
Перевод статьи Эппье Воджт (Eppie Vojt), консультанта по интернет-маркетингу компании JPL, где он занимается разработкой стратегий по поисковому продвижению клиентских сайтов и созданием средств для автоматизации и упрощения анализа конкурентов.
Предположим, вы разработали качественный сайт, на контент которого ссылаются другие авторитетные ресурсы. Активность в социальных сетях привлекают качественный трафик. В конце концов, ваш сайт становится авторитетом в своей теме. Вы постоянно работаете над юзабилити и стараетесь создать полезный для посетителей ресурс… И, несмотря на все это, в поисковой выдаче ваш сайт ранжируется гораздо ниже, чем куча «мусорных сайтов», которые объективно не заслужили права занимать эти позиции.
Если объяснять коротко, то проблема заключается в том, что вы тщательно выполняете рекомендации ведущих экспертов в SEO, но не можете позволить себе такое количество ссылок, которое имеют ваши бессовестные конкуренты. Может быть, стоит взять один или два урока у этих мусорных сайтов, понижающих вас в результатах SERP, и начать копировать их стратегию?
Внимание, «мусор» в выдаче!
Для того чтобы увидеть, как низкокачественные сайты поднимаются в топ поисковой выдачи, давайте рассмотрим один из наиболее вопиющих случаев, который наблюдался в англоязычной выдаче довольно продолжительное время. В рассматриваемой ситуации низкокачественный сайт подвинул вниз компании-миллиардеры по самым конкурентным запросам: «страхование автомобиля» и «автостраховка» (а также по длинному хвосту и ключевым фразам).
Посмотрите на результат выдачи. Для опытного глаза, найти здесь «мусор» не составит труда. На всякий случай, ссылка обведена в красный квадрат.
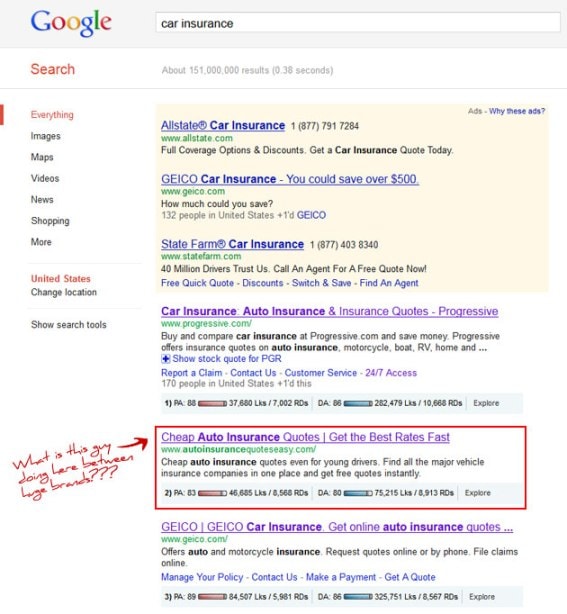
Как видно, сомнительный ресурс занял второе место в ТОП выдачи по одному из самых конкурентных запросов. Несмотря на то, что название домена не вызывает особого доверия, он ранжируется вторым по запросу «car insurance» и четвертым – по запросу «auto insurance». Думается, что этот сайт должен быть просто великолепным?
На самом деле, он забит нацеленным на получение ссылок контентом, таким как:
- списки новых и самых дорогих машин, которые можно застраховать;
- списки городов и штатов, где страхование автомобилей обходится дороже всего;
- калькуляторы, рассчитывающие величину страховых выплат;
- советы о том, как заплатить меньше при страховании автомобиля;
- списки наиболее часто угоняемых автомобилей и тех моделей, которые подвергаются актам вандализма.
Может быть, это сайт с очень привлекательным дизайном и отличным юзабилити? Рассмотрим сайт в данном аспекте подробнее:
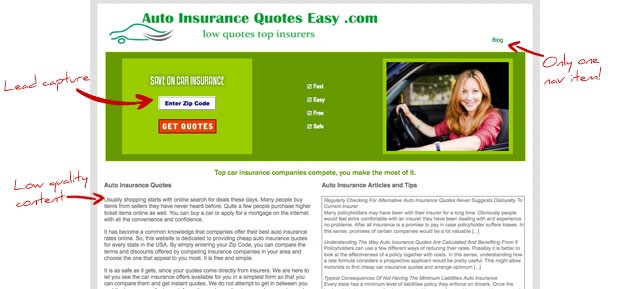
Заходя на целевую страницу сайта, пользователь видит следующее: большой баннер сверху страницы, немного посредственного текста ниже. Единственный элемент навигации – ссылка на блог. Больше на данной странице нет ничего.
Блог не многим лучше самого сайта – это блоки, наполненные низкокачественным контентом, основное назначение которого – заполнить пространство между повторяющимися с определенной периодичностью ключевыми фразами.
А что же покажет нам анализ ресурса в SEMrush? Результат неутешительный:

Выглядит так, как будто Google забыл очистить корзину.
Однако здесь не все так просто: за пару лет сайт поднялся от только что зарегистрированного домена (декабрь, 2010) до второй позиции в выдаче по высококонкурентным запросам. SEM Rush оценивает трафик, получаемый этим доменом, в эквиваленте 4 млн. долл. США в месяц!
Примечательно, что ресурс и близко не использует методы, проповедуемые современными гуру SEO. Как же такому далекому от идеала сайту удалось добиться подобных результатов?
Для того чтобы выяснить это обратимся к Open Site Explorer и Majestic SEO – эти инструменты должны помочь нам выяснить, как никудышный сайт смог завоевать в глазах поисковой системы достаточный уровень авторитета, позволивший ему победить самых знаменитых титанов страхового бизнеса. А то, что мы узнаем, можно использовать для продвижения собственных сайтов в результатах поисковой выдачи.
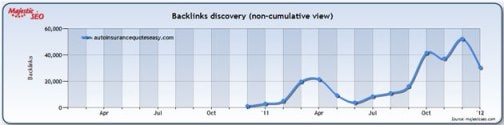
Используя экспорт Majestic SEO, можно провести анализ ссылок на сайт и проследить помесячную динамику наращивания их количества.
Ясно, что владельцы подопытного ресурса не придерживались стратегии умеренной скорости наращивания ссылочной массы. Они недолго выжидали, и добавили внушительное количество ссылок на ранней стадии развития проекта, а в октябре 2011 года стали еще более агрессивными в этом отношении. Эта вторая атака четко совпала с пиком в поисковом трафике, который заметен в статистике SEMrush, представленной на предыдущем рисунке.
Итак, мы знаем, что сайт захватил верхние строки поисковой выдачи по конкурентным ключевым словам, и удерживал их на протяжении нескольких месяцев. Мы также знаем, что он использовал агрессивную стратегию наращивания ссылочной массы. Теперь настало время глубже проанализировать, что же представляют собой эти ссылки и где они размещаются. Благодаря этой информации мы сможем понять, реально ли сделать то же самое с собственным ресурсом.
Экспортируем ссылочный профиль AutoInsuranceQuotesEasy.com из Open Site Explorer и начнем с изучения анкоров. Взглянув на рисунок, представленный ниже, становится ясно, что довольно большая доля в анкорах принадлежит целевым фразам. Среди всей анкорной массы 80% - это 10 наиболее частотных запросов.
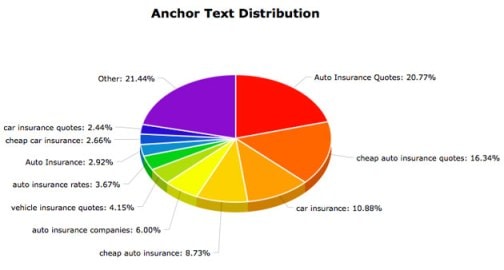
Набор анкоров довольно разнообразен, но подавляющее большинство содержит различные модификации фраз на тему «страхование автомобилей» и «автостраховки». К сожалению, в проведенном анализе пока нет ничего нового, что можно было бы взять на вооружение. Каждый из нас использует точные и разбавленные анкоры для продвижения своих ресурсов.
Однако здесь возникает резонный опрос: «Можем ли мы добиться аналогичного результата, отказавшись от дешевых ссылок, и выстраивая свою SEO-кампанию на основе релевантных, тщательно подобранных ссылок?» Чтобы ответить на этот вопрос, приступаем к следующему этапу анализа.
Определяем типы ссылок, используя семантическую разметку
Семантическая разметка, появившаяся в последние годы, также позволяет получить значимую для нас информацию. Что такое семантическая разметка? Это код, который дает браузерам (или «паукам», сканирующим сайт) информацию о своем назначении. К примеру, это всем известные элементы - такие как: <header>, <article> или <footer>. Все они присутствуют в описании HTML 5. Современный веб строится примерно так:
<div class="comment">My comment goes here</div>
или:
<div id="footer">Copyright info, etc.</div>.
К сожалению, никто прямо не указывает:
<a href="my-spammy-website" class="spam-links">My spammy anchor text</a>.
Тем не менее, в именах идентификаторов и классов содержится достаточный объем информации для того, чтобы понять назначение этих элементов. Зная ставшую стандартом систему обозначений, несложно выудить значимую для нас информацию, строчку за строчкой анализируя результат работы Open Site Explorer. Для каждой позиции мы проделаем следующие операции:
- Проследим URL страниц, на которых расположены ссылки на целевой сайт;
- Конвертируем их в формат объекта Document Object Model (DOM);
- Запустим xPath, чтобы найти ссылки на страницах и соответствующие значения href;
- Поместим в DOM все значения class или id, которые окружают ссылки.
Иными словами, проверим все блоки, в которых «сидят» ссылки, на наличие имен классов и идентификаторов, которые могут иметь значение.
Классификация ссылок
Если в ходе анализа обнаружатся совпадения в именах, то соответствующие им ссылки будут объединяться. Т.е. если найденная ссылка окажется в блоке, чье id="footer", то она будет помещена к себе подобным ссылкам, классифицированным, как расположенные в подвале сайта. Если ссылка помещена в элементе любого типа с именем "comment-37268", то она дополнит линки из комментариев.
Вторым уровнем обработки информации о ссылках из комментариев может стать исследование DOM на наличие других внешних ссылок со страницы, и подсчет их общего количества. Чем их больше, тем выше вероятность того, что комментарии на этом сайте не модерируются.
Если страница не открывается, или ссылка с нее исчезла, то она будет отнесена к мертвым.
Кроме того, мы можем выполнить элементарную проверку на присутствие доменов в распространенных каталогах и наличие свойств, присущих web 2.0. Но в данном исследовании такому подробному анализу подверглась лишь часть доменов из каждой группы. И еще одно замечание: чем больше групп ссылок будет использовано, тем меньшей должна стать группа «неизвестно».
После проведенной работы и исключения мертвых ссылок, мы видим, как распределяются оставшиеся:
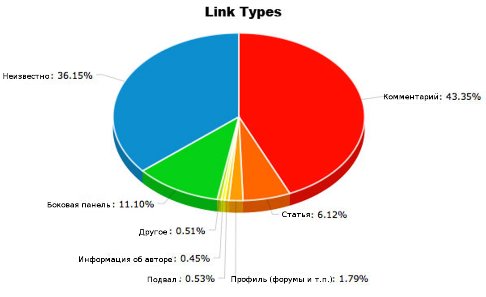
Теперь мы можем лучше понять, каким образом сайт получил высокое ранжирование. Комментарии в блогах, продвижение статьями и ссылки в боковых панелях играют определяющую роль в ранжировании ресурса. Судя по всему, этот сайт обязан своему положению в выдаче так называемому «link dropping» – захвату управления независимым сайтом и размещением на его страницах ссылок без какого бы то ни было модерирования или рецензирования.
Итак, мы смогли автоматически идентифицировать происхождение около 65% «живых» ссылок. Но имеется и группа ссылок, тип которых определить не удалось. Часть из них подверглась «ручному» анализу. И в большинстве случаев обнаруживается что-то подобное:

Просматривая страницы, с которых ведет основная масса неклассифицированных ссылок, становится ясно, что они сгенерированы компьютером. Эти тексты не предназначены для чтения людьми, но напичканы соответствующими ссылками. Подобная стратегия наращивания ссылочной массы считается абсолютно нежизнеспособной.
Обнаружена также масса ссылок с сайтов, посвященных самым разным темам. Новые публикации на этих сайтах появляются одна за другой, и каждая из них имеет ссылку с тем или иным целевым анкором (соответствующим наиболее прибыльным нишам).
Этот тип статей своим появлением обязан одной из наиболее эффективных в настоящее время стратегий воздействия на ссылочное ранжирование – использование сетки личных блогов. Теперь важно убедиться в том, что это действительно сетка. Сделать это можно с помощью размещения в ней собственных постов.
Идентифицируем частные блоги
Раскрыть тщательно созданную сеть личных блогов практически невозможно. Она выглядит как набор совершенно независимых сайтов, не связанных перелинковкой, и не имеющих ничего общего в коде. Если все сделано, как положено, то и IP адреса у них разные. Отличаются они по идентификатору Google AdSense и аккаунту в Google Analytics. Такую сеть нельзя раскрыть на основании содержимого страниц.
Настоящую сетку сателлитов (которую владелец использует для улучшения ранжирования основного сайта) практически невозможно раскрыть. В то же время сеть, вступить в которую можно на платной основе (такую как Build My Rank, Authority Link Network, Linkvana, или High PR Society), вычислить можно, но это потребует определенных затрат.
Одним из способов определения доменов из этой сети является формирование контента с общими уникальными фразами (или ссылками на домены-приманки). После того, как этот контент будет опубликован и проиндексирован, надо помучить Google на предмет страниц, содержащих заданные нами уникальные фразы (или ссылки на сайты-приманки). В результате мы получим список адресов, где опубликован наш контент. Добавим собранные домены в наш список для проверки.
Воспользовавшись ссылками, разделенными на группы, мы можем подготовить списки ресурсов, в которых используются одинаковые тактические подходы, для того, чтобы повторить их. Выполнение этой работы можно смело отдать на аутсорсинг. Отправим список блогов для комментирования фрилансерам, чтобы они расставляли ссылки. Если набраться мужества, то работу можно автоматизировать с помощью Scrapebox – это зависит от моральных устоев каждого и его готовности идти на риск.
То же самое можно сделать и с каталогами – это ссылки, которые можно получить с помощью грубого натиска, с минимальными материальными затратами.
Ссылки в боковых панелях, подвалах и списках ресурсов, скорее всего, оплачены, а частично получены из сети персональных блогов (к счастью, с помощью доменных имен мы смогли идентифицировать их), или, возможно, они попали в настоящие списки ресурсов. Для того чтобы связаться с вебмастерами и узнать условия размещения ссылок в этих местах, не надо иметь особых талантов. Данную работу можно поручить даже новичкам.
Если домены соответствуют обнаруженной сетке персональных блогов, то мы можем направить в нее собственные посты.
Важные предупреждения!
Будьте осторожны, копируя эту стратегию. Сайт, который использовался в данном анализе, уже забанен Google (автор не стал бы публиковать эту статью, если бы он все еще присутствовал в выдаче). Судя по всему, сделано это было вручную, так как сайт стабильно сохранял свои позиции в топе выдачи на протяжении трех месяцев (и это в век алгоритма Panda). Google не может позволить, чтобы подобные низкокачественные сайты находились в выдаче выше порталов брендов-миллиардеров, да еще по таким заметным запросам. Поэтому команда поисковика предприняла корректирующие действия для того, чтобы SERP по этим запросам в большей степени отвечал потребностям пользователей.
Может быть, они не применили санкций на уровне домена, а престали учитывать ссылки с тех сайтов, которые ссылались на AutoInsuranceQuotesEasy.com. А это значит, что если кто-то захочет в точности повторить данную стратегию, то он тоже окажется за бортом. Взвешивайте все возможные риски и выгоды, и никогда не поступайте так с сайтами клиентов, не получив их согласия (в письменной форме), в котором они подтверждают, что знают о риске потерять имеющиеся позиции.
Вместо заключения
Собирая информацию о сайте ходе расследования, автор разработал средство, описанное в разделе о семантической разметке. Теперь для анализа ссылок вы можете воспользоваться проектом Link Detective. Информация о его обновлении доступна в Twitter'е – @eppievojt, а также на веб-сайте – eppie.net.