано, где он похоронен. А у Владимира Ильича Ленина - нет. Хотя место похорон, очевидно, значительно интереснее у Ленина.
Владимир Офицеров: На самом деле, мы стараемся ответить на максимальное количество вопросов. Мы смотрим на набор запросов, и если они пишут: Том Круз Mission: Impossible - мы показываем Mission: Impossible. Если они пишут "Ленин жена" - то мы показываем жену, а не где он родился или умер. Мы смотрим на более частое расширение запросов, которое содержит имя этого объекта.
Андрей Калинин: То есть, про Карла Маркса ищут, где он похоронен, а про Ленина не надо показывать, и так все знают?
Владимир Офицеров: По всей видимости, да.
Из зала: А то, что поиск вообще начал восприниматься эмоционально, как источник какой-то литературы, вы считаете это нормальным? Раньше человек пришел, поискал, почитал, вышел. Теперь он пошел в Википедию, увидел что-то еще, пошел, поискал снова, сидит, проводит время, развлекается в поиске.
Владимир Офицеров: Если есть свободное время - то это только помогает. Одна из вещей, которые сделал Knowledge Graph - это то, что, как мы видим по нашим внутренним метрикам, один и тот же пользователь стал задавать существенно больше вопросов. Я не могу сказать, что это переход в сферу развлечений, развлечения мало соотносятся с фактами, но то, что позволяет сделать Сеть знаний - она позволяет пользователям пройти тот первый этап, когда они не знают вообще, например, что такое достопримечательности Парижа. Мы показываем карусель, в которой более-менее упорядочены по популярности те достопримечательности Парижа, которые вы можете достаточно быстро посмотреть - факты, информацию, где находятся, и веб-результаты, которые соответствуют этому запросу. И это позволяет пользователю достаточно быстро войти в курс дела и понять, что посмотреть в Париже. В прошлом не было такого источника, который полностью собирает всю информацию о достопримечательностях Парижа в одном месте. Теперь мы попытались донести эту информацию на первую страницу Google, где все эти факты представлены и позволяют вам произвести такое исследование перед тем, как задавать конкретный запрос - в какой гостинице остановиться, или в какой ресторан пойти.
Илья Сегалович: Меня смущает, что это показывается справа от выдачи, в слепой зоне. Кликают туда? И еще. Это такая вещь, совершенно ортогональная основной выдаче. То есть, люди-то пришли ответы читать, а они у вас в основной колонке. А справа вдруг показывается картинка какая-то, то ли из Википедии, то ли еще откуда. Поиск стал иллюстрированный, замечательно. Но, по-моему, это только мешает. У нас был проект в Яндекс.Новостях - пресс-портреты. Мы его практически закрасили сейчас - не потому, что он плохой был или плохо сделан, а потому, что его нужно переосмыслить. Я за то, чтобы Knowledge Graph был. Но только нужно понимать, что основная ценность, во первых - в свежести информации. Это делать дорого. А люди приходят за выдачей.
Владимир Офицеров: Современный интерфейс предполагает большой монитор, на котором и правая часть хорошо видна. В мобильной версии эта информация присутствует прямо в выдаче, и это сокращает людям количество кликов на телефоне. Если говорить о свежести, то обновления Википедии отражаются в Knowledge Graph через 30 минут. По поводу глубины - на сегодняшний день он существенно больше Википедии. Но, опять же - наличие информации не значит, что это полезная информация. Поэтому мы специально сделали сессию о том, как каждый из вас может создать маркап на вашем сайте, который в конечном итоге мы сможем использовать для того, чтобы пополнить Сеть знаний релевантной информацией.
Из зала: Владимир, как вы можете прокомментировать, что топ-10 выдачи все больше становится, во первых - рекламной площадкой, во вторых - площадкой для сервисов поисковиков.
Владимир Офицеров: Изначально поисковая машина была создана как архив, откуда выдавались результаты в случайном порядке. Потом улучшались алгоритмы сортировки. Сейчас, как правило, в первой десятке вы находите то, что вы ищете. Остается вопрос - как быстро вы найдете. Всегда были сайты погоды - но почему-то поисковики сделали погоду сами. А поскольку эти данные - это факты, то их проще предоставить пользователю напрямую в одном стандартном интерфейсе, который будет доступен и на мобильном устройстве, и который не будет требовать дополнительной передачи данных или дополнительного ожидания. Сейчас в Knowledge Graph нет рекламы. Но в будущем мы придумаем что-то чтобы увеличить конверсию на ваш сайт. Кто придет первым - тот займет место.
Илья Сегалович: Скрывается запрос у Google. И люди не могут понять, по каким запросам приходит к ним на сайт из поиска посетитель. В российской ситуации, когда несколько альтернативных поисковиков, понять, по какому запросу пришел пользователь, все таки можно - либо из одной, либо из другой системы. А в ситуации. например Германии, где 98% - это Google, все более критично. Если весь трафик становится криптованый, то все системы аналитики могут прекращать работу и идти в управдомы. В ситуации монопольной поисковой системы это вызывает вопросы. Может, кому-то это действительно нужно. Но включать это всем по умолчанию - это обман. И нужно скорее не пользователю, а нужно в ситуации монополистического рынка для вытеснения конкурентов.
Владимир Офицеров: Пользователей, которые хотят остаться анонимными - 10%, по данным использования режима анонимности в Хроме.
Из зала: Умеет ли Яндекс определять, где в поисковике находится Kарпов как шахматист, и где в поисковике Kарпов как фильм? Как Яндекс умеет эти две категории разграничивать?
Илья Сегалович: Это вероятностное решение. Первое приближение решения у нас называется Спектр. И мы работаем над следующей версией. То есть, мы понимаем, когда запрос раскладывается на разные интенты. Получается некий спектр. И дальше мы понимаем, когда Карпов-шахматист будет релевантнее. И у людей, у которых в списке интересов есть что-то, похожее на шахматы или другие косвенные интересы в выдаче, мы этого Карпова поднимем. Да, мы понимаем, когда вопрос про шахматиста.
Владимир Офицеров: Я когда говорил о Сети знаний, я не сказал, какую пользу она приносит для ранжирования такого рода запросов. Когда у нас есть факты о человеке и его взаимодействие с другими, мы легко можем каждую из этих страниц, которая возвращается в поиске, раскатегоризировать какой из этих Карповых какой. То есть, на странице на которой написан Карпов-шахматист, будет что-то про шахматы. Карпов из фильма - будет что-то про фильмы. И когда мы встречаем запрос подобного рода, мы пытаемся диверсифицировать это с тем, чтобы удовлетворить максимальное количество пользователей. Персонализация - это один из вариантов, как это можно сделать. Но персонализация загоняет вас в такой круг, от которого уйти достаточно тяжело. У вас теряется вторая интерпретация этого запроса, которую вы больше никогда не увидите.
Андрей Калинин: Поставщики контента сами хотят его показывать лучше в поиске и сокращать время от перехода пользователя к ним. Единственный вопрос - как это сделать так, чтоб это было для всех. Есть RSS-лента для контента, который обновляется. А остальной контент очень разный. И нет единого формата.
Из зала: Как вы видите будущее поиска?
Владимир Офицеров: Поиск будущего - машина, которая будет вас понимать, и с которой можно будет разговаривать.
Андрей Калинин: Мы сейчас в тренде, и мы делаем все примерно одно и то же. А нужно делать что-то новое, то, что мы пока еще не придумали.
Илья Сегалович: Население меняется, становится все более нетерпеливым. Люди все больше спешат, и надо им как-то помочь. Поиск будет меняться в сторону того, чтобы быстрее донести конечный ответ.
Из зала: По запросу порнографического содержания при вводе слова по-русски поиск выдавал откровенную порнографию, при вводе слова того же значения по-английски - вполне приличные картинки. Почему так?
Илья Сегалович: Есть некий кодекс приличного поведения. Когда вам задают вопрос, нужно, с одной стороны - ответить, с другой - сохранить при этом нормы поведения. Когда запрос неоднозначный и может быть трактован, как не порнографический, поисковые машины показывают только приличный материал. И второй пункт - даже при откровенно порнографическом запросе сохранят определенный уровень: не допускать специфической лексики в сниппетах, желательно не показывать картинки в выдаче. И ответ даден, и в более-менее приличной форме.
Андрей Калинин: Постоянно, хоть и в шутку, но обсуждается вариант - сделать отдельный поиск по порнографии. И даже обсуждали, что этот поиск должен отличаться от всех остальных тем, что у него выдача должна быть всегда разной по одним и тем же запросам. Но такого, конечно, никто не делает. Да, люди ищут, и находят. Но мы им ни в коем случае не помогаем. В подсказках порнографии быть не должно. Не показываются картинки по этим запросам.
Владимир Офицеров: Это, на самом деле, серьезная и глубокая тема для поисковых машин вообще - насколько они должны выполнять роль цензуры. Поиск должен делать цензуру? Нет. Поиск должен фильтровать детскую порнографию? Да. Большинство людей считают, что поиск, с одной стороны, не должен делать цензуру, а, с другой стороны - должен. Мы обсуждали это и пришли к выводу. Есть абсолютно белый контент - ромашки, котята. Есть абсолютно черный - детская порнография, или как сделать бомбу. И в середине есть большая серая область, которую не так легко разобрать. Откровенные фотографии войны в Сирии - это не для ребенка. Но взрослый это смотреть может - для того, чтобы понимать, что там происходит. Ограничение доступа к подобной информации вообще делает журналистику лженаукой. И мы приняли решение - сместить эту серую область к черной настолько, насколько это возможно. К тому же, в разных странах есть разные законы. Во Франции, например, мы по требованию суда удаляем нацистскую информацию.